Fine-Tuning LLMs

Fine-tuning plays a pivotal role in harnessing LLMs for specific tasks. It serves as the bridge connecting a generic pre-trained model to the intricacies of a domain. We can adapt the model's language understanding, context, and output through fine-tuning to align with our task. This process significantly enhances the applicability and performance of LLMs, making them indispensable tools for various AI applications.
By exploring the process of fine-tuning and understanding its importance in LLMs, you will gain the knowledge and practical skills needed to optimize LLMs for your specific tasks, ultimately advancing the boundaries of what is possible in the realm of artificial intelligence and machine learning.
This article is an excerpt from Human Signal’s free ebook -The Essential Guide to LLM Fine-Tuning. You can download the book here if you want to read more about LLM Fine-Tuning.
The Fine-Tuning Process
Fine-tuning is a transformative process that allows us to optimize pre-trained models for specific tasks, resulting in improved performance and enhanced efficiency. This section will delve into the intricacies of the fine-tuning process, breaking it down into its key components and providing a comprehensive explanation of each step.
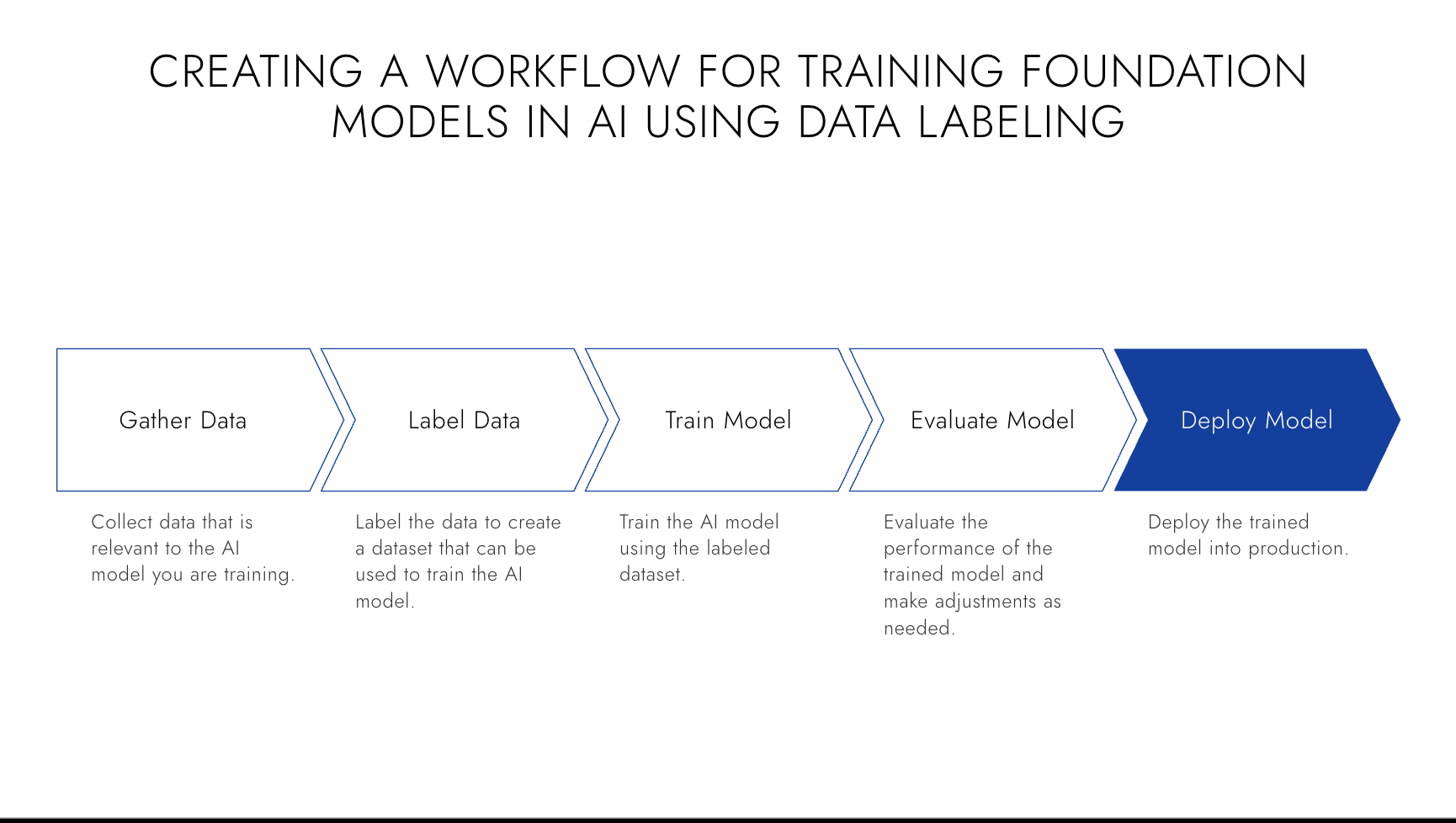
The Objective of Fine-Tuning
At its core, fine-tuning aims to tailor a pre-trained model to handle specific tasks more effectively. While pre-trained models have a remarkable ability to understand language, they lack task-specific knowledge and context. They are fine-tuning to bridge this gap by adjusting the model's parameters and exposing it to task-specific data. By doing so, we enable the model to learn the intricacies of the target task and make more accurate predictions or generate more relevant outputs.
Data Preparation
Data preparation plays a crucial role in the fine-tuning process. The quality and relevance of the data used for fine-tuning directly impact the model's performance. Collecting or creating a dataset representative of the target task is essential and contains sufficient examples for the model to learn from. The dataset should cover various scenarios and be balanced to avoid biases. Preprocessing steps such as cleaning, tokenization, and normalization may also be necessary to ensure the data is in a format suitable for fine-tuning.
Pre-labeling Data with ChatGPT
Jimmy Whitaker, Data Scientist-in-Residence @HumanSignal, provides a great productivity tip for using AI to train AI at Towards Data Science - Bootstrapping Labels with GPT-4: A cost-effective approach to data labeling.
A cost-effective strategy for data labeling can be implemented using advanced language models like GPT-4. This approach involves using the model's ability to understand the context and generate human-like text to pre-label data, which can significantly reduce the time and cost associated with manual data labeling.
The process starts by creating specific prompts that guide the model to produce the desired output format. For instance, in sentiment analysis, a prompt can be structured to guide the model toward classifying the sentiment of a given text as positive, negative, or neutral. The model's predictions can then be generated using an API.
Once the data is pre-labeled, it can be imported into a data labeling tool for review. This approach makes the review process more efficient as human reviewers only need to validate or correct the model-generated labels rather than creating them from scratch.
However, it's important to note that while this method can significantly reduce the manual work required for data labeling, care should be taken not to send sensitive or private data to these APIs to avoid potential data exposure.
Model Adjustment
Once the data is prepared, the pre-trained model is adjusted to align with the target task. This adjustment involves modifying the model's parameters and architecture to capture the specific nuances and requirements of the task. The adjustment may include freezing certain model layers to preserve the learned representations while fine-tuning the later layers. Alternatively, the entire model can be fine-tuned, depending on the complexity and similarity of the task to the pre-training objectives.
Training and Optimization
With the model adjusted, the fine-tuning process involves training the model on the task-specific dataset. During training, the model's parameters are updated iteratively using techniques such as backpropagation and gradient descent to minimize the loss function and improve the model's performance on the target task. It is crucial to carefully monitor the training process, adjust hyperparameters, and apply regularization techniques to prevent overfitting or underfitting of the model.
Evaluation and Iteration
After fine-tuning, evaluating the model's performance on a separate validation dataset is essential. This evaluation provides insights into the model's generalization capabilities and ability to perform well on unseen data. Based on the evaluation results, further iterations of fine-tuning may be required, involving adjustments to the data, model architecture, or hyperparameters to improve the model's performance.
Following these steps and iteratively fine-tuning the model can transform a generic pre-trained model into a powerful tool that excels at specific tasks. Fine-tuning opens up a world of possibilities, allowing us to leverage the extensive knowledge and language understanding of pre-trained models while tailoring them to our unique requirements. In the next section, we will dive deeper into the nuances of fine-tuning and explore specific techniques and best practices to achieve optimal results.
Fine-Tuning Approaches and Methodologies
Fine-tuning approaches and methodologies provide diverse techniques to optimize pre-trained models for specific tasks. In this section, we will explore several effective methods that can be employed during the fine-tuning process to achieve exceptional results. Understanding and leveraging these methodologies allows you to tailor the model to your requirements while maximizing its performance and efficiency.
- Few-Shot Learning - Few-shot learning is a fine-tuning methodology that addresses situations where data is scarce or expensive. It allows models to learn from a limited number of examples, enabling them to adapt quickly to new tasks with minimal data. By leveraging transferable knowledge and generalization abilities, few-shot learning is an ideal approach for tasks that require rapid adaptation and effective performance in resource-constrained scenarios.
- Transfer Learning - Transfer learning is a widely used methodology in fine-tuning, where the knowledge gained from one task is utilized to solve a different but related task. This approach reduces the need for extensive data and computational power, as the model can leverage the pre-existing understanding of language and patterns. Transfer learning is particularly effective when the new task shares similarities with the task the model was initially trained on, allowing for efficient adaptation and improved performance.
- Sequential Fine-Tuning - Sequential fine-tuning involves training a model on multiple related tasks one after the other. This approach enables the model to understand nuanced language patterns across various tasks, enhancing performance and adaptability. Sequential fine-tuning is advantageous when there are multiple related tasks that the model needs to learn, as it allows for accumulating knowledge and fine-tuning specific aspects of language understanding.
- Task-Specific Fine-Tuning - Task-specific fine-tuning aims at adapting the pre-trained model to excel at a particular task. Although this approach requires more data and time, it can lead to high performance on the task. Task-specific fine-tuning focuses on optimizing the model's parameters and architecture to enhance its capabilities in a targeted manner. This methodology is particularly valuable when a specific task's performance is paramount.
- Multi-Task Learning - Multi-task learning involves simultaneously training a model on multiple tasks. This approach improves generalization and performance by leveraging shared representations across different tasks. The model learns to capture common features and patterns, leading to a more comprehensive language understanding. Multi-task learning is most effective when the tasks are related, and the shared knowledge enhances the model's learning and adaptability.
- Adapter Training - Adapter training is a methodology that enables fine-tuning a specific task without disrupting the original model's performance on other tasks. This approach involves training lightweight modules that can be integrated into the pre-trained model, allowing for targeted adjustments. Adapter training is a great option when the need to preserve the original performance of the pre-trained model is high, providing flexibility and efficiency in adapting to task-specific requirements.
You can tailor pre-trained models to address specific tasks effectively by exploring and utilizing these fine-tuning approaches and methodologies. Each method offers unique benefits and considerations, allowing you to optimize performance, efficiency, and adaptability based on your specific requirements. In the next section, we will dive deeper into the implementation and practical aspects of fine-tuning, providing you with guidelines and best practices to achieve optimal results.
How Label Studio Helps With LLM Fine-Tuning
Label Studio is a versatile data annotation tool that can significantly aid in preparing data used in the fine-tuning process of Large Language Models (LLMs). Here are a few of the ways how Label Studio can improve your data labeling efficiency:
- Data Annotation - Fine-tuning LLMs requires task-specific data, often in the form of annotated examples. Label Studio allows you to create custom annotation tasks, enabling you to label data in the most relevant way to your specific task. This could involve text classification, named entity recognition, or semantic text similarity.
- Multi-format Support - Label Studio supports various data types, including text, images, audio, and video. This versatility is beneficial when working with LLMs, as these models are increasingly used for multi-modal tasks involving different types of data.
- Collaborative Annotation - Label Studio Enterprise supports collaborative annotation, making it much easier for multiple annotators to work on the same dataset. This feature can be useful when preparing large datasets for fine-tuning LLMs, as it provides for the distribution of the workload and can help ensure consistency in the annotations.
- Quality Control - Label Studio Enterprise provides features for quality control, such as annotation history and disagreement analysis. These features help ensure the quality of the annotations, which is crucial for the success of the fine-tuning process.
- Integration with Machine Learning Models - Label Studio can be integrated with machine learning models, enabling active learning workflows. This means you can use your LLM to pre-annotate data, which human annotators can correct. This approach can make the annotation process more efficient and improve fine-tuning results.
Label Studio can provide the tools to prepare high-quality, task-specific datasets for fine-tuning LLMs. By facilitating efficient and accurate data annotation, Label Studio can help you unlock the full potential of LLMs.
Related Content
-

Five Large Language Models You Can Fine-Tune Today
Hundreds of thousands of open source LLMs are available, and choosing one is not easy. However, there are a small number of highly capable models that we think are excellent choices today.

Nate Kartchner
July 6, 2023
-

How to fine-tune BERT to classify your Slack chats without coding

Nikolai Liubimov
February 18, 2020
-
Introducing Label Studio 1.8.0 — Optimized for fine-tuning LLMs and Foundation Models
We're excited to announce the latest version of Label Studio, specifically designed to help create datasets for fine-tuning Large Language Models (LLM) like ChatGPT or LLaMA.

Michael Malyuk
June 6, 2023