Integrity, Accuracy, Consistency: 3 Keys to Maintaining Data Quality in Machine Learning

Machine learning models are only as effective as their training data. If the data is incomplete or improperly labeled, the model’s predictions will reflect those gaps.
But how do you identify and maintain high-quality data when you’re knee-deep in a project? And what does “data quality” mean in the context of machine learning?
At the highest level, you can simplify the answer to that question by distilling “data quality” down to three key features: integrity, accuracy, and consistency.
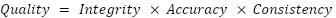
- Integrity: The reliability of the dataset you’re using
- Accuracy: The degree to which assigned annotations are valid and correct
- Consistency: The degree to which assigned annotations are consistent across the dataset

Think of each factor as part of a high-level roadmap for maintaining data quality throughout the annotation pipeline.
1. Integrity: Check for Common Errors In Your Dataset
After verifying that the data sources you’re using are complete and representative, check to ensure your dataset is free from common errors like missing values, duplicates, and outliers.
Missing Data
Streaming data pipelines are popular in machine learning because they introduce fresh, real-time data to the model so the model can reflect changes in the data. While streaming data is a powerful way to enhance model quality, it does have one drawback: it increases the odds that values will be corrupted or missed entirely during the transfer process.
That’s why it’s important to start validating data quality at this stage of the pipeline. Checking for missing and corrupted data samples prior to annotation can save you a world of trouble down the road. When you identify a corrupted sample, input the missing values manually or simply remove the example from the training data.
Duplicate Data
Duplicated data is another common error that occurs during data preparation. When a dataset contains duplicates, it has the potential to cause an improper distribution of data that skews your entire model. At the very least, duplicate data increases annotation costs by making your annotators perform the same work twice.
Data Outliers
Data outliers have values that significantly deviate from the statistical characteristics of the dataset. They may affect model performance if they’re represented too heavily in the dataset. To reduce the likelihood that outliers will skew your training data, locate and isolate them as you evaluate the dataset’s quality.
2. Accuracy: Validate the Labeled Data
Ground Truth Accuracy is the simplest way to measure the accuracy of a dataset.
The Ground Truth is a set of predefined annotations that are created before the project starts. They help the model understand what your expected results look like. Given enough Ground Truth data, the model can learn the underlying pattern that drives the results.
Ground Truth Accuracy is a direct comparison between the annotators’ answers and the Ground Truth data. The difference is often expressed as a coefficient from 0-1, where >0.9 is an acceptable amount of accuracy.
While straightforward, Ground Truth Accuracy isn’t without its drawbacks. If Ground Truth annotations aren’t selected to reflect the project’s real expected data distribution, sampling bias can occur. This is a common mistake when projects borrow their Ground Truth data from popular labeled datasets and other external labeled sources.
How to Improve Ground Truth Accuracy
If your annotations have low Ground Truth Accuracy and you’ve ruled out sampling bias, the most likely culprit is the annotation guidelines. A low score means annotators can’t understand the task, so your first line of defense is to revise and clarify the instructions. After that, communicate directly with the annotators and work through some examples together. If the annotators have questions, clarify your guidelines until those questions are resolved.
You might also consider splitting tasks into smaller, easier-to-understand subtasks. If issues persist after that, it’s time to look for annotators who are domain experts in the subject(s) your model addresses.
3. Consistency: Look for Annotator Consensus
Accuracy and consistency reinforce each other: accuracy isn’t a useful measure of quality if the labels aren’t applied consistently, and consistency isn’t a useful measure of quality if the labels aren’t accurate. Together, they make up a gold standard for data quality.
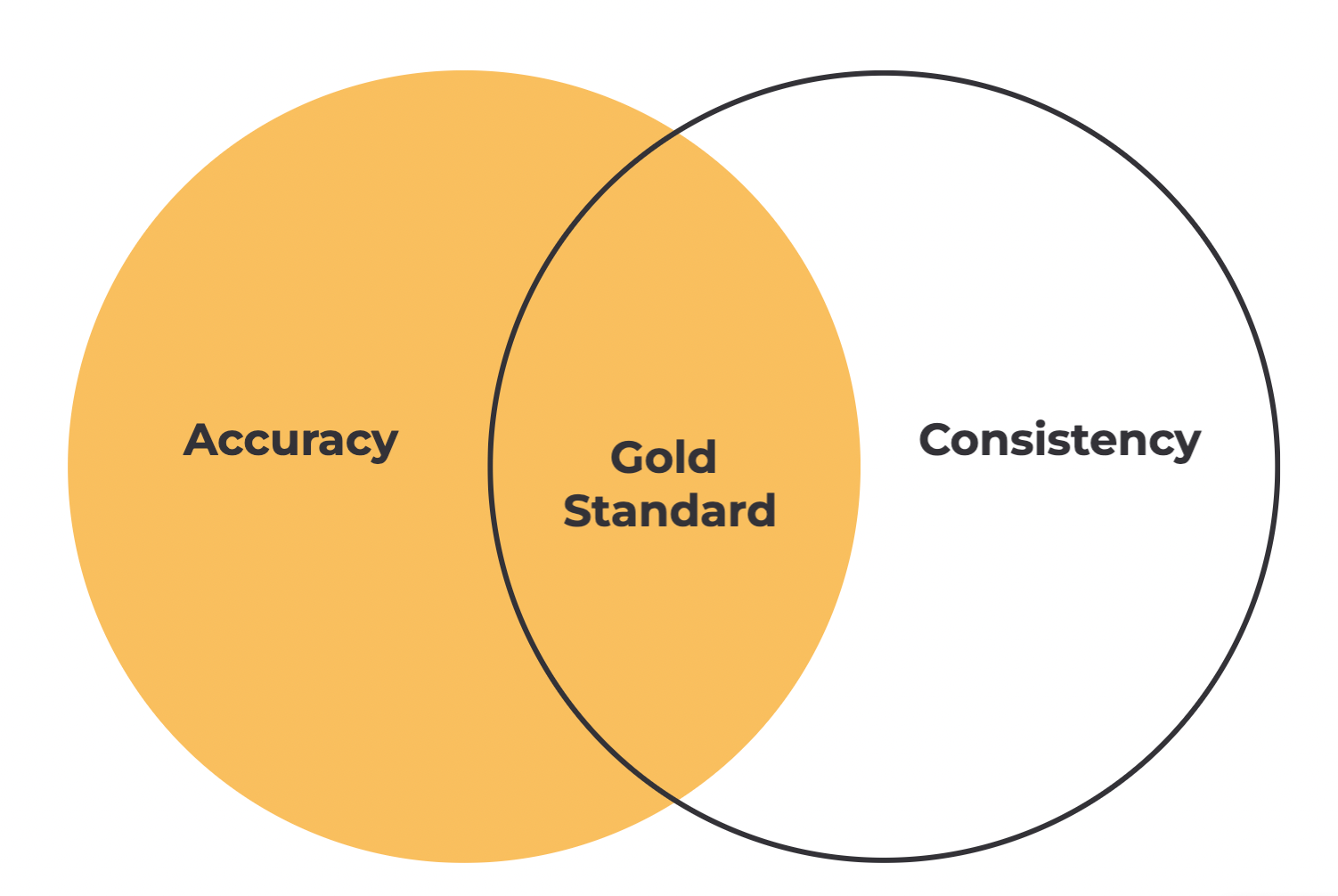
Data is consistent when you compare different versions of the same annotation and the answers agree.
Two kinds of consistency are important for model training: consistency over time, measured by Intra-Annotator Consistency, and consistency between annotators, measured by Inter-Annotator Agreement.
- Intra-Annotator Consistency (IAC) measures the annotator’s reliability over time. To track IAC, periodically send the same example(s) to the same annotator(s) and measure the rate at which the new labels agree with the earlier labels for the same task.
- Inter-Annotator Agreement (IAA) measures consensus between labelers. To track IAA, have two or more annotators label the same example and measure the rate at which they agree.
Intra-Annotator Consistency:

Inter-Annotator Agreement:

How to Improve Label Consistency
If you notice a low AIC (meaning an individual annotator’s self-consistency over time is low), think about the feedback the annotator receives between consecutive examples. If the annotator learns more with each round of feedback, then you can consider their later answers more reliable. Discard the early ones.
To avoid this issue in the first place, work through a number of examples with your annotators at the top of every project—and don’t turn them loose on the data until their consistency over time has stabilized.
For both IAC and IAA, a low agreement score indicates a potential problem in the dataset. To diagnose it, investigate the individual label first. Sometimes you just get vague or anomalous data, which is safe to discard. Other times you can spot points of confusion and clarify your instructions.
Improve Data Quality in Machine Learning with Label Studio
Maintaining integrity, accuracy, and consistency across your training data can be dead simple or logistically impossible.
What makes the difference? It all depends on your data labeling tool. From defined user roles to confidence-marking and consensus features, Label Studio makes it easy to validate data quality at scale.
Related Content
-

The 5 Metrics That Actually Move AI Into Production
A practical framework for turning AI metrics into clearer decisions about what to fix, ship, and scale.

Sheree Zhang
April 15, 2026
-

Scaling AI Data Quality: Best Practices for Onboarding and Evaluating Annotators
A practical workflow for onboarding and evaluating annotators with clear instructions, calibration, quality gates, reviewer feedback, and dashboards that keep labeling consistent as volume grows.

Alec Harris
March 12, 2026
-

How to Create a Prompt Generator with Label Studio and RLVR
In this article, you'll learn how to apply an RLVR-based score verifier and use an LLM as a prompt optimizer to enhance your prompts.

Label Studio Team
March 2, 2026