How to Build and Evaluate RAG Applications with Label Studio, OpenAI & Ragas
In this tutorial, we'll guide you through the process of setting up and using Label Studio in combination with Ragas (Retrieval-Augmented Generation Answer Scoring) and GPT-4 to build an optimized QA application. If you’d like to learn more about RAG and RAG evaluation, check out our post Key Considerations in Evaluating RAG-Based Systems.
To get you up and running quickly we’ve implemented an example for using RAG with Label Studio, which you can find in our label-studio-ml-backend repository.
Let's take a look!
Prerequisites
Before you begin, please ensure you have the following:
- Label Studio: Installed and ready to use.
- GPT-4 API Access: Access to OpenAI's GPT-4 API.
- Python 3.8+: Ensure Python is installed to run Label Studio.
Installation Instructions
If you haven't done so already, install Label Studio with the following command:
pip install label-studio
Ensure you have your API key for GPT-4 handy—you'll need it for the upcoming steps.
Step 1: Prepare your corpus
To build a RAG application, you'll need a corpus of documents that the system will use to answer questions. This can be any set of documents relevant to your domain.
Here’s how to get started:
- Collect documentation or other knowledge base resources: Gather all the documents you want to use as your knowledge base. These could be markdown files, PDFs, or any other format.
- Load documents to be labeled into Label Studio:
- Create a new project in Label Studio.
- Upload your documents to be labeled to the project. If your documents are in markdown format, filter them by .md to focus on the relevant files.
- Set up your labeling interface:
- Set up your project with a labeling interface. We provide one as an example for Ragas evaluation here, but you can feel free to customize it for your specific needs.
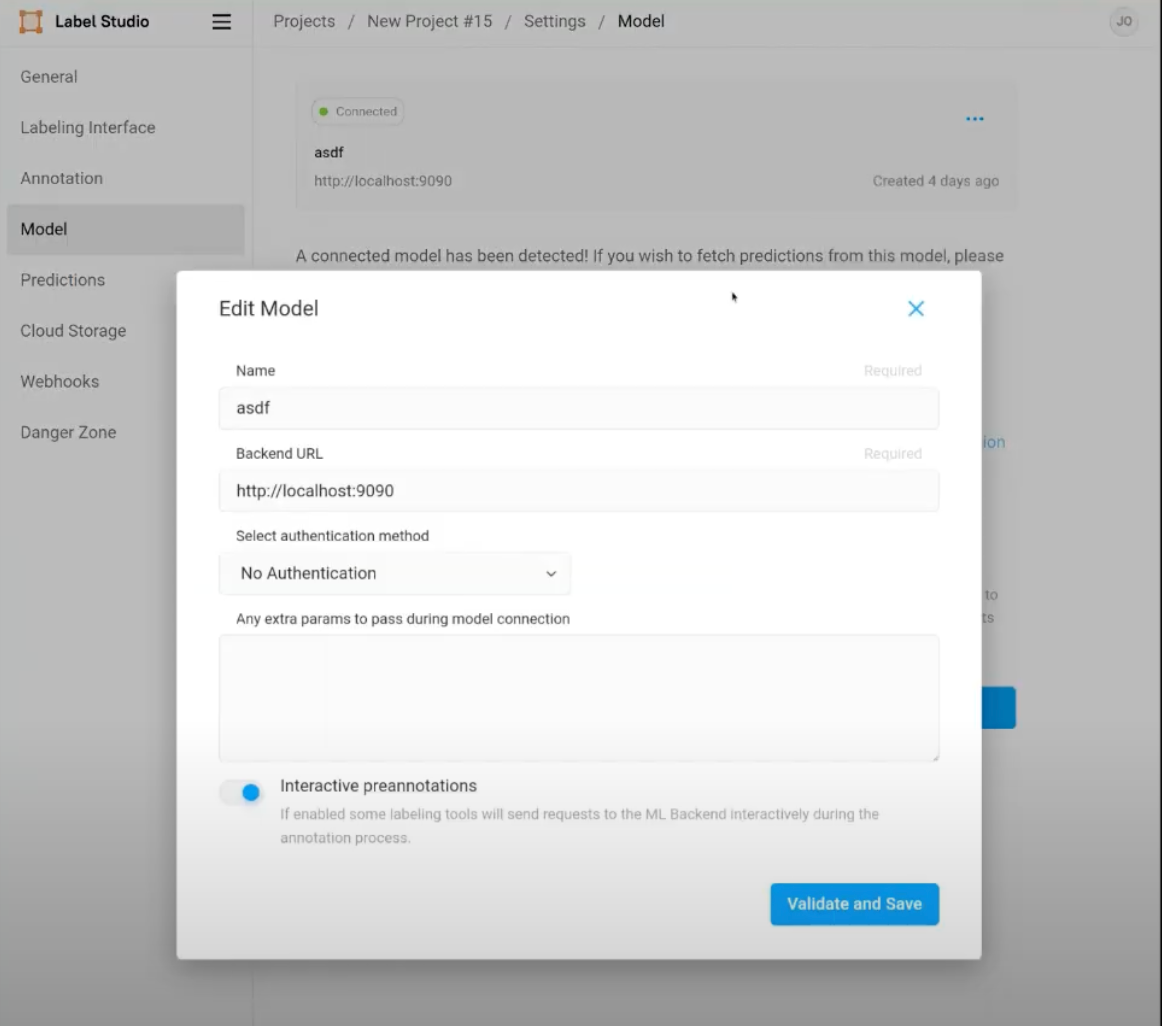
- Configure ML backend: Set up Label Studio to use an ML backend for processing. This backend will use GPT-4 to generate answers based on the context provided by your documents. We recommend starting with our example ml-backend integration, linked before the prerequisite steps.
- In the project settings, go to the Model tab.
- Attach your GPT-4 model to the project by providing your API key and setting up the model parameters, including the endpoint for GPT-4.
- Enable Interactive Preannotations. This feature lets you refine prompts dynamically as the system generates answers, ensuring more accurate responses.
Step 2: Create and configure your RAG application
First, you'll set up a RAG workflow. In Label Studio, configure your project to enable interactive pre-annotations. This is critical for refining prompts in real-time as the LLM generates answers.
Define a workflow where questions are passed to GPT-4 with context from your corpus. The context is generated by selecting relevant documents from the corpus, which will then be embedded and passed as input to GPT-4.
Next, use an embedding model (e.g., OpenAI’s embedding API) to convert your documents and questions into vectors. Implement a similarity search using a vector database to find the most relevant documents based on cosine similarity. Pass these relevant documents as context to GPT-4, along with the question.
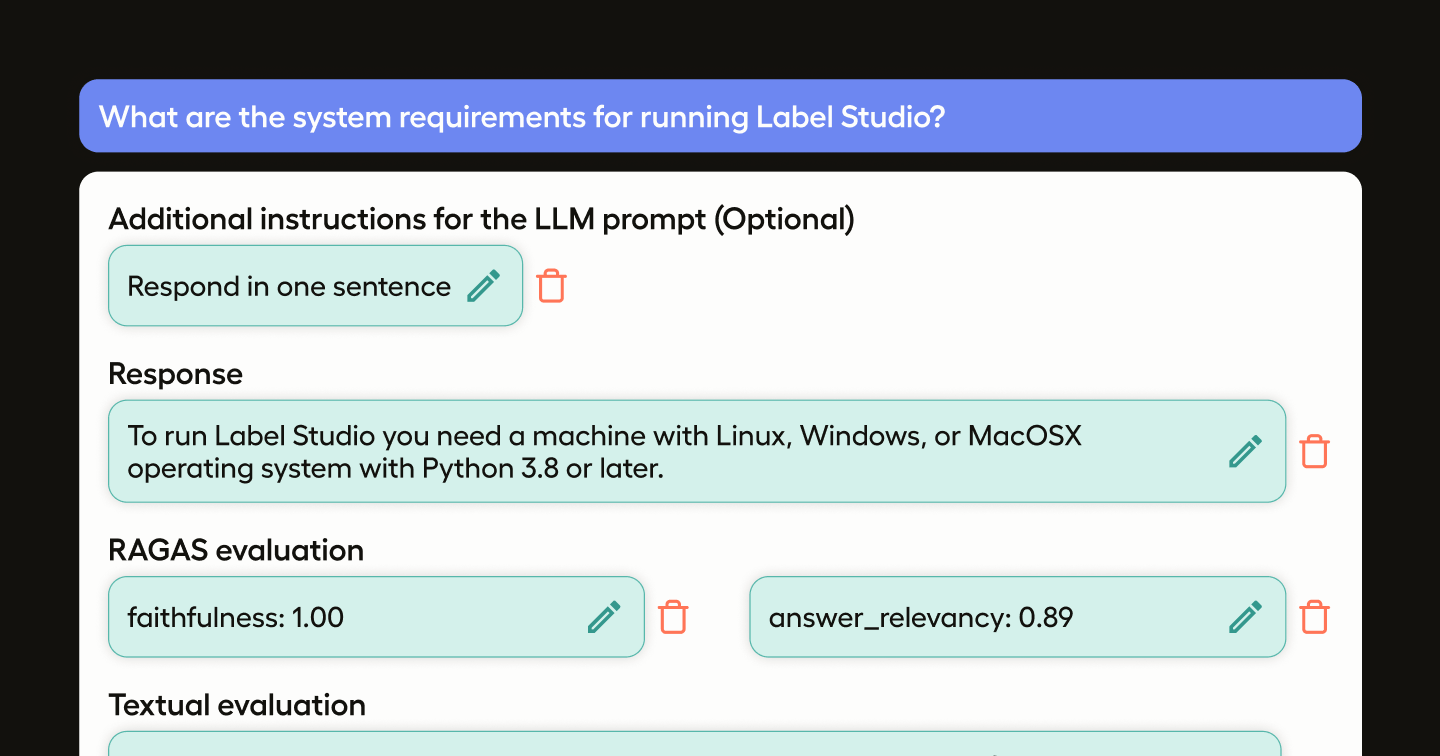
GPT-4 will then generate an answer based on the context provided. Review the answer within Label Studio. You can refine the prompt by adding specific instructions (e.g., "Include examples for macOS") to improve the output.
In our example repository, we implement the RAG system in line 32 of model.py, in the function iife_rag. There, we load the knowledge base documents, create a vector store to be the retriever for the knowledge base, and prompt our LLM with the knowledge from our knowledge base injected into the prompt. This gets used by our system when predictions are made, in line 256 of the _predict_single_task function. Note that our example is also set to auto-populate your Label Studio task page with the returned response, including the response from the LLM and the evaluations mentioned below, both textual and Ragas metrics based.
Step 3: Evaluate answers with Ragas and Textual Evidence.
Ensure your setup is configured to use Ragas metrics, which will evaluate answers against the source documents using metrics like Faithfulness and Answer Relevancy. If you’re using the example labeling config provided by the ReadMe.md in the linked repository, you’re good to go! We implement the Ragas evaluation in line 93 of model.py, in the function get_ragas_evaluation. We implement the textual evaluation in line 110 of model.py, in the function get_textual_evaluation.
Here's how to go about this:
Run evaluations
For each question, Ragas will automatically evaluate the answer, checking:
- Faithfulness: Consistency with the provided documents.
- Answer Relevancy: Relevance to the question asked.

Interpret Ragas metrics
Ragas provides scores between 0 and 1 (or 0-100 if scaled). Use these scores to identify where the generated answers might need improvement. Ragas also offers a textual evaluation to help pinpoint any issues, such as unsupported facts or irrelevant details.
Using Textual Evidence
Textual evidence allows us to “fact check” our LLM output by having another LLM point to where in the provided knowledge base the claims in the original answer can be found. While reviewing this is a manual process, it is a good follow up step to an answer that may have received low Ragas scores, or where you want to know why the LLM answered the way that it did.
Handle task evaluation in Label Studio
After generating an answer, Label Studio lets you review the sources used by the embedding model—crucial for verifying accuracy. If you’re dealing with multiple questions, consider disabling Ragas metrics during batch processing to speed up evaluations.
Step 4: Iterative improvement
Based on Ragas evaluations, you'll next refine your prompts in Label Studio. For example, if a low Faithfulness score is due to missing information in your corpus, update your documents or adjust the prompt accordingly.
Once satisfied with your prompts and answers, you can switch to batch processing for efficiency. Label Studio supports bulk uploading of questions, with Ragas metrics still in place to maintain quality.
Use the feedback from Ragas to update your corpus, fine-tune your embedding model, and continuously refine your prompts. This iterative process will help you develop a more robust Q&A system over time.
Step 5: Optimize performance
To optimize performance, consider the hardware you're using. For longer or more complex answers, using a powerful local machine or upgrading to the pro version of the GPT-4 API can significantly enhance speed and overall performance. However, be mindful that longer answers can slow down Ragas evaluations. It's crucial to strike a balance between the complexity of the answers and the time required for evaluation.
As you refine your application, use Ragas metrics to detect any inconsistencies within your documentation, such as conflicting software requirements. When these discrepancies are identified, update your corpus or adjust your prompts to maintain consistency and accuracy in the generated answers.
When refining prompts, aim for specificity. For example, if you're crafting installation instructions, you might direct the model to include steps specifically for macOS. After making such adjustments, check how they influence the Faithfulness and Relevancy scores to ensure the changes are enhancing the accuracy and relevance of the output.
Step 6: Deploy and monitor
After developing and thoroughly testing your RAG application, it's time to deploy it within your organization. Ensure that all components—Label Studio, GPT-4, and Ragas—are seamlessly integrated into your production environment.
Once deployed, closely monitor the application's performance using Ragas metrics. Regularly update your corpus and refine prompts to keep the system aligned with new information and evolving user needs.
Encourage users to provide feedback on the generated answers, and use this feedback to continually enhance and refine your RAG application for optimal performance.
Want to learn more? Our expert team of humans would be happy to chat with you if you’d like to learn more about Label Studio, including the ability to fine-tune chatbots and LLMs. Get in touch today.
Related Content
-

The 5 Metrics That Actually Move AI Into Production
A practical framework for turning AI metrics into clearer decisions about what to fix, ship, and scale.

Sheree Zhang
April 15, 2026
-

Scaling AI Data Quality: Best Practices for Onboarding and Evaluating Annotators
A practical workflow for onboarding and evaluating annotators with clear instructions, calibration, quality gates, reviewer feedback, and dashboards that keep labeling consistent as volume grows.

Alec Harris
March 12, 2026
-

How to Create a Prompt Generator with Label Studio and RLVR
In this article, you'll learn how to apply an RLVR-based score verifier and use an LLM as a prompt optimizer to enhance your prompts.

Label Studio Team
March 2, 2026