Mastering Math Reasoning with Adala

In the realm of Large Language Models (LLMs), achieving proficiency in mathematical reasoning presents a notable challenge. This task necessitates a blend of multi-step problem-solving, natural language understanding, and robust computational skills. Among the datasets that rigorously test these capabilities, OpenAI's GSM8K stands out as a critical benchmark for assessing these capabilities.
In this technical exploration, we will apply Adala – a cutting-edge tool designed to refine prompt efficiency – to enhance LLM performance on the GSM8K dataset. Leveraging Adala, we have witnessed a substantial 29.26% absolute improvement in our LLM's baseline performance on this dataset, boosting accuracy from 44.88% → 74.14%. More impressively, this leap in performance was achieved without the necessity of manual prompt engineering, highlighting the tool's efficacy.
What is Adala?
Adala (Autonomous DAta Labeling Agent) is an agent framework designed for data processing and labeling. It uniquely combines LLMs with various tools and methodologies, resulting in the formation of Adala agents. These agents are adept at processing and labeling data samples. Adala is particularly valuable in scenarios involving large, unlabeled datasets, where starting from scratch is a daunting challenge. Through iterative 'human in the loop' processes, Adala agents progressively refine their proficiency, relying on human-generated ground truth data as a benchmark for improvement.
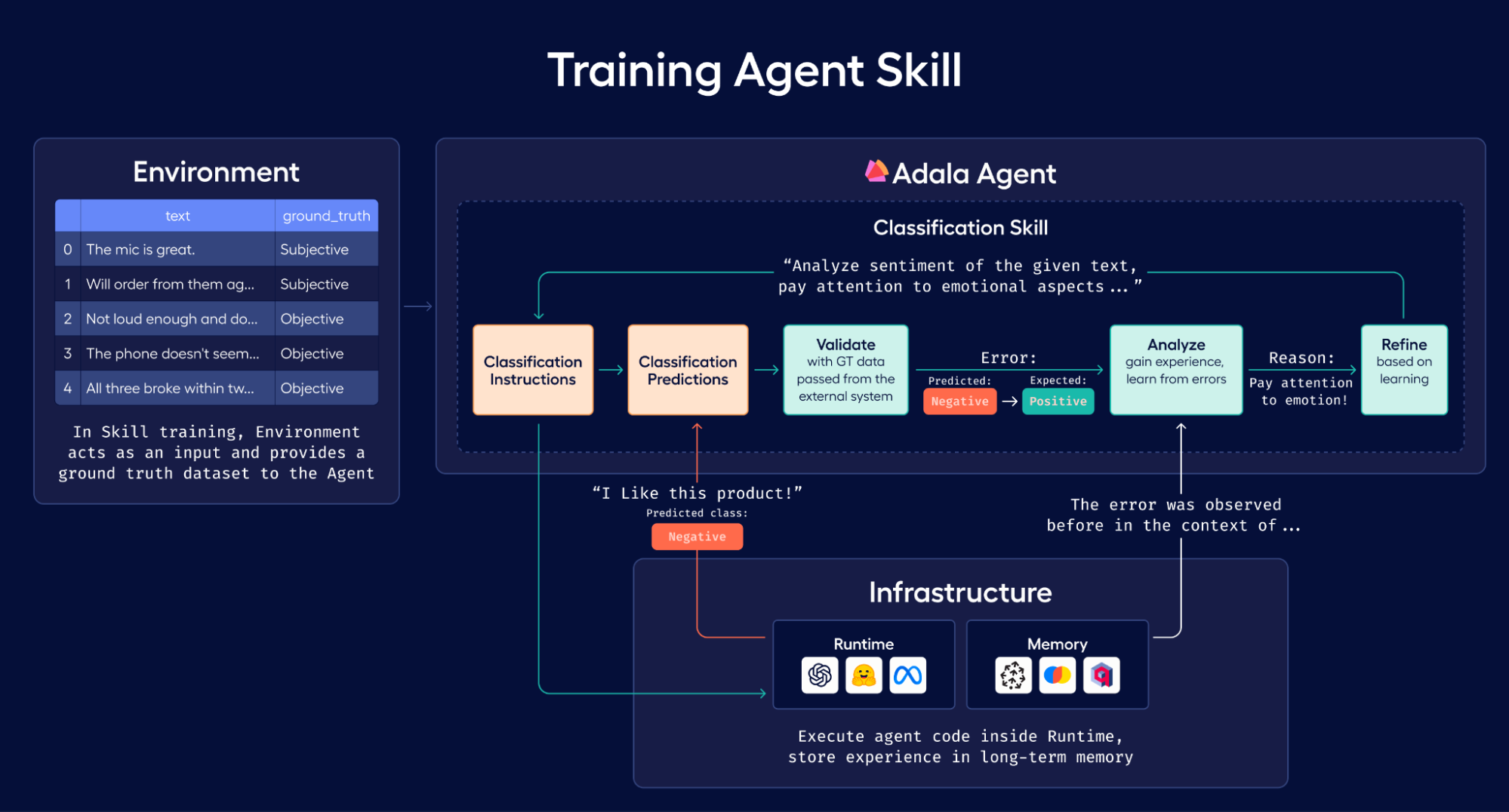
Overview of the Adala Framework
Next, let's dive into the practical application of Adala on the GSM8K dataset.
The GSM8K Dataset
The GSM8K dataset encompasses a broad array of mathematical challenges encountered in the grade-school math curriculum. This dataset isn't confined to elementary arithmetic; it spans more intricate areas like algebra, geometry, and probability. The unique aspect of GSM8K lies in its integration of natural language processing (NLP) with mathematical reasoning. Each problem in the dataset is framed as a word problem, demanding that LLMs not only interpret the text but also identify key information and apply relevant mathematical concepts to derive solutions.
Let's break this down further. When encountering a word problem from GSM8K, an LLM must first parse the language – this involves understanding the context, recognizing the specific mathematical question being asked, and distinguishing between crucial and superfluous information. Following this, it must engage in mathematical reasoning, ranging from simple calculations to complex algebraic manipulations or geometric interpretations.

Sample from the GSM8K dataset.
Overall, the GSM8K dataset is more than just a measure of computational power. It's a sophisticated, multifaceted benchmark that rigorously tests an LLM’s ability to meld language understanding, mathematical logic, and the intricacies of multi-step problem-solving. This makes it an ideal testing ground for evaluating and enhancing the capabilities of LLMs like those improved with Adala.
We’ll start our example by loading this data into a dataframe with the following code:
import pandas as pd
from datasets import load_dataset
gsm8k = load_dataset("gsm8k", "main")
df_train = pd.DataFrame({'question': gsm8k['train']['question'], 'answer': gsm8k['train']['answer']})
df_test = pd.DataFrame({'question': gsm8k['test']['question'], 'answer': gsm8k['test']['answer']})
df_train.head()A sample from our training dataframe is shown below.

A sample from the training dataframe
Adala Math Solver Agent
Creating the Adala Math Solver Agent begins with constructing a specific skill set to guide our LLM in processing the data. Here, we introduce a 'TransformerSkill' template that helps segregate questions and answers. Our method initially sidesteps detailed instructions, favoring a learning-driven approach. This means the agent gradually acquires the ability to discern and apply these instructions as it processes more data.
Let's dive into the code structure:
skills = LinearSkillSet(skills=[
TransformSkill(
name='math_solver',
# instructions=prompt
# Our agent will learn the instructions
instructions='',
# instructions=prompt,
input_template='Q: {question}',
# here is the baseline established in Kojima et al., 2022 paper
# output_template='A: Let’s think step by step. {rationale}\nFinal numerical answer:{answer}',
output_template='A: {answer}',
instructions_first=False
)
])In this snippet, the 'TransformSkill' is defined without predefined instructions. We could incorporate a prompt here as a starting point, but we will let the agent evolve its prompt organically from the data. The input template is straightforward, marking each entry as a question, while the output is currently set to provide only the answer without a detailed rationale. You may notice that our skill is part of a `LinearSkillSet`. An agent can have many skills and learn them all. Here, in our example, we will focus on just one.
Next, we create an Adala agent, equipping it with the math solver skill and an operating environment. The environment is akin to a training ground, comprising a training dataset and a function crucial for evaluating the accuracy of the agent’s responses.
We employ GPT-4 as the core LLM for the agent. It will be prompted to evaluate samples from the dataset, compare the resulting responses to the ground truth, and suggest improvements to our skill instructions.
agent = Agent(
skills=skills,
# this is where agent receives the ground truth signal
environment = StaticEnvironment(
df=df_train,
matching_function=evaluate_answers
),
teacher_runtimes={'gpt4': OpenAIChatRuntime(model='gpt-4-1106-preview')},
default_teacher_runtime='gpt4'
)With our agent configured, we can test its performance on the GSM8K dataset without specific instructions. This testing phase is crucial as it establishes a baseline for subsequent improvements. We run the agent on the test dataset, intentionally omitting the answers to assess its unprompted solving capabilities.
# run baseline agent on a test dataset
result_baseline = agent.run(df_test.drop(columns='answer'))
accuracy = StaticEnvironment(df=df_test, \
matching_function=evaluate_answers).get_feedback(skills, \
result_baseline).get_accuracy()
print(f'Baseline accuracy: {accuracy["answer"]}')Applying skill: math_solver
100%|██████████| 1319/1319
# Baseline accuracy: 0.4488248673237301This process yields a baseline accuracy of 44.88% using GPT-4, an impressive feat considering the lack of specific instructions. This serves as our starting point for further enhancements using the Adala framework.
Agent Learning
Now, we get to the core of Adala’s capability - its learning mechanism. In our scenario, the Adala agent improves its skills through interaction with its environment: the training dataset of mathematical questions and answers. Here’s an overview of the process:
- Initial Prediction and Comparison: The agent predicts answers and compares them with the actual answers in the dataset.
- Error Analysis: For incorrect predictions, the agent conducts a thorough analysis, identifying where and why it went wrong.
- Instructional Improvement: Based on this analysis, the agent asks the LLM to revise its skill instructions, thereby learning from its mistakes.
Our experiment focuses on a very small batch of 5 examples, iterating this learning process five times. We observe the agent's performance on these examples with each iteration, tracking its progress.
agent.learn(batch_size=5, learning_iterations=5)The learning process generates extensive output, but the evolution of the agent's instructions is particularly noteworthy. Post-learning, these instructions become significantly more comprehensive and tailored:
print(agent.skills['math_solver'].instructions)
For each arithmetic word problem provided, follow these steps:
- Begin by comprehensively identifying and understanding the relationships, conditions, and any given numerical
information, including the units of measurement (e.g., days, weeks, months) and the related arithmetic operations
involved in the scenario.
- Clarify the units and timing of events in the word problem, and restate them if necessary to align with the final
units desired for the solution.
- Select the appropriate mathematical operations necessary to obtain the solution. These operations may involve
addition, subtraction, multiplication, division, or the application of ratios, percentages, and proportions. Pay
special attention to any transformations or calculations that entail changes over time, such as growth rates,
aging, or accumulation of resources, ensuring proper application of increases, decreases, or proportional changes.
- Perform the calculations methodically, verifying at each juncture that the operations and results conform to the
problem's conditions. Clearly articulate each step of your calculation process, demonstrating the setup of
equations or proportions and explaining the choice of mathematical methods to maintain clarity and logic throughout
your reasoning.
- Examine each intermediate result within multi-step problems, confirming accuracy before proceeding further.
Reiterate the logical sequence of steps, especially when the problem involves cumulative or sequential changes, to
ensure continuity and logical progression in the calculation process.
- Conclude by cross-checking the final answer against the conditions and expectations set forth by the problem.
Resolve any inconsistencies encountered and articulate a coherent, exact solution.The newly learned instructions guide the agent to:
- Thoroughly understand relationships, conditions, and numerical data in the problem.
- Clarify and restate units and timelines to align with the solution's requirements.
- Choose appropriate mathematical operations, considering transformations or calculations over time.
- Methodically perform calculations, verifying each step against the problem's conditions.
- Check intermediate results in multi-step problems for accuracy and logical progression.
- Finally, cross-check the solution against the problem's initial conditions and rectify any inconsistencies.
These instructions, developed autonomously by the agent, demonstrate the power of Adala's skill-tuning capability. They are intricate and well-structured, showcasing a level of detail that would be time-consuming to achieve manually.
With the improved skill set, we test the agent again:
result_new = agent.run(df_test.drop(columns='answer'))
accuracy = StaticEnvironment(df=df_test, \
matching_function=evaluate_answers).get_feedback(skills, \
result_baseline).get_accuracy()
print(f'New accuracy: {accuracy["answer"]}')Calculating the new accuracy:
New accuracy: 0.7414708112206216The outcome? A new accuracy of 74.14% marks a substantial improvement of 29.26% over the original baseline of 44.88%. This significant leap, achieved through just five iterations on a handful of examples, underscores the efficacy of Adala's learning mechanism and its transformative impact on LLM performance.
Advancing Beyond Prompt Tuning
In our exploration, we utilized a compact set of just five training examples, leading to a notable improvement in our model's performance. This achievement is just the tip of the iceberg regarding the potential enhancements that can be achieved with Adala. The scope for refining our agent's skills is vast, and Adala provides us with various avenues to explore beyond mere prompt tuning.
Here's a breakdown of the next steps and possibilities:
- Expanding the Training Dataset: While we started with a minimal set, expanding the number of training examples can significantly amplify the learning and accuracy of the agent. Each new example adds nuance and complexity to the agent's understanding, further refining its capabilities.
- Applying Skills to New, Unlabeled Data: Once the agent's skills surpass a certain level of proficiency, we can deploy the agent on fresh, unlabeled datasets. This is particularly advantageous in scenarios where initial labels are limited or nonexistent. The agent's predictions provide a preliminary set of labels, offering a valuable starting point for further data labeling and analysis.
- Iterative Learning and Human Input Integration: As we gather more ground truth data, this can be fed into the agent's environment, facilitating continuous learning and skill enhancement. This iterative process, where human inputs and AI-driven analysis coalesce, forms a dynamic improvement loop.
This iterative process, combining automated learning with human oversight, exemplifies the strength of Adala. It accelerates the data labeling process and enhances the quality of the output through continuous learning and human validation. Adala creates a symbiotic environment where machine learning and human expertise converge, leading to progressively more refined and accurate models.
Conclusion
Our exploration with Adala has demonstrated its remarkable ability to automate the improvement of prompts using real data as a guide. By applying Adala to the GSM8K dataset, we significantly enhanced baseline accuracy. This advancement is not just theoretical; when we compare our scores to the GSM8K leaderboard – our score moves from 70th to 38th position by learning from only five examples (at the time of writing).
This example offers a glimpse into the practical utility and impact of Adala in data-guided automation and prompt tuning. Make sure to check out the complete example notebook in the Adala GitHub repo and get involved in the conversation on the Adala Discord channel.