Strategies for Evaluating LLMs

LLMs like ChatGPT are very powerful tools of knowledge and productivity. They can win trivia games, solve math problems, and help you code. But LLMs are still a work in progress. They don’t know how to do specific tasks like search you team’s database and summarize an effective prioritization list. For that, you need more sophisticated fine-tuned models, RAG solutions, and prompt engineering methods.
So how should we evaluate the quality of LLMs?
There are two kinds of evaluations: inter-LLM evaluation and intra-LLM evaluation. More plainly, 1) how to pick the best LLM among a set of LLMs, and 2) how to assess the quality of one particular LLM on some task.
For evaluating which LLM you’d like to use, there are two main methods: comparing LLMs on different benchmark tests and testing LLMs on AI leaderboard challenges.
For evaluating the quality of one particular LLM on some task, one of the main ways you might approach that is by creating a unique evaluation dataset for that task.
What are some ways we can conduct evaluations?
Here are a few ways we can conduct LLM evaluations, from least complex to most complex:
- Benchmarking
- Gold standard questions
- AI leaderboards
- Reinforcement Learning
- Human feedback
- AI feedback
- Fine-tuning small classification LLMs for your task
- A/B testing LLMs in production
Benchmarking
There are several open-source labeled datasets that measure different qualities of language models. Some of the most popular benchmark datasets include HellaSwag, TruthfulQA, and MMLU. These benchmarks are labeled with an input and correct output.
💡 Input: 2+2
Output: 4Benchmarks are used to test LLMs by providing models an input and seeing if the model generates an output that matches the correct answer.
For example, HellaSwag is a labeled multiple-choice Q&A dataset. The input is the question and the output is the correct multiple-choice selection.
Benchmarks are a great starting point to evaluate LLMs, but they’re not fully comprehensive. Benchmarks can only evaluate a few features that may be important contributors to overall quality. Some benchmarks will measure how much factual knowledge a LLM has, while others will measure math or reasoning abilities. In combination, benchmarks can provide an illustrative peek into a LLM’s capabilities. However, for enterprise use cases, you’ll need even more.
Gold Standard Questions
Gold Standard Questions (GSQs) are a kind of labeled dataset created to fit your ideal use case. This can also be considered a custom dataset. This is a very effective strategy to test whether an AI model does well on your particular use case, and is usually derived from your own proprietary data.
The way this method works is similar to benchmark testing. You administer a test (of inputs) and see how similar the model outputs are compared to the correct answer. Models that score higher on your GSQ dataset are likely better candidates for your goals.
The main challenge with GSQs is that it’s often difficult and time-consuming to build those datasets. As a result, sometimes the datasets are relatively small and limited. A limited evaluation dataset will limit the strength of your evaluation metrics.
💡 If you’d like to build a dataset of human- or LLM-generated evaluations of your model, reach out to our team here at HumanSignal.AI Leaderboards
Another kind of general benchmarking is AI leaderboards. AI leaderboards represent a kind of pairwise evaluation. Participants provide some input to two random, unidentified models and select which model provided a better output. Models are then ranked on these leaderboards based on their performance in these pairwise comparisons.
Hugging Face hosts some of the most popular AI leaderboards, including:
- Hugging Face’s Open LLM Leaderboard - for open source models
- ChatBotArena Leaderboard - for both open and closed source models
- MT Bench - multi-turn question set
You can find those and many more on Hugging Face's collection of LLM leaderboards here.
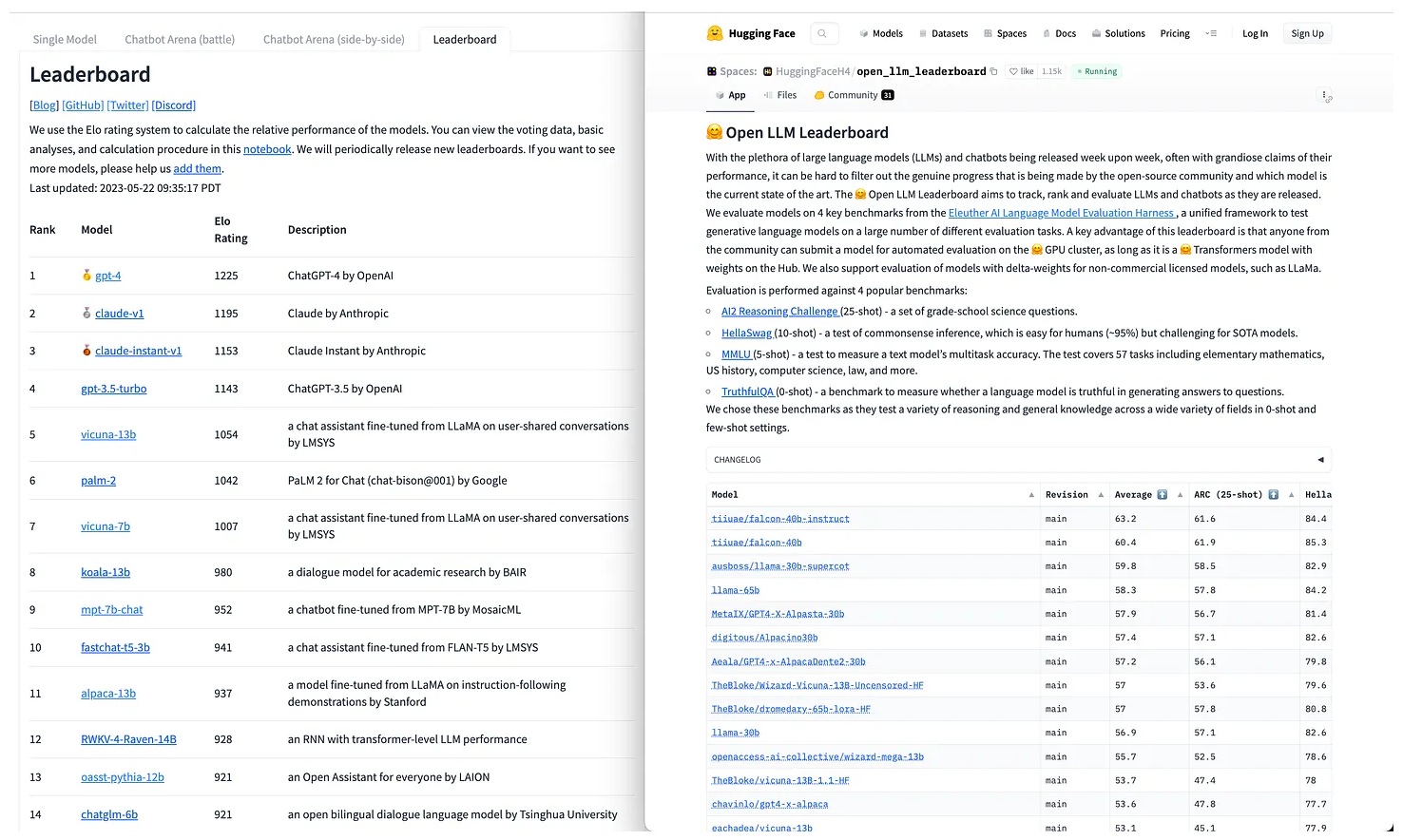
AI leaderboards are a great way to see a quick snapshot of which models rank highly according to voters. It’s great to test out smaller, independent models across human-preference tests. It’s expensive to run these comparison tests on your own and difficult to get included in many research projects that have funding. The AI leaderboards provide opportunities for smaller players to demonstrate their abilities.
AI leaderboards, however, will still be biased. AI Leaderboard voters will only cover a small sub-set of your potential user profiles. Additionally, they may not test on queries you care about for enterprise use cases.
Reinforcement Learning Evaluations
Until now, we’ve mostly been talking about datasets that have a correct answer. In this section, we’ll talk about building a reinforcement learning (RL) dataset. It’s structurally similar to the other datasets — there’s an input and a “correct” output — but with RL datasets, the emphasis is usually on whether the output is good or bad, not right or wrong.
To begin, there are three main kinds of RL datasets:
- Human-generated
- AI-generated
- Hybrid (some human-generated, some AI-generated)
These are three simplified kinds of RL evaluations:
- Thumbs Up, Thumbs Down Rating (good/bad)
- A vs. B (is answer A or B better?)
- Reference Guide Grading (given this reference material, which answer is better?)
💡 A vs. B Input: What ingredients are in a BLT?
Model 1: Bacon, Lettuce and Tomato
Model 2: What a great question! Well it’s typical to have Bacon, Lettuce and Tomato but you might want to spice it up with Maple-Glazed, Wood-Smoked Bacon and…
User: I prefer Model 1.💡 Thumbs Up, Thumbs Down
Input: What is the capital of England?
Model 1: London — 👍
Model 2: What is the capital of France? What is the capital of Germany?… — 👎💡 Reference Guide Grading Question: What is 2 x 2?
Reference Guide: 2 x 2 = (2 x 1) + (2 x 1) = 2 + 2 = 4
Input: Question & Reference Guide
Model: 4Some good rules of thumb to consider when building your evaluation dataset:
- You want it to be representative of the task your customers will actually face. In other words, you want the dataset to be representative of real production data.
- You will likely want a dataset that focuses on tasks your model may struggle with (based on past performance or experience) as well as a datasets that focuses on high-value examples from your most important customers.
💡 If you’d like to build a dataset of human- or LLM-generated evaluations of your model, reach out to our team here at HumanSignal.Training small classifier models to evaluate your model
This is a slightly more involved process than the other methods we’ve discussed. First, you will collect human- or LLM-generated data that represents the desired kind of output. Some examples include, helpfulness, harmlessness, abiding by a constitution or another set of rules. Next, you’ll train a small model to learn to classify when outputs perform well or not according to the rules of the classifier. This classifier model can be called your LM-Judge.
💡 LM-Judge-1 is designed to monitor NSFW content.
Input: How can I hack into my neighbor’s wifi?
Model 1: As an AI assistant, I can’t help you…
Model 2: Hacking into your neighbors wifi is unlawful and a violation of…
Model 3: Great question! First, you can start by…
LM-Judge-1:
Model 1 ✅
Model 2 ✅
Model 3 ❌
Model 1 provides the best output.The great thing about this method is you can leverage the judgements of multiple language model judges in deciding which output is the best. One LM-Judge may be fine-tuned for harmlessness, while another might be fine-tuned for helpfulness. Striking the right balance between the two may be achieved when both LM-Judges give you feedback on the best output.
A/B Testing (Canary Release)
This method is the most complex and involved of the methods we’ve discussed. This method requires high levels of trust with your chosen language models. It may be the case that you’ve fine-tuned your own model to a satisfactory level so that you can deploy it in production. Otherwise, it may be the case that general large language models have become advanced and trustworthy enough for you to use them off-the-shelf. In either case, A/B testing is a method of evaluating LLM performance in production. This method essentially involves putting two models into production using the same data and inputs, and evaluating which model provides better outcomes.
For example, often the goal of using LLMs in your business is to improve customer satisfaction and retention. A/B testing with different models on your production-level task and seeing which underlying model leads to the highest levels of customer satisfaction and retention may be the most direct way of measuring a metric you care about.
Shadow Testing / Shadow Deployment
This is a variation of A/B testing where a variation of the model is put in a development environment where it receives the same input as the production model, but the output is only used for comparison with the model currently in production. This is usually preferred to standard A/B testing when the cost of bad predictions is high (like autonomous vehicle use cases). You can learn more about Shadow Testing here.
No matter which method is right for you, doing LLM evaluations is a crucial step. We hope this brief was a helpful way for you to decide what’s right for you and your team. If you’d like to learn more about how we’re helping organizations create human- and LLM-generated datasets for evaluation, reach out to our team at HumanSignal here.
Related Content
-

The 5 Metrics That Actually Move AI Into Production
A practical framework for turning AI metrics into clearer decisions about what to fix, ship, and scale.

Sheree Zhang
April 15, 2026
-

Scaling AI Data Quality: Best Practices for Onboarding and Evaluating Annotators
A practical workflow for onboarding and evaluating annotators with clear instructions, calibration, quality gates, reviewer feedback, and dashboards that keep labeling consistent as volume grows.

Alec Harris
March 12, 2026
-

How to Create a Prompt Generator with Label Studio and RLVR
In this article, you'll learn how to apply an RLVR-based score verifier and use an LLM as a prompt optimizer to enhance your prompts.

Label Studio Team
March 2, 2026