Building a Quality Estimation Benchmark: The impact of relying on AI judges
What happens when you let AI judge AI? A pioneer benchmark for quality estimation in machine translation.
Machine translation has transformed localization workflows, with modern MT systems able to correctly translate 60-80% of content on the first pass. But here's the catch: someone still needs to review everything to find that 20-40% of errors. For enterprise organizations managing localization tasks at scale, this creates a significant bottleneck and expense.
Quality Estimation (QE) is a method of using models to predict the quality of a machine translation output without human judgment. With a QE setup, the system serves as an AI judge to score each translation, and only segments that fall below your threshold get sent for human review. The potential impact is substantial: drastically reduce review workload, increase linguist productivity, and cut costs.
Despite these advantages, QE adoption remains limited across the industry. The reason? Risk. When you rely on an AI judge to determine which translations go live without human review, you need answers to critical questions:
- Can you trust your chosen system?
- Which QE system should you select?
- What's the real-world impact on quality and efficiency?
A Collaborative Benchmark Built on Real Translation Projects
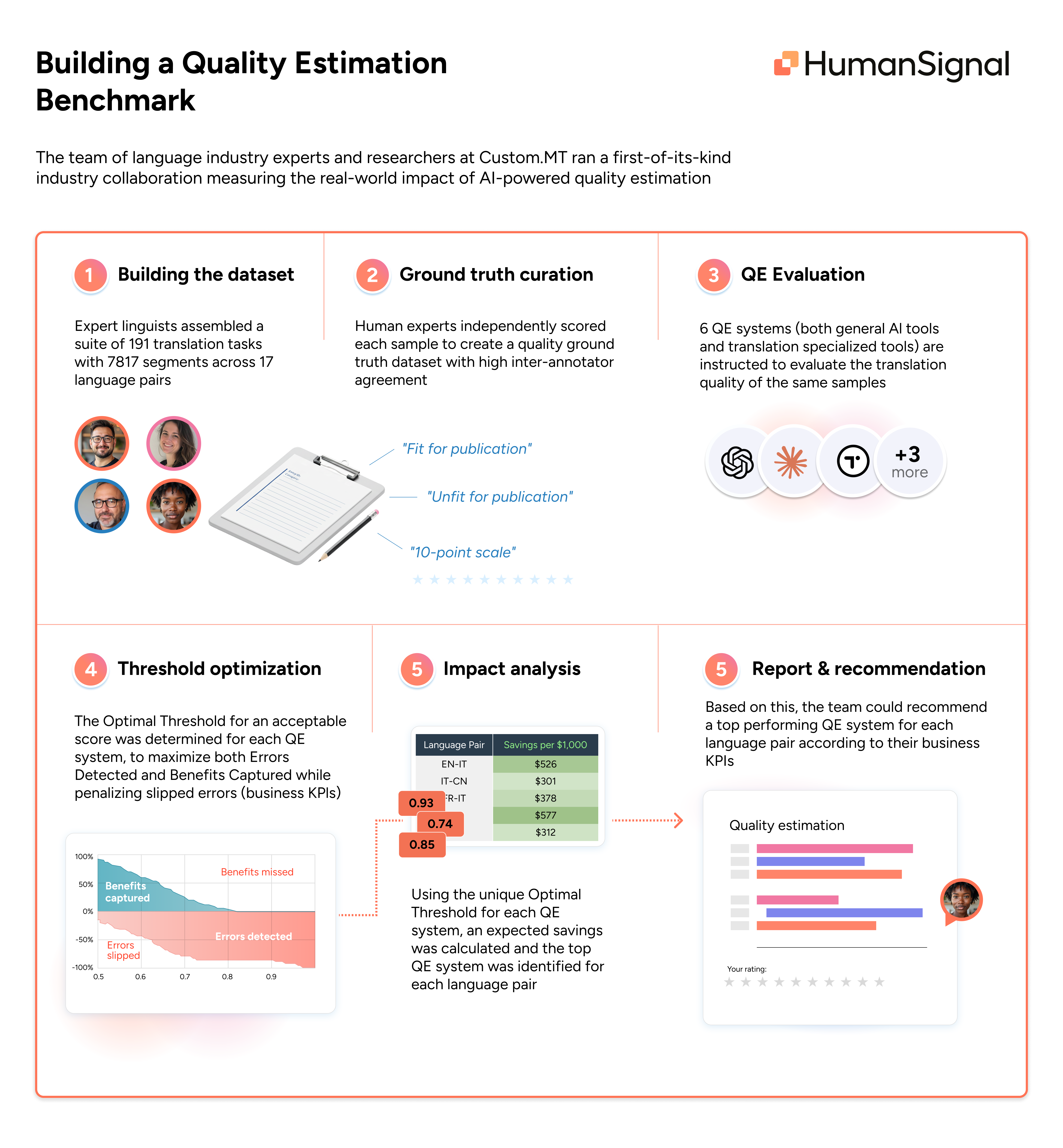
With this challenge in sight, the team of language industry experts and researchers at Custom.MT ran a first-of-its-kind industry collaboration measuring the real-world impact of AI-powered quality estimation. Equipped with Label Studio Enterprise, they were able to scale this benchmark to include:
- 7817 translation segments
- 17 language pairs
- 191 distinct translation tasks
- 6 QE systems a.k.a AI judges (4 specialized MT platforms: TAUS, Widn.AI, Pangeanic, ModernMT; 2 general-purpose AI assistants: GPT 4.1, Claude Sonnet 4)
- Expert linguist baseline for ground truth
The data came from live translation projects spanning multiple domains, provided by 16 global enterprise organizations. This ensured the benchmark reflects real-world complexity and diversity.
Methodology: Measuring What Matters
Expert-Curated Ground Truth
The team used Label Studio Enterprise to set up a rigorous evaluation process to produce a high quality ground truth dataset that would serve as a gold standard to assess the QE systems.
Two professional linguists independently scored each machine translation task to determine whether each segment was "Fit" or "Unfit" for publication. This included a custom 10-point scale (from "1 - Unintelligible (Critical Failure)" to "10 - Flawless").
Establishing inter-annotator agreement was crucial. These tasks were challenging enough that even two experts agreed only 71.9% of the time, highlighting the genuine difficulty of translation quality assessment.

The QE evaluation interface used in Label Studio Enterprise
AI Judge Evaluation
After establishing ground truth references, the same machine translation tasks were then run through six different QE systems using standardized prompts and instructions. Each QE system provided quality scores that could be compared directly against the expert-provided scores.
(Notably, human linguists aligned better with each other than the QE systems, indicating higher reliability and quality of the human-annotated data. Linguist 1 and Linguist 2 had an average agreement of 71.5%, whereas agreement between Linguist 1 and each of the QE systems ranged between 45.2% - 57.9%.)
Equipped with the ground truth dataset and 6 sets of AI responses, the team then assessed the real-world impact of using AI judgement had they been used in a production workflow. For each AI judge, they measured six business KPIs:
- Errors Detected (Recall Unfit): % of bad segments correctly caught by QE (Impact: Risk mitigated)
- Benefits Captured (Recall Fit): % of good segments correctly accepted by QE (Impact: Human review time saved)
- Precision Fit: % of segments QE accepted that were actually good (Impact: Published translations are of high quality)
- Precision Unfit: % of segments QE flagged as unfit that were actually bad (Impact: Minimize time wasted with human review)
- F1 Score: a balance of precision and recall
- Accuracy: overall percentage of segments classified correctly
Threshold Optimization and Impact Analysis
Since the QE systems provided continuous scores (from 1-10) but organizations need binary decisions (ie. review or publish?), they needed to set a threshold. Without proper calibration, a static threshold sends too many unnecessary segments for review, undermining any efficiency gains. The challenge is finding the sweet spot where you:
- Catch enough errors to protect quality (maximize "Errors Detected")
- Save enough review time to justify the investment (maximize "Benefits Captured")
- Maintain confidence that passed segments are truly publication-ready
The team assessed multiple approaches, ultimately settling on a custom weighted risk/reward score, weighing risk (errors detected or slipped) more heavily than reward (benefits captured). Using this custom score, the team identified an Optimal Threshold for each of the 6 QE systems, and demonstrated significant performance lift when thresholds are carefully selected. For more information on calibrating the scoring function and approach, see Custom.MT’s full report here.
Key Findings
With the optimal thresholds, the team calculated expected savings, captured benefits, and errors detected for each language pair and QE system.
| Model | Optimal Threshold | Benefits _Captured | Errors_ Detected | Errors Slipped | Precision_Fit | Precision_Unfit | Accuracy | Custom_MT Score (weighted F1-based) |
| ModernMT | 0.81 | 31.1% | 86.2% | 13.8% | 79.2% | 36.7% | 48.5% | 63.9 |
| Widn.AI | 0.85 | 35.2% | 86.3% | 13.7% | 74.6% | 38.7% | 56.0% | 67.7 |
| TAUS | 0.87 | 32.4% | 82.4% | 17.6% | 79.3% | 35.2% | 53.0% | 64.3 |
| OpenAI GPT 4.1 | 0.88 | 52.2% | 74.1% | 25.9% | 78.9% | 45.9% | 59.6% | 64.4 |
| Claude Sonnet 4 | 0.89 | 27.8% | 88.3% | 11.7% | 69.4% | 38.0% | 50.6% | 63.9 |
| Pangeanic | 0.73 | 22.4% | 86.1% | 13.9% | 69.9% | 33.8% | 45.2% | 60.9 |
Results from Custom.MT
Some notable findings:
- No single system was the ‘best’. Models that capture more benefits may also let more errors through. For example, OpenAI and Widn.AI capture the highest measurable benefits (35–52%), but Claude, TAUS, and ModernMT maintain higher error-catch rates (82-88%)
- QE threshold tuning has a major impact on performance. Even a modest QE model can perform competitively when thresholds are carefully adjusted.
Takeaways:
- Benchmark QE systems against your specific language combinations, content types, and domain data. Don’t rely on generic performance claims
- Spending effort on threshold optimization can mean the difference between marginal gains and impactful cost savings
- With expert linguist inter-annotator agreement at 71.9% (reflecting genuine task difficulty), the gap reminds us that QE systems are valuable assistive tools for scale, not replacements for human expertise on high-stakes content
- Certain language combinations consistently challenge all QE systems. These situations may call for more human intervention
Building Practical AI Evaluation Workflows
If you're evaluating AI systems for any high-stakes workflow, this benchmark reveals key best practices in building a practical evaluation framework.
- You need a benchmark dataset built by subject matter experts in your domain, containing tasks representative of your context and balanced across both good and bad scenarios (in this case, it was good and bad translation segments)
- How you evaluate (e.g. the scoring function) should reflect your actual business KPIs (not generic accuracy metrics)
- Break down tasks by capability (in this case, specific language pairs and specific topics) to help pinpoint weaknesses in your AI system
The finding that no single QE system won across all language combinations reinforces that AI performance is fundamentally context-dependent. Generic vendor benchmarks won't predict how a system performs on your content, with your quality standards, in your workflow.
For organizations serious about AI adoption, the upfront investment in strategic, interpretable evaluation is the only way to make informed decisions about which systems to trust and how to deploy them responsibly.
From off-the-shelf assessments to production-ready custom benchmarks, we've helped teams navigate this journey. Reach out to our team when you’re ready to design an evaluation strategy that scales.
—
A special thanks to Custom.MT and the localization community for partnering with us on this benchmark. We’re grateful for these humans that constantly raise the AI quality bar higher.
Related Content
-
Why Benchmarks Matter for Evaluating LLMs (and Why Most Miss the Mark)
Custom AI benchmarks play a crucial role in the success and scalability of AI systems by providing a standardized approach to running AI evaluations.

Sheree Zhang
July 8, 2025
-

How to Build AI Benchmarks that Evolve with your Models
Designing effective LLM benchmarks means going beyond static tests, this guide walks through scoring methods, strategy evolution, and how to evaluate models as they scale.

Micaela Kaplan
July 21, 2025
-

How Legalbenchmarks.ai Built a Domain-Specific AI Benchmark
See how Legalbenchmarks.ai built a custom contract-drafting AI benchmark using an SME-first, human-in-the-loop framework with rubric-based scoring and LLM judges.
Sheree Zhang
September 15, 2025