Seven Ways Your RAG System Could be Failing and How to Fix Them

Retrieval-Augmented Generation (RAG) has been promoted as a way to improve large language models (LLMs) by grounding them in external knowledge. By combining document retrieval with text generation, RAG helps AI provide more accurate, up-to-date, and relevant answers. In theory, this should reduce hallucinations and improve reliability.
But in reality, many RAG systems still fail to deliver accurate, useful responses, often in ways that are not immediately obvious.
You ask a question, and the AI gives a confidently written but incomplete answer. Or it pulls irrelevant documents, drowning you in noise. Or worse, it hallucinates information that was never in your dataset in the first place.
So why does this happen? And more importantly, how do you fix it?
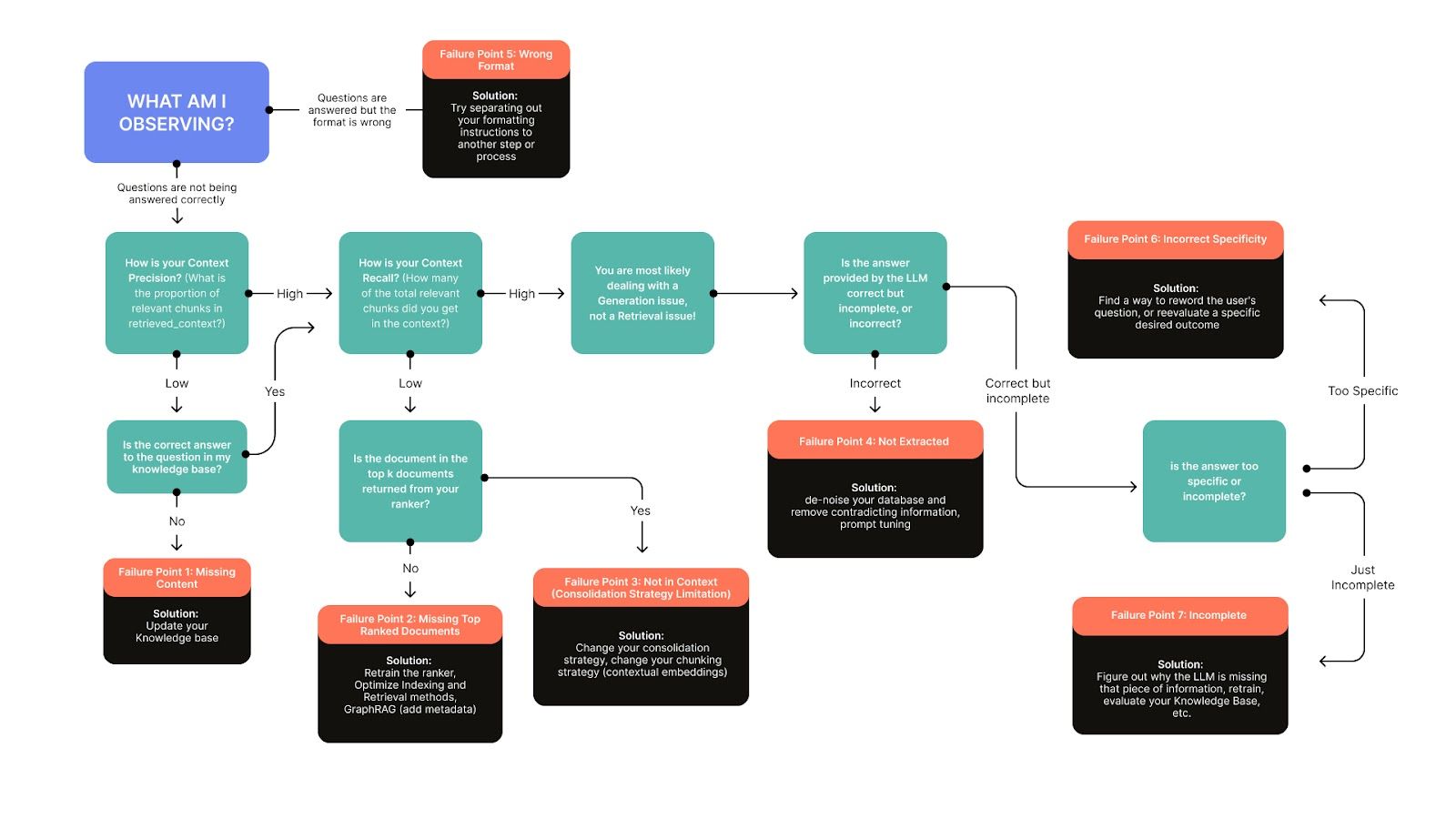
Where RAG Systems Fail
A RAG system has two stages: :
- Retrieval Stage: The system does not pull the right documents or retrieves too much irrelevant information, leading to weak context.
- Generation Stage: The model produces incorrect, incomplete, or poorly formatted responses based on the retrieved data.
Both of these stages need to work together to produce reliable outputs. If retrieval fails, generation will always struggle, no matter how good your LLM is.
A recent study by Barnett et al. (2024), Seven Failure Points When Engineering a Retrieval-Augmented Generation System, highlights seven common failure points in RAG implementations. Many of these failures stem from issues in retrieval accuracy, ranking, and content consolidation—reinforcing the need for careful optimization at both retrieval and generation stages.
This is why following Retrieval-Augmented Generation best practices is key to ensuring that your system retrieves and generates accurate responses.
Failure 1: Missing Content
The retrieved documents do not contain the answer, leaving the model without relevant context. This often results in hallucination or vague responses.
How to Fix It:
- Ensure your knowledge base is complete and contains up-to-date, well-structured data.
- If the content is missing, RAG cannot retrieve what isn’t there, so enrich your database with relevant materials.
- Consider human-in-the-loop validation to spot gaps in coverage.
Failure 2: Missing Top Ranked Documents
The correct information exists in your dataset, but the ranker, or the model that takes the retrieved document and ranks them in order of relevance, ranks it too low, causing the model to miss it.
How to Fix It:
- Optimize retrieval ranking by fine-tuning the ranker (and reranker) models.
- Check if key documents appear in the top K results and adjust ranking strategies accordingly.
- Consider re-ranking strategies to ensure that the most relevant chunks are surfaced.

Failure 3: Not in Context (Consolidation Strategy Limitation)
The retriever finds the right document, but it does not make it into the LLM’s context window, either due to truncation, poor chunking, or an ineffective consolidation strategy.
How to Fix It:
- Experiment with Top-K results—adjust the number of retrieved documents to balance recall and precision.
- Refine truncation strategies to ensure key details are preserved.
- Improve chunking methods to maintain logical structure and enhance retrieval effectiveness.
Failure 4: Not Extracted
The answer is in the retrieved context, but the LLM fails to extract it correctly, often due to noise, ambiguity, or contradicting information.
How to Fix It:
- Dedupe and clean up conflicting information in your knowledge base.
- Optimize prompts to encourage precise extraction.
- Limit retrieval noise by ensuring only the most relevant context is passed to the model.

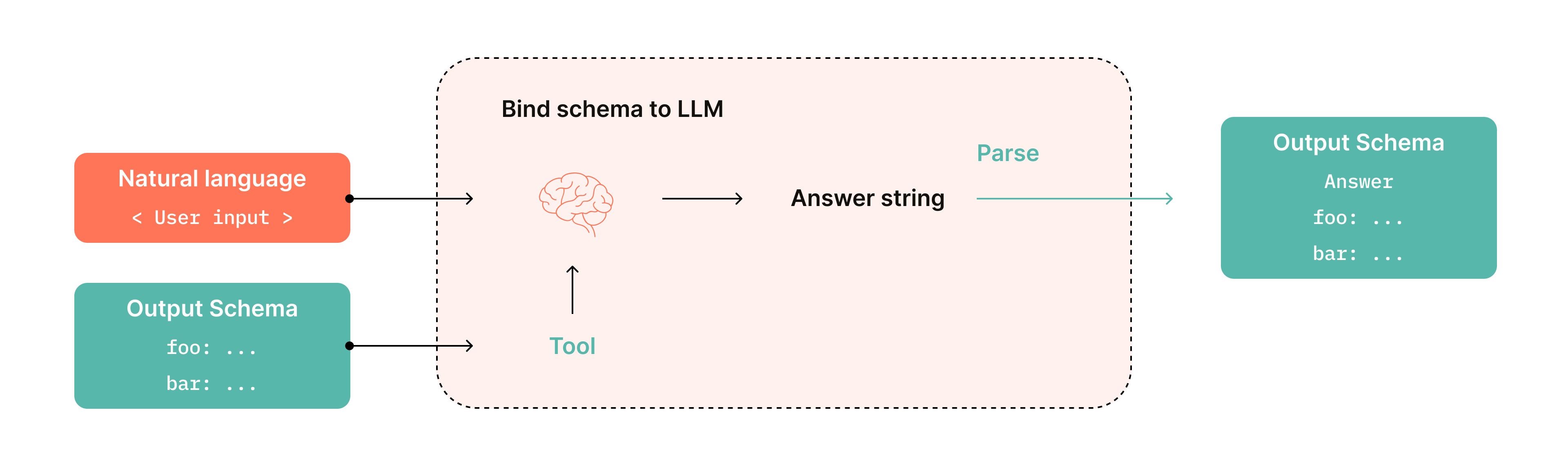
Failure 5: Wrong Format
The LLM provides an answer in the wrong format, making it difficult to use (e.g., returning unstructured text instead of JSON or a table).
How to Fix It:
- Use structured outputs like JSON or predefined schemas.
- Separate formatting instructions from content instructions in prompts.
- Leverage LLM features that enforce schema-based responses (e.g., OpenAI’s function calling).
Failure 6: Incorrect Specificity
The response is either too broad or too narrow, missing the intended level of detail.
How to Fix It:
- Use query pre-processing to refine vague or overly general queries before retrieval.
- Show users example questions to encourage better input phrasing.
- Implement query rewriting on the backend to clarify ambiguous user intents.
Failure 7: Incomplete Answer
The response is partially correct but lacks full coverage of the question. For example, if a user asks, "What are the key points in documents A, B, and C?" and the model only returns information from Document A.
How to Fix It:
- Break complex questions into multiple queries to ensure comprehensive responses.
- Improve query rewriting to reformulate broad questions into well-scoped sub-questions.
- Use ranking adjustments to prioritize retrieving a complete answer set.
Real-World Troubleshooting: Fixing RAG Failures in Action
Optimizing retrieval strategies and refining generation prompts can help mitigate many of these issues, but troubleshooting a failing RAG system requires more than theoretical solutions. Seeing real examples of failure points—and how they were fixed—can provide deeper insight into these challenges.
In our webinar, "Seven RAG Failures and How to Fix Them," we walk through actual retrieval and generation failures, diagnosing the root causes and applying fixes in real-time. If you want to see how to:
- Identify whether a failure is due to retrieval or generation
- Use ranking adjustments and query rewriting to improve accuracy
- Implement structured output formats to enforce better response consistency
Then check out the full recording here.
Turning RAG Failures Into Reliable AI Systems
RAG is a powerful tool, but only if retrieval and generation are properly optimized. Many failures stem from weak document retrieval, unclear prompt instructions, or hallucinated answers. The good news is that these issues are solvable with better ranking strategies, human evaluation, and a well-maintained knowledge base.
By implementing Retrieval-Augmented Generation best practices, you can build a system that retrieves the right information, formats it correctly, and generates reliable, context-aware responses.
If you are just getting started with optimizing RAG, check out our fundamentals guide. And if you want to see these solutions in action, watch our full webinar on diagnosing and fixing RAG failures here.
With the right retrieval strategies, knowledge curation, and human oversight, your RAG system can move from inconsistent and error-prone to a trusted AI assistant that delivers meaningful results.
Related Content
-

The 5 Metrics That Actually Move AI Into Production
A practical framework for turning AI metrics into clearer decisions about what to fix, ship, and scale.

Sheree Zhang
April 15, 2026
-

Scaling AI Data Quality: Best Practices for Onboarding and Evaluating Annotators
A practical workflow for onboarding and evaluating annotators with clear instructions, calibration, quality gates, reviewer feedback, and dashboards that keep labeling consistent as volume grows.

Alec Harris
March 12, 2026
-

How to Create a Prompt Generator with Label Studio and RLVR
In this article, you'll learn how to apply an RLVR-based score verifier and use an LLM as a prompt optimizer to enhance your prompts.

Label Studio Team
March 2, 2026