The Last Mile of AI: Agent Evaluation with Domain Experts

Most AI teams eventually hit a wall, not because their models stop learning, but because they stop understanding why their agents fail. You can instrument every part of a pipeline, trace every LLM call, and log every response, yet still have no clear path from “what went wrong” to “how do we fix it.” This is the last-mile problem in AI: the gap between observability metrics and decisions that improve real-world performance.
Closing that gap means turning raw traces into confident, actionable calls about what to fix and why. LLMs can triage simple judgments; humans add the most value when cases are complex, nuanced, or high-stakes, where correctness depends on domain standards, edge conditions, policy, and context. The most effective agent-evaluation workflows pair observability with domain expertise from the start.
This post maps that workflow and the hand-offs that make it work: monitor real use, review with experts, deliver a concise report, ship the changes, then measure lift on the same ground.
How teams are evaluating agents today (and why they stall)
Most teams follow one of two workflows in production today, and both stall in predictable ways. In the first, engineers review traces on their own and ship changes, but “right vs. wrong” decisions are outside their domain. In the second, experts are pulled into a technical tool, which turns review into slow, error-prone summarization. Both paths generate activity without a reliable hand-off that explains why failures happened and what to change next.
| Workflow A | Workflow B |
| Deploy → Monitor → Engineer review → Engineer changes → Deploy | Deploy → Monitor → Expert review in a technical tool → error prone, inefficient work to gather/summarize issues → Engineer changes → Deploy |
Most evaluation workflows stall for two reasons: they miss structured human-in-the-loop context, and they lack a mechanism to turn findings into actionable feedback, both for improving the model and for continuously improving the observability measures used to judge it. Engineers’ tools are excellent at showing how the system behaved (traces, timings, components), but they don’t establish whether it was the right outcome or what to change next.
A domain expert’s view looks at context, correctness, and rationale. They know whether a legal assistant agent applied the right statute, whether a healthcare model interpreted a symptom accurately, or whether a finance bot made a compliant recommendation. They also spot operational realities engineers often miss: whether the agent chose the right tool or data source for the task, whether it hallucinated or promised features the product does not support, and whether it followed business rules, privacy constraints, and escalation paths.
To connect these views, teams need an expert review workspace with rubrics and shared error taxonomies, plus a clear hand-off: a concise Domain Expert Report and training/eval artifacts that flow back into both the model pipeline and the observability stack (for better slices, thresholds, and regression checks). Without that bridge, pushing expert review into observability stays slow, error-prone, and low-signal.
Why observability tools aren’t enough
This is not about replacing technical tools. It is about extending them with a human intelligence layer that turns traces into decisions.
| AI Engineer | AI Domain Expert | |
| Primary tool | Observability systems like LangSmith or Braintrust | Human-in-the-loop systems like Label Studio |
| Focus | Technical debugging, execution timing, latency, and system metrics | Correctness, reasoning, and domain-specific judgment |
| Output | Logs, traces, and error reports | Annotated examples, error taxonomies, and suggested improvements |
| Goal | Understand how the system behaved | Understand whether the system made the right decision |
| Next action / hand-off | Reproduce, diagnose, and measure changes | Prioritize fixes and hand engineering a concise report to implement (vN → vN+1) |
Engineers measure how the system behaves. Experts judge what the behavior means and whether it is desired and correct. Together, via the report and artifacts, they close the feedback loop to improve model performance. The structured labels can also flow back into observability dashboards and regression checks to track impact over time.
A better workflow: Monitor → Review → Report → Ship
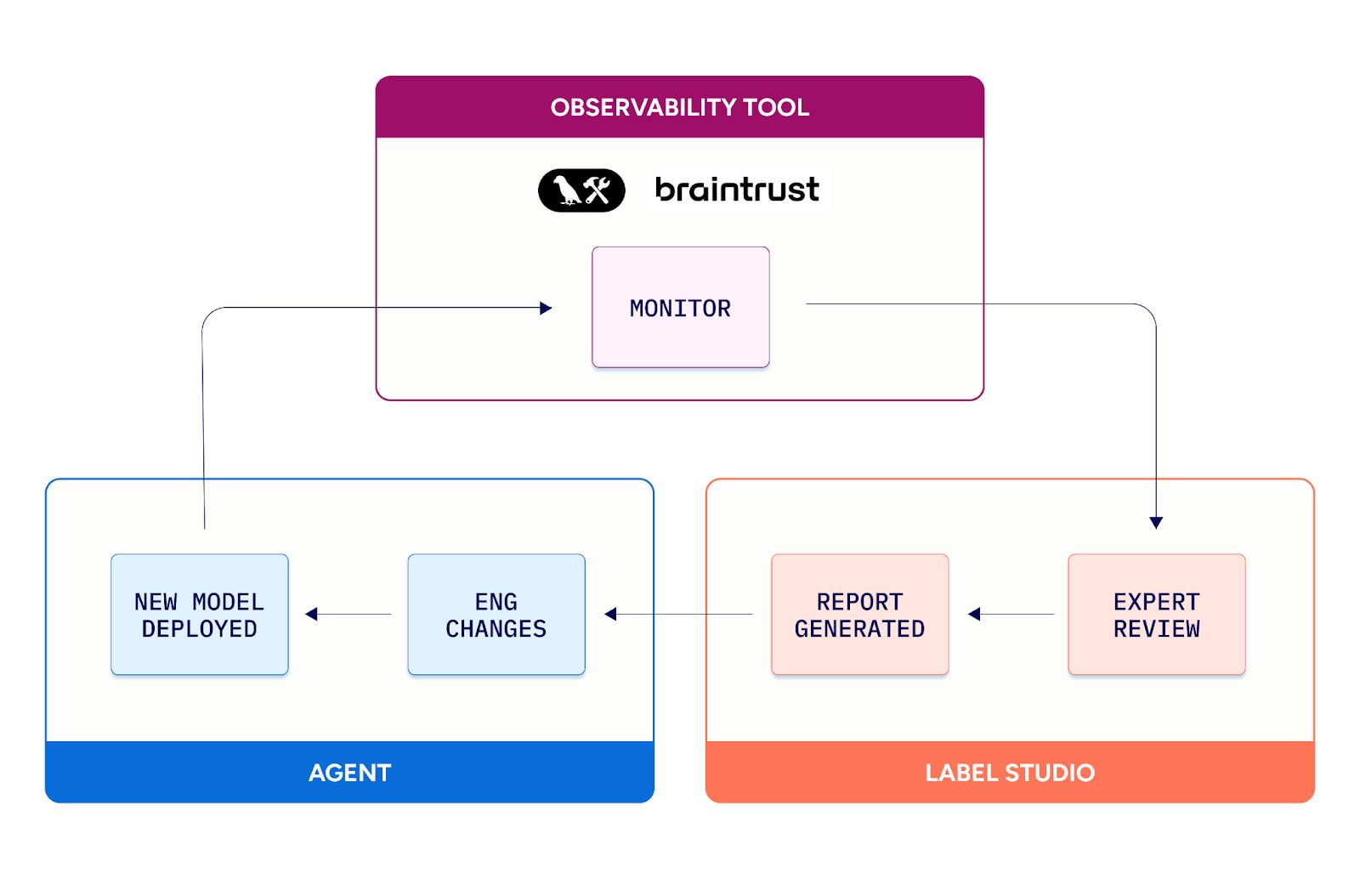
See the full stage-by-stage table in the appendix.
Our proposed structure is meant to turn observability into action. Instead of leaving experts to sift through technical traces or engineers to guess at “what to change,” this workflow pairs monitoring with a purpose-built review step for SMEs and a concise hand-off to engineering.
Engineers curate a batch of runs and send them to an expert workspace like Label Studio. Domain specialists review each case, mark correctness, tag failure modes using a shared taxonomy, and add notes or suggested rules. The result is a structured Domain Expert Report and concrete artifacts that guide prompt, policy, retrieval, or finetune updates and then measures the lift on the same ground. In practice, it’s a lightweight cadence you can run on events, on a schedule, or around releases to keep progress visible and accountable.
At scale, batches don’t get emailed around, they’re routed to the right reviewers automatically. Reviewer assignment, load balancing, and scheduled review windows keep work evenly distributed, while consensus/QA rules ensure consistent signal before anything reaches engineering.
Workflow outputs
- Performance metrics aligned to customer KPIs, such as minimizing false approvals
- Failure-mode datasets engineers can retrain against
- The Domain Expert Report, ready for engineering to act on
How to implement the Domain Expert Report
The Domain Expert Report is intended to provide structured, actionable feedback, including:
- Benchmark datasets on product samples: Curated tasks that reflect real user scenarios, each labeled with expected outcomes and linked failure modes.
- Failure-mode ontology: Reason codes with short definitions and 3–5 anchored examples per code.
- Prioritization charts: Order by impact and effort. Show counts, recent trend, and an owner for each top item.
- Calibrated evals: Brief notes on graders used (rule or model-based), sample sizes, expert spot checks, and target thresholds.
Engineering ingests it as a single source of truth: each prioritized failure mode links to concrete examples, proposed domain knowledge, and acceptance criteria tied to KPIs. That makes the next changes explicit (prompt edits, policy updates, small finetunes) and traceable back to impact.
Store the report and datasets in the same repo or ticketing system you use for releases so owners, status, and regressions are visible over time.When engineers and domain specialists meet in this steady review-to-deploy cadence, the organization moves beyond interesting dashboards to reliable progress.
Appendix: Workflow Table (Reference)
For implementation and hand-off planning, use the reference below. It mirrors the diagram, stage by stage.
| Stage | Who | What happens | Output / hand-off |
| Deploy | Engineering | Ship current agent (vN) | Production traffic begins |
| Monitor | Engineering | Observe traces, KPIs, drift in observability tools | Targeted runs to sample |
| Expert Review (for SMEs) | Domain experts | Review sampled runs in a product built for SMEs | Correct/Partial/Wrong labels, failure modes, brief rationales |
| Report | Domain experts | Convert findings into a concise, actionable hand-off | Domain Expert Report (prioritized failure modes, proposed domain knowledge, acceptance criteria) |
| Engineering changes | Engineering | Implement updates (prompt/policy/retrieval/finetune) and version | vN → vN+1, ready to redeploy |
Ensuring Agents Earn Trust, Not Just Accuracy
The last mile of AI comes from a repeatable habit where engineers and domain experts turn traces into decisions and decisions into verified improvements.
Agent evaluation provides the bridge: monitor real use, send a representative slice to expert review, name failures in a shared language, hand off a concise report with owners and acceptance criteria, ship the changes, and measure on the same benchmarks to prove the lift. When that cadence holds, progress is visible, attributable, and tied to customer goals. That is agent evaluation with domain experts, and that is how the last mile of AI gets closed in production.
Related Content
-

The Sweet Science of Subjective Evaluation
What chocolate tasting taught us about human annotation, data quality, and evaluating AI at scale.

Micaela Kaplan
April 16, 2026
-

How to evaluate AI agents in production
Learn how to evaluate AI agents in production by moving from single-turn metrics to trajectory evaluation using human-in-the-loop trace review.

HumanSignal Team
March 25, 2026
-
Do you need an agent evaluation framework?
Static tests fail multi-step AI agents. Learn why the eval lie causes silent failures and how a trajectory-based evaluation framework fixes it.
HumanSignal Team
March 11, 2026