Five Large Language Models You Can Fine-Tune Today

The landscape of artificial intelligence is constantly shifting, with Large Language Models (LLMs) standing at the forefront of this exciting evolution. As we navigate through 2023, we're witnessing a proliferation of foundation models, each bringing unique capabilities to the table.Whether you're an AI enthusiast, a seasoned researcher, or a curious developer, this journey promises to offer valuable insights into the cutting-edge of language processing technology.
As of today (June 2023), several cutting-edge LLMs have emerged. These include Alpaca, Falcon, Flan UL-2, ChatGPT, and ChatGLM. Falcon, like many models that come in multiple versions like falcon-40b and falcon-7b, the number followed by “b” indicates the number of parameters, is known for its impressive performance in instruction following tasks.
Alpaca and Flan UL-2 are other notable models that have made their mark in the AI community. ChatGLM, a model designed for generating conversational responses, has also gained significant attention because of its multilingual capabilities, specifically in Chinese and English.
In more technical terms, a parameter is a component of a machine learning model that the model learns from its training data. For example, in a neural network (which is the type of model that LLMs are based on), parameters include the weights and biases for each node in the network. These weights and biases determine how each node processes its input, and adjusting these values allows the model to learn patterns in the data.A model's number of parameters is often used to measure its size or complexity. A model with more parameters can represent more complex patterns. Still, it also requires more data to train effectively and is more prone to overfitting (i.e., memorizing the training data instead of learning to generalize from it).
In more technical terms, a parameter is a component of a machine learning model that the model learns from its training data. For example, in a neural network (which is the type of model that LLMs are based on), parameters include the weights and biases for each node in the network. These weights and biases determine how each node processes its input, and adjusting these values allows the model to learn patterns in the data.
The number of parameters in a Large Language Model (LLM) significantly impacts the fine-tuning process in several ways:
- Model Complexity and Learning Capacity - A model with more parameters can represent more complex patterns and has a higher learning capacity. This means it can potentially achieve better performance when fine-tuned on a specific task, as it can learn more nuanced representations of the data. However, it also means that the model may require more fine-tuning data to avoid overfitting.
- Computational Resources - Models with more parameters require more computational resources (memory and processing power) for fine-tuning. This can make the fine-tuning process more challenging and time-consuming, particularly for those without access to high-end hardware or the capital for hosting services.
- Risk of Overfitting - A model with more parameters can learn more complex patterns, but it also has a higher risk of overfitting, especially if the fine-tuning data is small. Overfitting occurs when the model learns the training data too well, including its noise and outliers, and performs poorly on unseen data.
- Transfer Learning - Models with more parameters often perform better at transfer learning, where the model is first trained on a large dataset (pre-training) and then fine-tuned on a smaller, task-specific dataset. The large number of parameters allows the model to learn a wide range of language patterns during pre-training, which can then be fine-tuned for specific tasks.
In summary, while a higher number of parameters can potentially improve the performance of a fine-tuned model, it also presents challenges in terms of computational resources and the risk of overfitting. Therefore, it's important to balance these factors when choosing a model for fine-tuning.
Hosted and Downloadable Large Language Models
Training these LLMs can be done in two primary ways: using hosted models or downloading the models for local training. Hosted models are provided as a service just as cloud services are offered for compute or storage. This option is convenient as it abstracts away the complexities of setting up the training infrastructure. However, it may come with usage costs and potential limitations on data privacy and model customization.
On the other hand, downloading the models allows for greater flexibility and control. You can fine-tune the models on your own hardware, allowing for more customization and better control over data privacy. However, this option requires more technical expertise and computational resources. Hundreds of thousands of open source LLMs are available, and choosing one is not easy. However, there are a small number of highly capable models that we think are excellent choices today.
Stanford Alpaca
In March 2023, the Alpaca model was introduced. It is a fine-tuned version of Meta's LLaMA 7B model, and it has been trained on 52,000 instruction-following demonstrations.
One of the main objectives of the Alpaca model is to facilitate engagement with the academic community by providing an open-source alternative to OpenAI's GPT-3.5 (text-DaVinci-003) models. Alpaca is a fine-tuned version of the LLaMA-7B LLM. The fine-tuning process is based on self-instruction, in which instruction-following data is collected from a higher-performing LLM and used for supervised fine-tuning. The entire fine-tuning process of Alpaca cost the original only $600 (including data collection and fine-tuning).
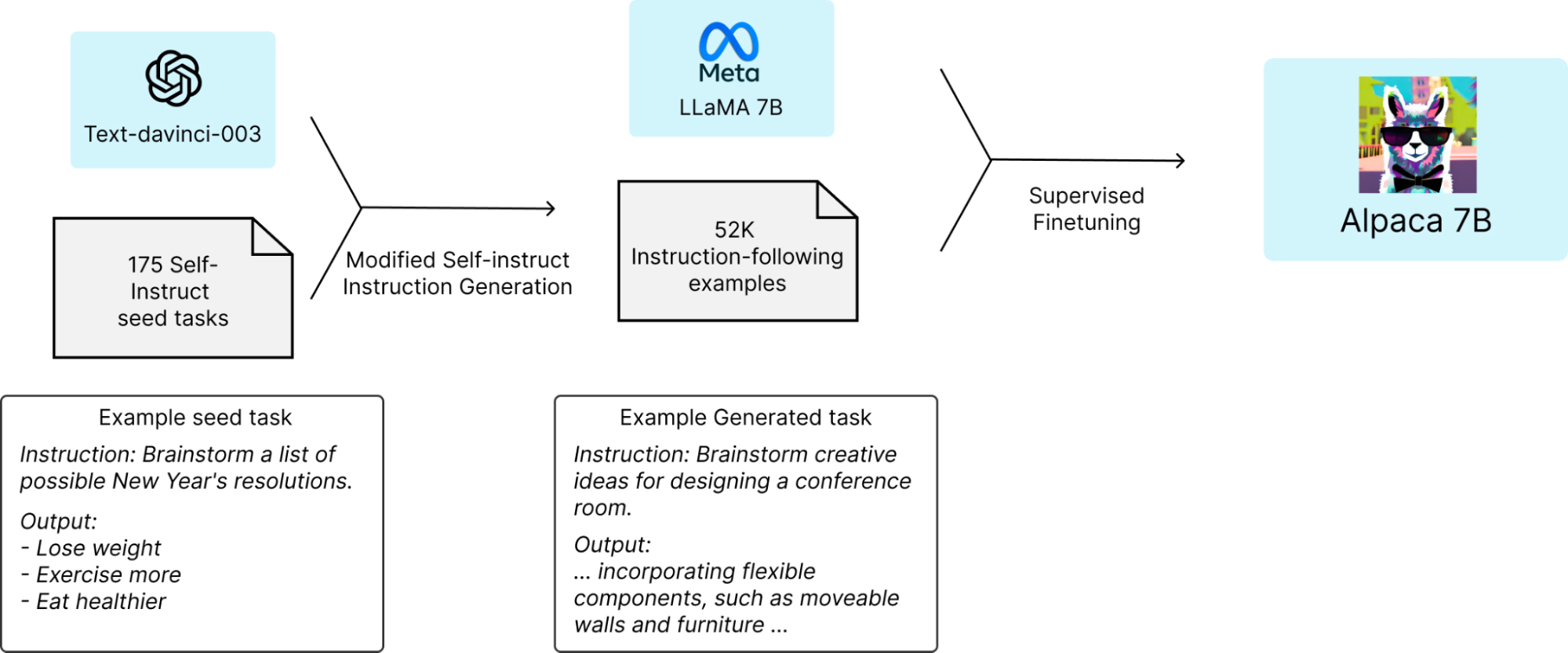
Source: Stanford University HAI
Alpaca is the recommended choice for researchers and individuals working on research or personal projects due to its licensing terms that explicitly prohibit commercial use, this model can also be fine-tuned on consumer-grade GPUs, and it is even capable of running (albeit slowly) on a Raspberry Pi. However, when combined with techniques such as LoRA or Low-Rank Adaptation of Large Language Models (LoRA). LoRA is a training method that accelerates the training of large models while consuming less memory It works by adding pairs of rank-decomposition weight matrices (also known as update matrices) to existing weights and only training these newly added weights. This approach has several advantages:
- Preventing Catastrophic Forgetting - The model is not as prone to catastrophic forgetting since the pre-trained weights are kept frozen.
- Efficient Parameterization - Rank-decomposition matrices have significantly fewer parameters than the original model, meaning trained LoRA weights are easily portable.
- Memory Efficiency - The greater memory efficiency allows you to run fine-tuning on consumer GPUs like the Tesla T4, RTX 3080, or even the RTX 2080 Ti
LoRA matrices are generally added to the attention layers of the original model. However, LoRA is not only limited to attention layers. The authors found that amending the attention layers of a language model is sufficient to obtain good downstream performance with great efficiency.
The use of LoRA has been demonstrated in applications such as text-to-image generation and DreamBooth, a technique for personalizing a text-to-image model to generate photorealistic images of a subject in different contexts, given a few images of the subject.
In summary, Alpaca presents an exciting opportunity for the academic community to access a powerful and cost-effective language model, enabling research and exploration in various domains. Its open-source nature and compatibility with different hardware configurations make it a versatile tool for advancing natural language processing capabilities.
ChatGLM
ChatGLM, also known as QAGLM in its alpha internal test version, is a chatbot specifically designed for Chinese users. It is based on a 100 billion parameter Chinese-English language model and has been fine-tuned to provide question-and-answer and conversation features. The model, developed by the Big Model Center at Stanford University, has been released for internal testing and is expected to expand over time.
ChatGLM is built on the 100 billion base model GLM-130B and uses supervised fine-tuning and other methods to align with human intentions. It can process text in various languages, infer relevant relationships and logic between texts, and learn from users and environments to update and enhance its models and algorithms.
In addition to ChatGLM, researchers have also released the ChatGLM-6B model, a 6.2 billion-parameter Chinese-English bilingual discussion model. Due to its model quantization technology, this model can be deployed locally on consumer-grade graphics cards. It has been trained on about 1T identifiers of Chinese and English bilingual training and uses technologies like supervision and fine-tuning, feedback self-help, and human feedback reinforcement learning.
ChatGPT
Developed by OpenAI, ChatGPT is a text-only model with an impressive parameter count of 20 billion. While it is not open source, ChatGPT provides API access, offering a fully hosted solution for leveraging its language capabilities. It was first released in November 2022, and although GPT-4 generally outperforms it, ChatGPT still performs a wide range of text-based functions.
As of June 2023, fine-tuning is only available for the base models: davinci, curie, babbage, and ada. These original models do not have any instruction following training (like text-davinci-003 does, for example). You can also continue fine-tuning a fine-tuned model to add additional data without starting from scratch.
Access to basic (non-peak) ChatGPT functionality does not require a subscription, making it suitable for personal projects, experimentation, or low-demand applications. However, if you require general access even during peak times, a ChatGPT Plus subscription is required, providing a more reliable and unrestricted experience.
ChatGPT is the most powerful (and popular) API-based LLM that enables natural language conversations. With its rich set of features and frequent updates, it offers developers and users a versatile tool for various text-based tasks. Whether you need to experiment with natural language interactions or require a reliable solution for production use, ChatGPT's accessible options make it a compelling choice.
Falcon
Falcon is a cutting-edge platform that unleashes the full potential of advanced Language Models (LLMs) for various applications. Developed by a team of experts at TII, Falcon offers a seamless and user-friendly experience for leveraging the power of language processing technology.
With Falcon, you can access a suite of state-of-the-art LLMs meticulously trained and fine-tuned to deliver exceptional performance in various domains. These models have been carefully crafted to understand and generate human-like text, analyze complex linguistic patterns, and perform many language-based tasks with remarkable accuracy.
Falcon's user-friendly interface allows developers, researchers, and businesses to integrate LLMs into their applications effortlessly, empowering them to create intelligent and dynamic solutions. Whether you are working on conversational agents, content generation, sentiment analysis, or any other language-related task, Falcon provides the tools and resources to drive innovation and achieve outstanding results.
At Falcon, innovation and continuous improvement are at the core of our philosophy. Our dedicated team of experts constantly fine-tunes and enhances the LLMs to stay at the forefront of language processing advancements. We prioritize delivering high-quality models that are reliable, efficient, and capable of handling even the most demanding applications.
In addition to the exceptional LLMs, Falcon offers comprehensive documentation, tutorials, and support to ensure a smooth and successful integration into your projects. Our aim is to empower you with the tools and knowledge needed to unlock the true potential of language models and elevate the capabilities of your applications.
Whether you are a developer seeking to enhance the natural language understanding of your chatbot, a researcher exploring the depths of language processing, or a business needing advanced language analytics, Falcon is your gateway to harnessing the power of advanced Language Models.
Flan-UL2
With its impressive 20 billion parameters, Flan-UL2 is a remarkable encoder-decoder model with exceptional performance. Developed by Google and available for download from HuggingFace, Flan-UL2 is a souped-up version of the T5 model, enriched with the advancements of the Flan project. This model surpasses the performance of previous versions, specifically Flan-T5.
Flan-UL2 has an Apache-2.0 license, making it an excellent choice for self-hosted deployments or fine-tuning for commercial purposes. The model's detailed usage guidelines and training specifications have been released, providing transparency and flexibility for developers and researchers alike.
While Flan-UL2's 20 billion parameters offer unparalleled power, we understand that it may not be suitable for every scenario. In such cases, we recommend considering the previous iteration, Flan-T5, which is available in five different sizes. These different sizes allow you to choose the model variant that best aligns with your specific requirements, providing a more tailored and efficient solution.
In conclusion, Flan-UL2 is an exceptional choice for those seeking a self-hosted model or a model suitable for fine-tuning in commercial settings. Its impressive capabilities and the release of usage and training details offer many possibilities for leveraging this advanced language model. If the 20 billion parameters of Flan-UL2 are more than needed, the versatile Flan-T5 series presents a range of alternatives to better suit your specific needs.
Interested in learning more about fine-tuning LLMs? Download The Essential Guide to LLM Fine-Tuning.
Related Content
-

The 5 Metrics That Actually Move AI Into Production
A practical framework for turning AI metrics into clearer decisions about what to fix, ship, and scale.

Sheree Zhang
April 15, 2026
-

Scaling AI Data Quality: Best Practices for Onboarding and Evaluating Annotators
A practical workflow for onboarding and evaluating annotators with clear instructions, calibration, quality gates, reviewer feedback, and dashboards that keep labeling consistent as volume grows.

Alec Harris
March 12, 2026
-

How to Create a Prompt Generator with Label Studio and RLVR
In this article, you'll learn how to apply an RLVR-based score verifier and use an LLM as a prompt optimizer to enhance your prompts.

Label Studio Team
March 2, 2026