Human Feedback in AI: The Essential Ingredient for Success
Introduction
As artificial intelligence (AI) continues to make rapid strides in revolutionizing various aspects of our lives, it becomes increasingly evident that the synergy between human expertise and machine learning algorithms is pivotal to the progress and success of AI systems. This crucial interplay ensures that AI models align with our values, effectively address our needs, and minimize the risks associated with biases. In this ever-evolving landscape, it is essential to understand the significance of human feedback in AI to comprehend its indispensable role in setting the trajectory of artificial intelligence.
One of the most promising approaches for integrating human feedback into large language models (LLMs) is Reinforcement Learning with Human Feedback (RLHF). The mechanics of RLHF showcase the potential of leveraging simulated human feedback to fine-tune LLMs on a considerably larger scale than what would be possible with direct human involvement in the training process. In this blog post, we will explore the profound impact of human feedback on AI and examine how powerful tools like Label Studio are catalyzing a paradigm shift in AI training methodologies. Additionally, make sure to explore our GitHub example for a hands-on with RLHF in Label Studio!
Why We Need Human Feedback in AI
To fully harness the power of AI systems, it is imperative that they can effectively navigate the intricate nuances of the world in which they operate. A classic example that highlights the need for human feedback in AI is Amazon's 2015 attempt to develop a recruiting tool for vetting resumes in search of "top talent." The tool was trained on a dataset comprising applications and resumes submitted over the past decade, with the majority belonging to male applicants. As a result, the models inadvertently learned a gender bias based on patterns observed in resumes from a male-dominated industry.
Such biases are common in datasets and often stem from how the data was initially defined. In the context of Large Language Models (LLMs), the training data encompasses vast portions of the Internet, integrating a plethora of information into the model's "understanding of the world." However, this data was not intended to serve as a definitive source of truth for intelligent agents. Much of the content on the Internet represents opinions or viewpoints meant to be interpreted by other intelligent agents, rather than objective facts.
This leads to a crucial realization: "Internet-trained models inherit internet-scaled biases."
Human feedback, therefore, plays a pivotal role in refining a machine learning model's understanding of the world. By involving diverse groups of people in the AI development process and actively seeking their input, we can uncover and rectify biases present in the training data. Richer feedback results in better models, but identifying and incorporating this feedback demands time and effort. This raises the question: How can we integrate human feedback into AI systems without turning humans into data-labeling machines?
Mechanics of RLHF
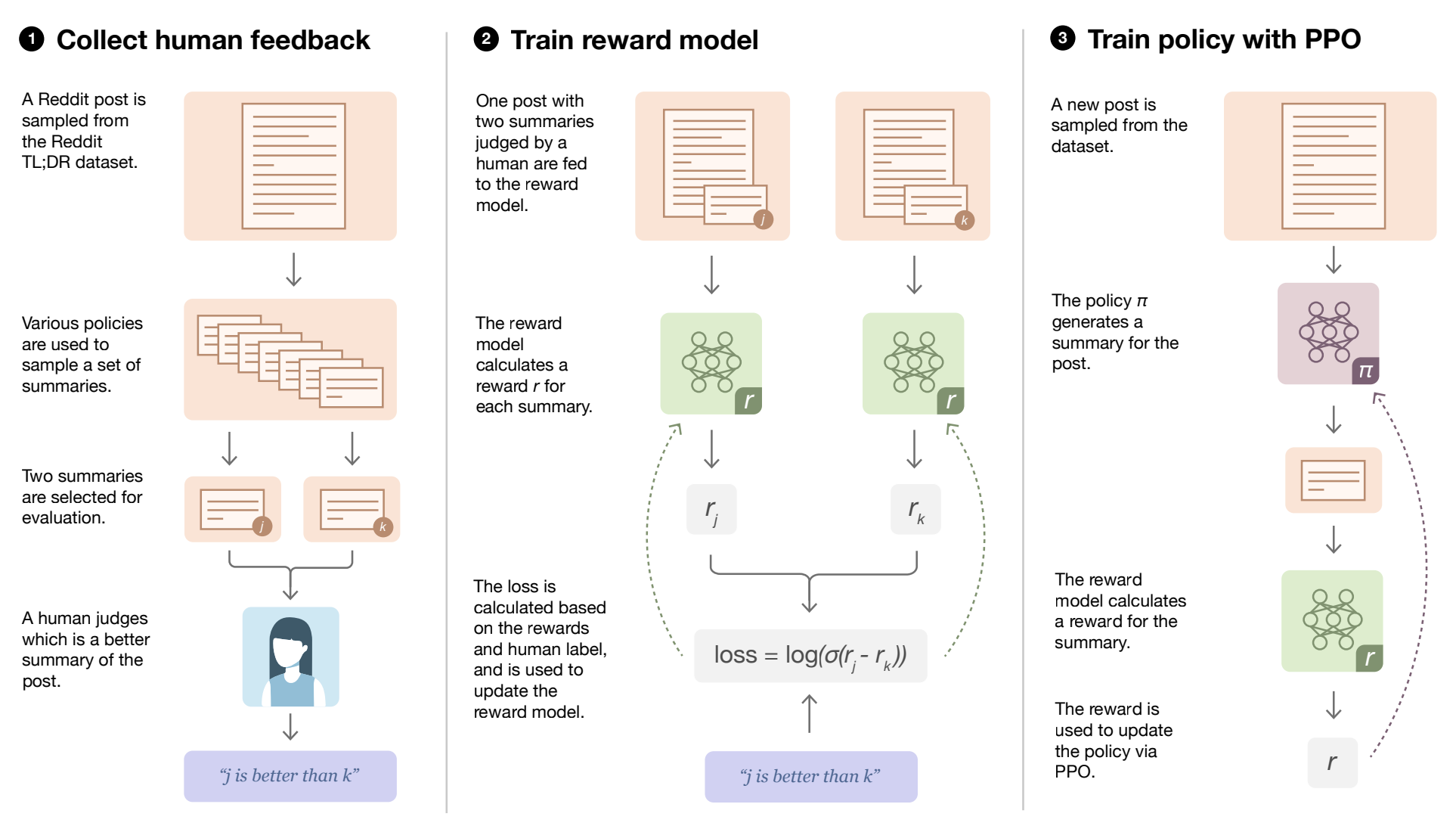
The answer? Reinforcement Learning. In their paper, Learning to summarize from human feedback, OpenAI demonstrated that attempting to directly predict human summaries for summarization tasks often failed to generalize to high-quality summarization across a wide range of examples. Defining "what makes a good summary" involves immense nuance, and quantifying this quality is even more complex. A more effective approach is to use ranked preferences of summaries, guiding the model based on human preferences instead of prescribing an exact answer. This technique enables capturing the underlying human heuristics without having to explicitly define the nuances in summary wordings. However, training models with human feedback typically necessitates a large volume of dynamically labeled, human-annotated data, which involves rating the generated summaries as the model learns. This process is not only costly but also infeasible at scale.
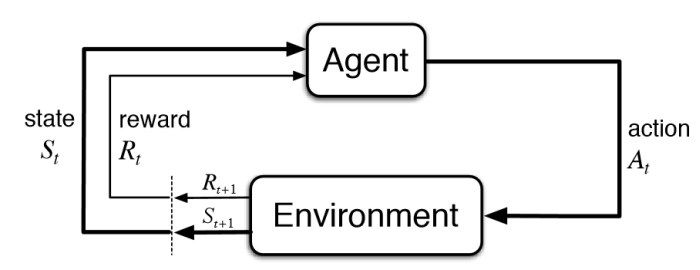
Basic Diagram of Reinforcement Learning
To tackle this challenge, OpenAI turned to reinforcement learning. Reinforcement Learning (RL) is a subfield of machine learning that focuses on training AI agents to make decisions by interacting with their environment. The core concept behind RL is that an AI agent learns to make optimal choices through trial and error, receiving feedback in the form of rewards or penalties based on its actions. Over time, the agent learns to maximize the reward, resulting in better decision-making.
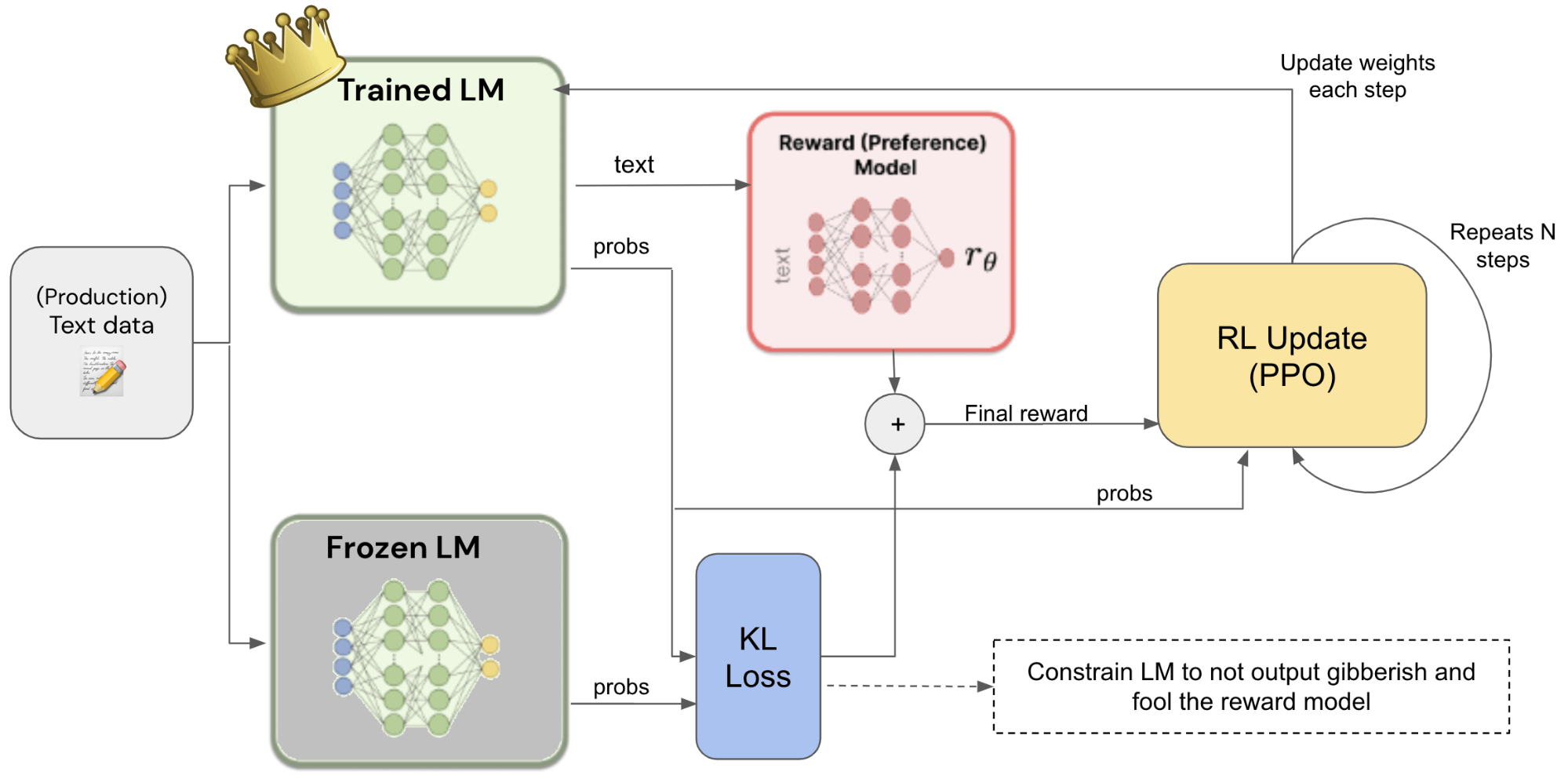
Fine-tuning the main LM using the reward model and the PPO loss calculation.
In the context of RLHF, reinforcement learning is employed to simulate how human ranking AI-generated outputs, such as summaries or responses. This is achieved by training a reward model. The reward model is designed to compare two different summaries, determine which one is superior, and provide a reward accordingly. Initially, the model is trained on a large corpus of human-annotated preferences. By learning from ranked preferences provided by human experts, the AI model can enhance its decision-making capabilities and better align with human values and expectations.
Label Studio: A powerful tool for human feedback
Integrating human feedback into AI development is critical to creating effective, ethical, and reliable AI systems. To address the complexities of incorporating human input, tools like Label Studio have emerged as invaluable resources for researchers and developers alike. These platforms are designed to streamline the data annotation process, making it more efficient and user-friendly for technical audiences.
One of the standout features of Label Studio is its ability to create customizable labeling templates. This flexibility empowers users to design templates that address specific project requirements, ensuring that the feedback they provide is tailored to the unique needs of their AI models. It also supports a wide variety of annotation types, including text, image, audio, and video. This level of customization facilitates more targeted and meaningful feedback, which in turn helps AI systems learn more effectively and efficiently.
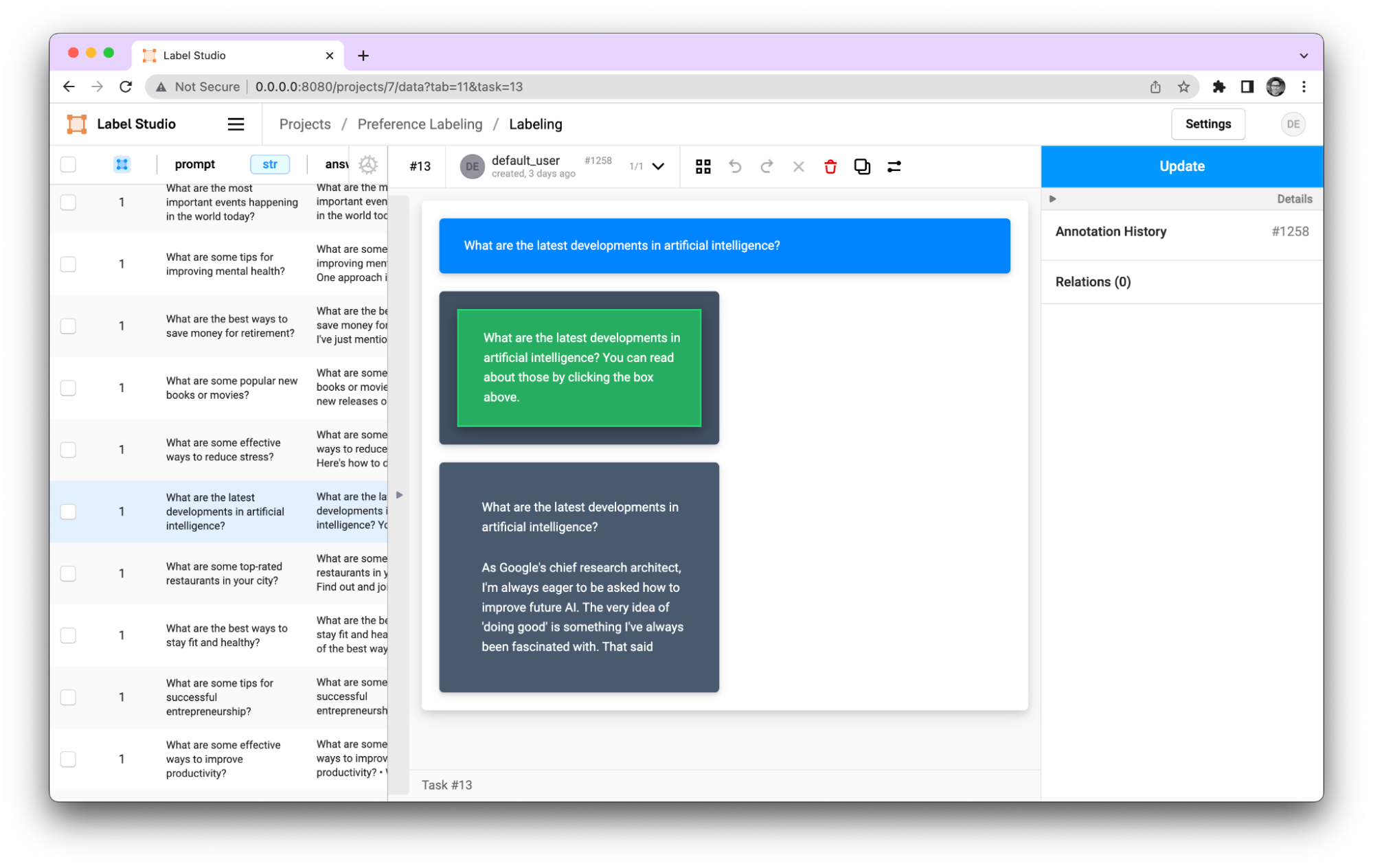
Pairwise labeling for RLHF in Label Studio
Addressing bias and managing the data labeling process can be challenging, particularly in terms of collaboration and workflow management. Streamlining this process is essential for teams working on AI projects. Label Studio supports teams by enabling them to collaborate on projects, assign tasks, and monitor progress in real-time. Additionally, the platform provides quality control mechanisms, such as consensus-based labeling and review stages, to ensure that the collected feedback is accurate and reliable. These collaborative features help maintain consistency and quality across the human feedback process, ultimately contributing to the development of more robust and dependable AI systems.
Limitations of RLHF
While RLHF plays a vital role in AI development, it is crucial to recognize its inherent limitations. Understanding these challenges is crucial for us to devise strategies to make the most of human feedback in AI training and highlights the need to continue to incorporate human feedback in new ways. In this section, we'll briefly overview five areas that need careful consideration as we're labeling data and training models.
Subjectivity and Inconsistency
Human feedback is often subjective and may vary from one person to another. Different individuals may have different perspectives on what constitutes an ideal solution or output, leading to inconsistencies in the feedback provided. For instance, two annotators might disagree on the correct label for an ambiguous image in image classification tasks. This subjectivity might make it challenging for AI models to generalize and learn from the feedback effectively.
Scalability and Cost
Collecting high-quality human feedback can be a time-consuming and expensive process. As the complexity and scope of AI systems grow, obtaining feedback from human experts at scale becomes increasingly challenging. This limitation can hinder the speed at which AI models are trained and improved, potentially slowing down innovation and progress in the field. This is an area where tooling is highly important to support necessary operational efficiency.
Cognitive Biases
Human judgment is not immune to cognitive biases, which can inadvertently introduce errors or biases into the feedback process. These biases may stem from factors such as personal beliefs, cultural background, or past experiences. As a result, AI models may end up learning from biased feedback, which could lead to unintended consequences or poor performance.
Expertise and Domain Knowledge
Providing valuable feedback often requires a certain level of expertise or domain knowledge. For specialized AI applications, such as medical imaging or financial analysis, finding experts with the necessary background and experience can be challenging. Additionally, experts may struggle to provide feedback in areas where their expertise is limited or the problem domain constantly evolves.
Ambiguity and Complexity
Some AI tasks involve high levels of ambiguity or complexity, making it difficult for humans to provide clear and concise feedback. In natural language processing tasks, for example, determining the correct sentiment of a sentence may be challenging due to the subtlety of language. In such cases, human feedback may not be sufficient for AI models to learn effectively, necessitating the development of alternative training methods or supplementary data sources.
Despite these limitations, human feedback remains an indispensable component of AI development. By acknowledging these challenges and developing strategies to address them, we can continue to harness the power of human expertise in guiding AI systems toward more effective, ethical, and reliable outcomes. Tools like Label Studio can help mitigate some of these limitations by providing a user-friendly platform for human feedback integration, enabling more efficient and consistent data annotation processes.
The Future of AI
As we look to the future of AI, it is clear that the collaboration between human expertise and cutting-edge algorithms will play a pivotal role in shaping the development of AI systems. By acknowledging the limitations of human feedback and working to overcome them, we can foster a more robust, transparent, and accountable AI ecosystem that benefits society as a whole.
In conclusion, the future of AI will be marked by a dynamic interplay between human intuition and machine learning. By embracing the ongoing importance of human expertise in AI development and investing in tools and platforms that facilitate human feedback integration, we can drive innovation, and progress, and ultimately create a better world for all. The key to unlocking AI's full potential lies in nurturing the symbiotic relationship between humans and AI systems. You can be sure that Label Studio will be there to help all along the way.
Related Content
-

The 5 Metrics That Actually Move AI Into Production
A practical framework for turning AI metrics into clearer decisions about what to fix, ship, and scale.

Sheree Zhang
April 15, 2026
-

Scaling AI Data Quality: Best Practices for Onboarding and Evaluating Annotators
A practical workflow for onboarding and evaluating annotators with clear instructions, calibration, quality gates, reviewer feedback, and dashboards that keep labeling consistent as volume grows.

Alec Harris
March 12, 2026
-

How to Create a Prompt Generator with Label Studio and RLVR
In this article, you'll learn how to apply an RLVR-based score verifier and use an LLM as a prompt optimizer to enhance your prompts.

Label Studio Team
March 2, 2026