Building the New Human Evaluation Layer for AI and Agentic systems
Human evaluation has always mattered. But as teams move from single-step models to agentic workflows, the way we do human review hasn’t kept up.
Agents don’t just produce an answer. They generate traces, tool calls, intermediate decisions, and multimodal outputs that unfold step by step. Most labeling tools, and even observability dashboards, were built for static outputs. They’re not designed to help humans understand what actually happened inside an agent.
When the interface doesn’t reflect how the system behaves, reviewers lose context. Important details get missed, and human judgment becomes less reliable.
To build, deploy, and run agentic systems safely, teams need interfaces for evaluation that adapt to their data and workflows, not the other way around.
Today, we’re introducing a new evaluation engine in Label Studio to build the next generation of human supervision interfaces for multi-modal AI and agentic systems.
Our goal is simple: give teams one place to evaluate AI across its full lifecycle, from pre-deployment benchmarking to in-production review, using interfaces that make complex behavior easy to understand.
What’s different about the new evaluation engine
This new interface isn’t a template gallery or a simple extension. It’s an entirely new runtime designed to render custom interfaces and make those interfaces embeddable, enabling more employees to become AI evaluators within their native tools and workflows.
It’s programmable
Most annotation tools expect your data to fit their format. If it doesn’t, you end up reshaping the data or working around the tool.
With this engine, the interface adapts to the data.
You can design interfaces that follow an agent’s execution step by step, render tool calls in a presentable way, and capture feedback at the moment it matters, not just on the final output. The interface can reflect state, branching, and context, instead of flattening everything into a form.
This makes it possible to evaluate not just what an agent did, but how it did it.
It’s embeddable
Human review shouldn’t live in a separate tool.
The same interface can be embedded directly into internal products, dashboards, or workflows. Because it’s programmable, it can match your design system and interaction patterns, so it feels native wherever it’s used.
That means reviews, corrections, and feedback can happen right where decisions are made, without context switching. The interface meets users where they are.
It’s multimodal
The world is getting more multi-modal and more agentic.
Chatbots are evolving beyond text-based conversations. Users want to upload images, videos, and documents to provide richer context for their requests. Agents now respond with visual artifacts or even entire applications as part of their answers. Many are built specifically to generate these outputs, including images, code, and full product prototypes.
As use cases get more complex, the need for a human-in-the-loop grows too. The interface handles the complexity so humans don’t have to.
Ready to integrate with workflows for production
A programmable interface alone isn’t enough. Human supervision only works in production when it’s connected to systems that manage quality, risk, and accountability.
All of this new UI capability is tightly integrated with Label Studio Enterprise workflows. Interfaces rendered by the runtime can plug directly into AI-assisted labeling and evaluation, routing and escalation logic, annotator agreement, analytics, workforce management, and audit trails.
As a result, interfaces don’t just collect feedback – they participate in governed, traceable, and measurable human oversight. This is the difference between a custom UI and a supervision system built for real-world AI deployment.
Let’s look at a few examples
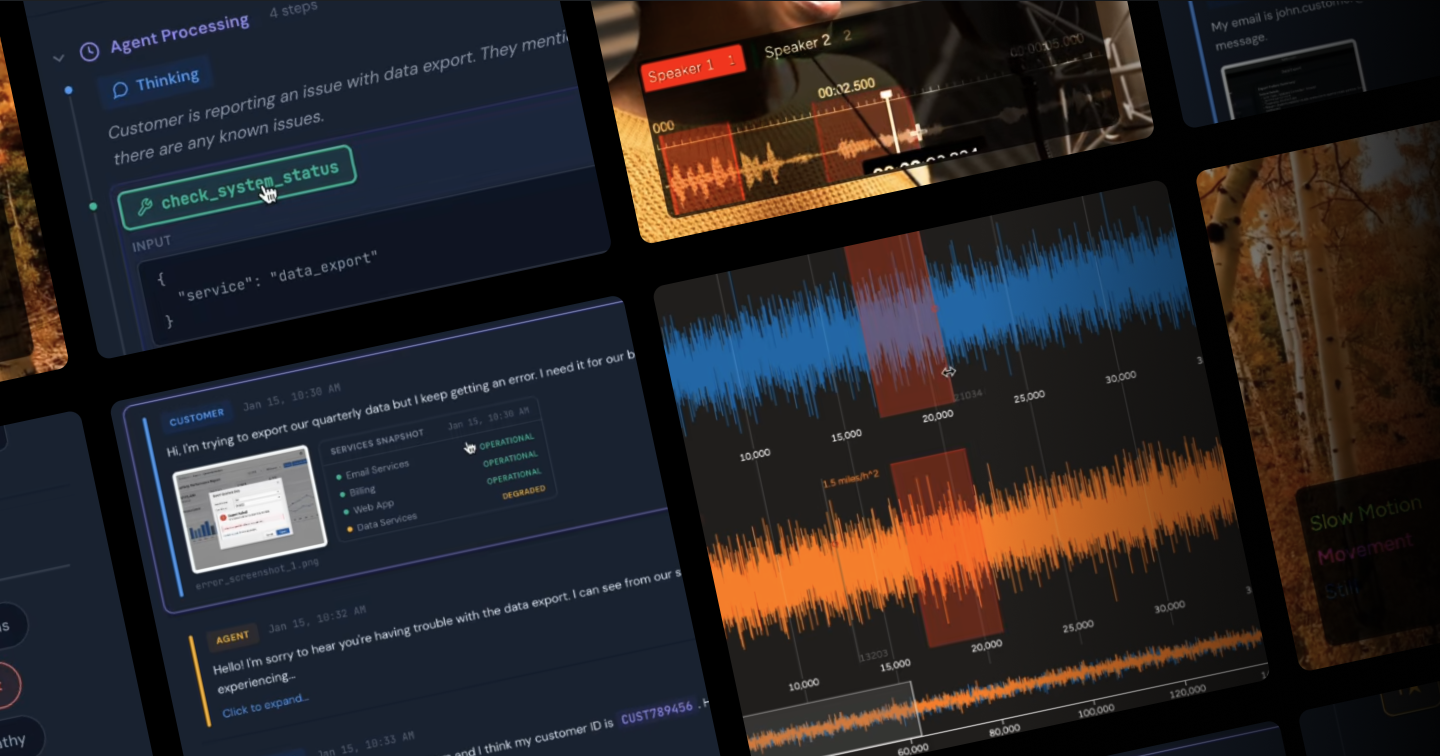
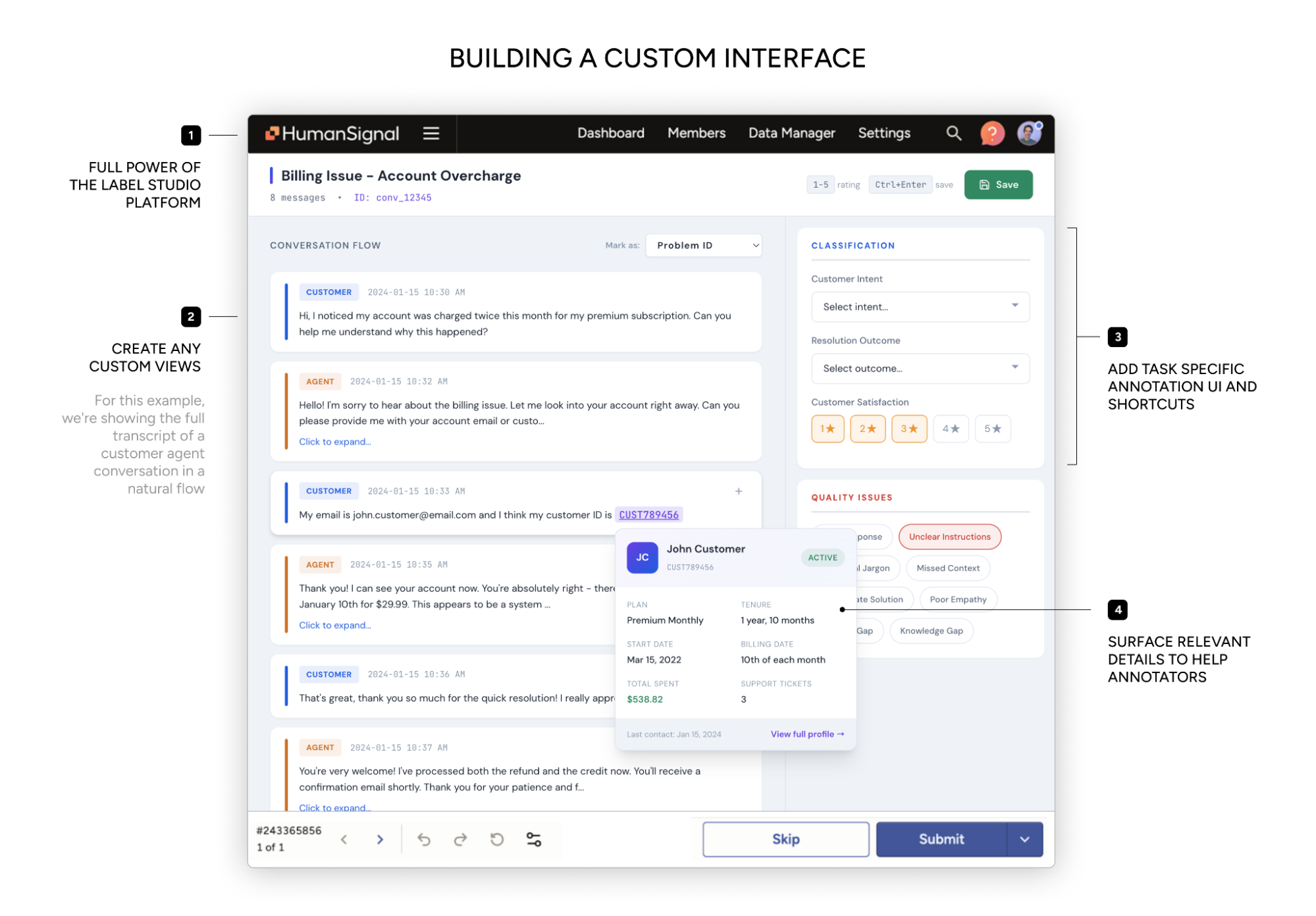
Starting simple
A team uploads customer support conversations to label intent and outcome. The interface shows the full conversation, highlights key moments, and captures structured labels alongside reviewer notes.
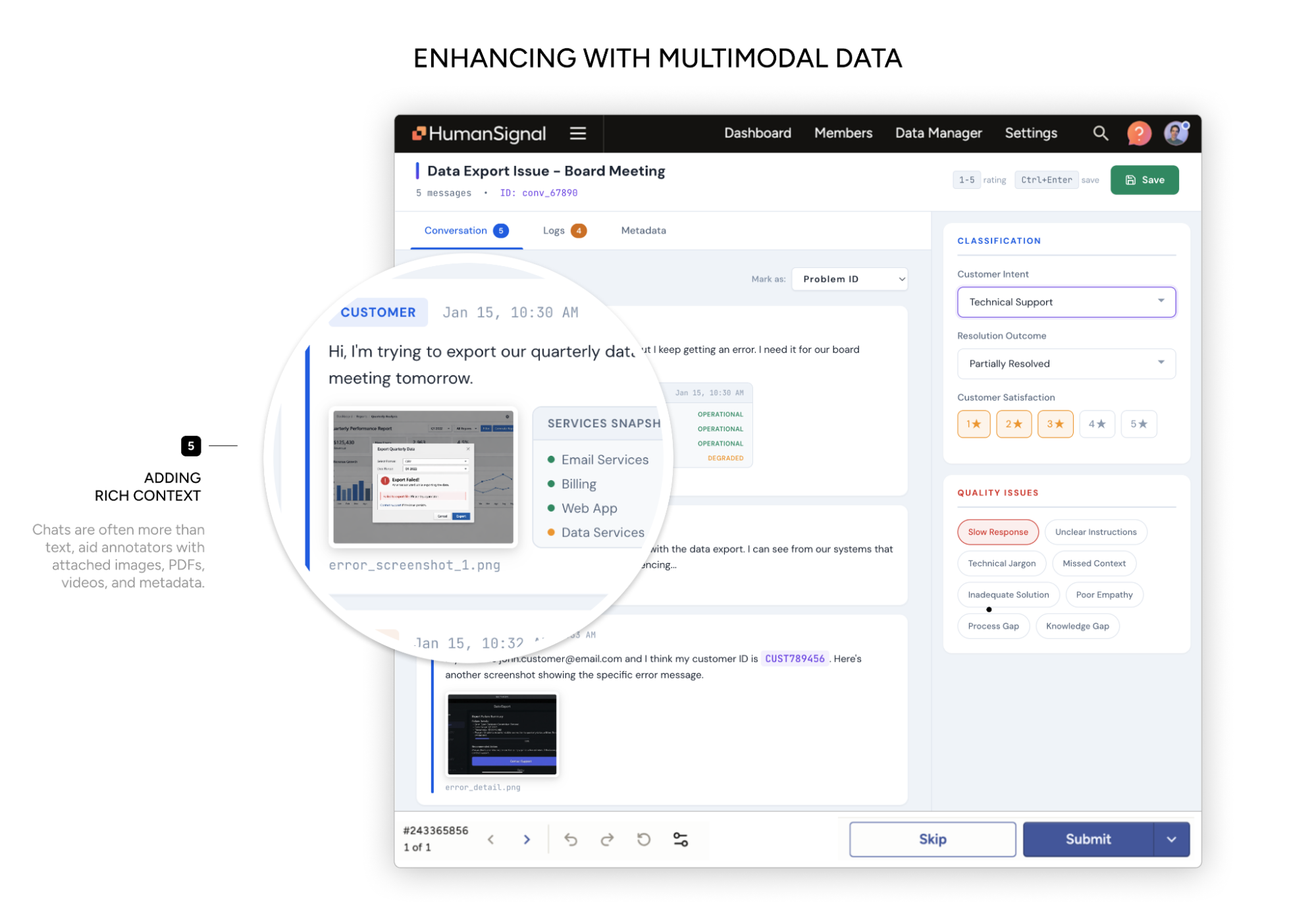
Add multimodal context
The same task now includes screenshots, logs, and metadata. Text, images, and structured data are rendered together in a single view.
Evaluate agentic workflows
Next, the team evaluates an agentic system instead of a single model output. Each item now includes a full execution trace.
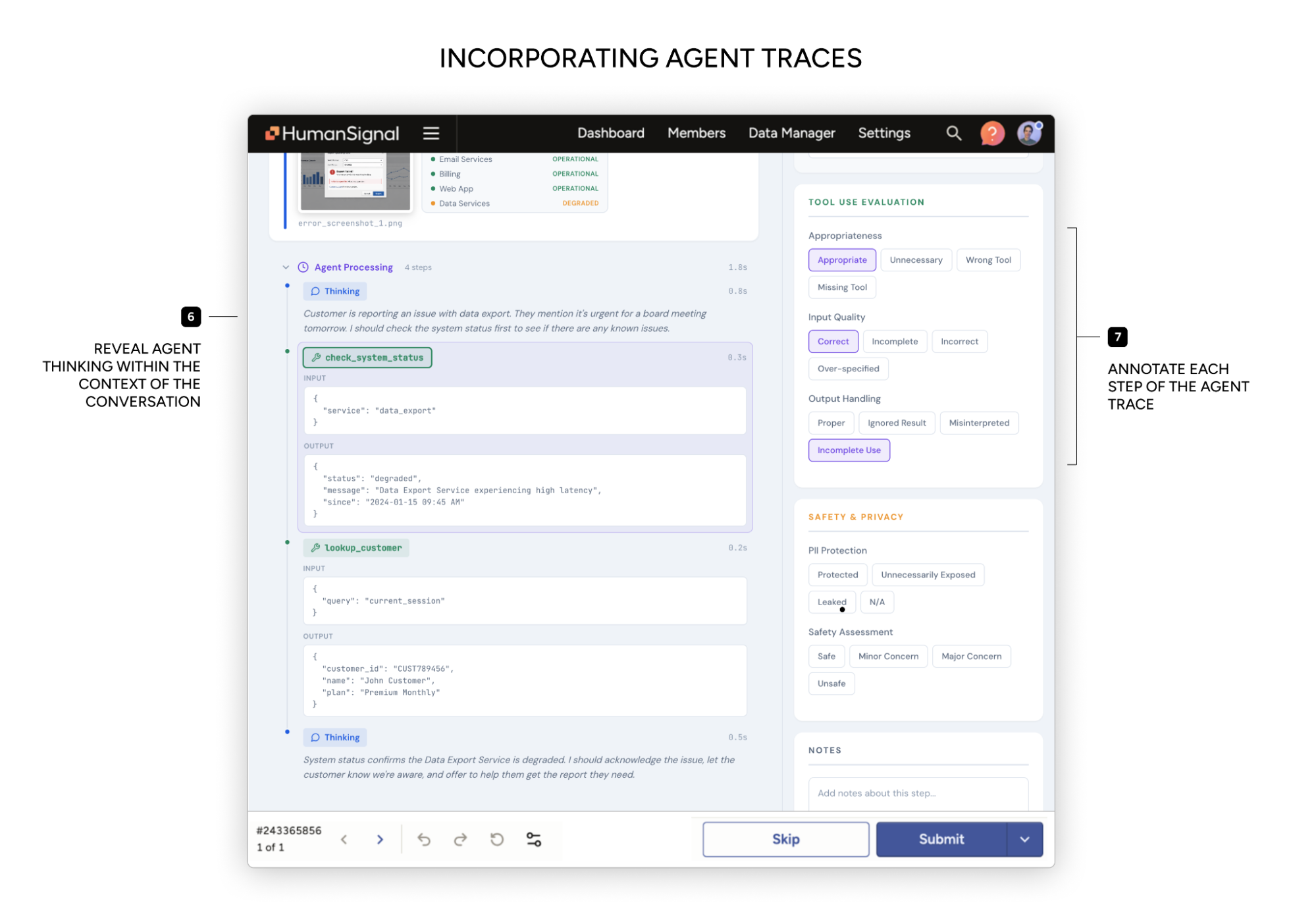
Tool calls are clearly rendered, traces are shown step by step, and reviewers can leave feedback on specific steps in the run, not just the final result. Labels and criteria can change depending on which step is being evaluated.
Embedded inside your product
Finally, the same interface is embedded directly into an internal product. When an agent action is uncertain or risky, the relevant trace opens inline for review and correction.
Human judgment becomes part of the native workflow, not an afterthought.
What’s next
As AI systems become more agentic and more multimodal, human evaluation needs more context, not more complexity.
We’re focused on making these interfaces easier to build and maintain over time, while keeping the mental model simple: one engine, one interface, used and embedded wherever human judgment is needed, in the place where it is easiest to capture.
If you’re working with complex or agentic systems and struggling to make human evaluation practical, we’d love to learn from you and build alongside your team.
Contact us and let us help you get started.
Related Content
-

Evaluate Multi-Modal Agents in Label Studio
If you are building agentic systems, you need an intuitive interface for evaluation. That's why Label Studio now supports evaluating multi-modal agents across text, visuals, and application outputs.

Alec Harris
November 19, 2025
-
HumanSignal acquires Erud AI to build the world’s frontier data lab
AI has outgrown the open web. HumanSignal Services is creating multimodal data from scratch for frontier AI labs, with Label Studio as the backbone.

Michael Malyuk
November 5, 2025
-
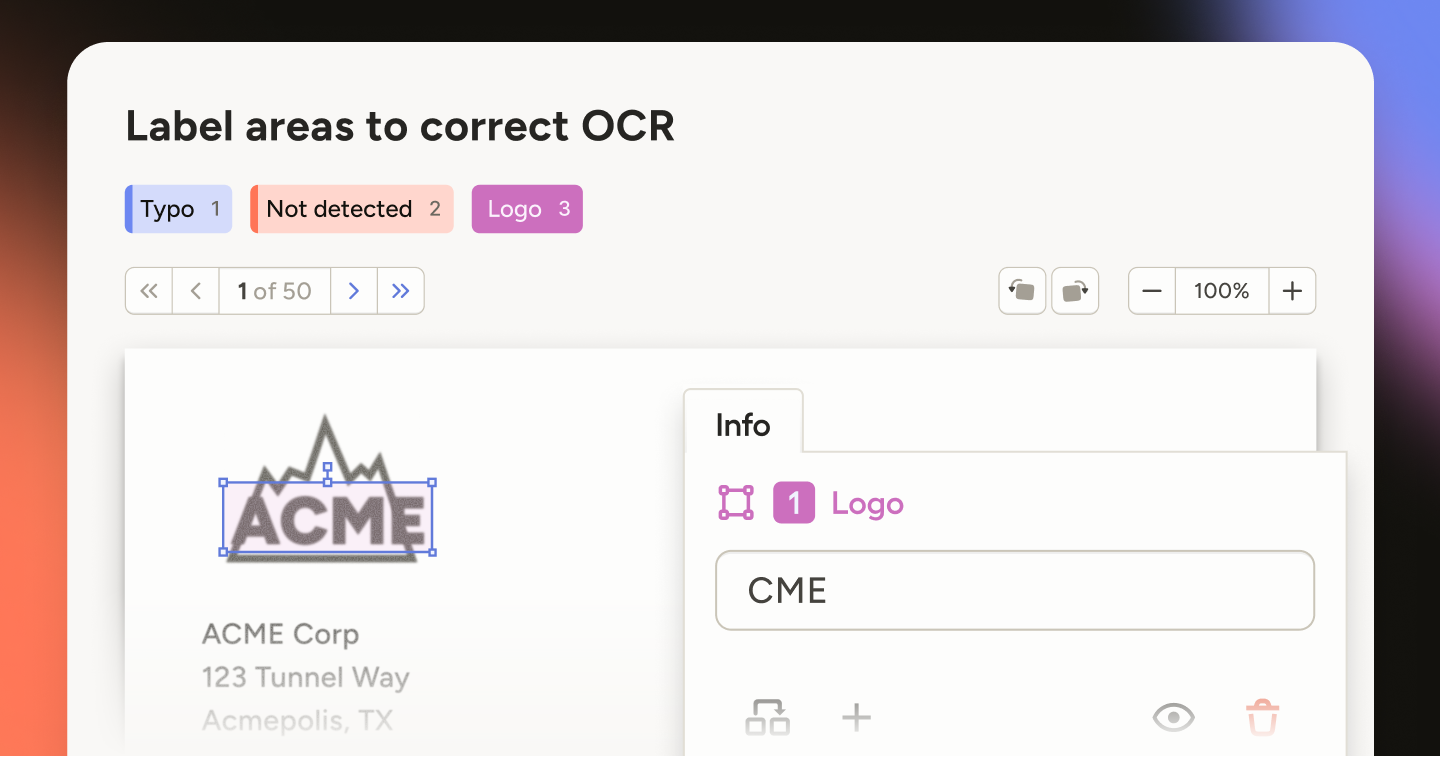
Inline PDF Labeling in Label Studio Enterprise for OCR
Label Studio Enterprise lets reviewers correct OCR directly on PDFs. Draw OcrLabels on the page, capture or fix text, and export structured records with page and coordinates.

HumanSignal Team
October 27, 2025