3 Annotation Team Playbooks to Boost Label Quality and Speed

Bringing an ML model to production means balancing performance with cost. The same balancing act applies to data labeling. Whether you’re training your first model or iterating for the 100th time with a challenger model, high-quality labels at the lowest cost remain the goal.
Many teams assume they need to choose between quality and efficiency. Focus too much on quality, and you may not make it to market fast enough. Prioritize speed, and quality may suffer. But with the right tools and workflows in Label Studio, you don’t have to choose. You can optimize for both.
The best workflow depends on your annotators, resources, and problem space. And while there’s no one-size-fits-all solution, we’ve observed a few reliable patterns. In this post, we’ll:
- Briefly introduce how teams measure quality and efficiency
- Introduce a framework we use to better understand the makeup of different teams.
- Then we’ll use that framework to illustrate 3 emergent patterns we see and how you can best leverage Label Studio to maximize quality AND efficiency.
Looking for practical ways to structure your labeling team?
Download our free guide, 10 Simple Steps to Leading a Successful Labeling Team at Scale. It breaks down strategies for onboarding, QA, and scaling workflows that complement the ideas in this blog.
Assessing Quality and Efficiency
Before diving into the framework and playbooks, it’s worth providing context on how things like quality and efficiency are measured. Each of these topics is worth a deep-dive on their own — there are different methodologies and schools of thought and juicy conversations to be had. But let’s start with a broad overview and some simple examples.
Label Quality
We assess quality through two key lenses:
- Annotation Validity: Is the annotation correct? One simple proxy is the percentage of labels accepted by a reviewer or subject matter expert. For example, a review score of 90% means an annotator provides the correct answer 9 out of 10 times. However, this assumes there is always a "right" answer—something that isn't true for all use cases.
- Annotator Reliability: In subjective or ambiguous tasks, teams rely on consistency across annotators instead. Annotator Reliability is measured using Inter-Annotator Agreement (IAA), also called Inter-Rater Reliability (IRR). An IAA score of 90% means annotators agree on 90% of the data and disagree on 10%. In highly ambiguous problem spaces, IAA often serves as a proxy for validity.
Labeling Efficiency
Efficiency is about reducing annotation time without compromising quality. From a business standpoint, this affects:
- Time-to-market: The faster your team annotates, the faster you train and deploy.
- Labor costs: Reducing annotation time directly lowers spend.
For example: If labeling 1M images takes 10 minutes per task at $10/hour, that’s 166,667 hours and over $1.6M in labor. Speed matters.
The process of increasing both quality and efficiency looks different depending on who your annotators are and your team structure. Which brings us to our framework: the Spectrum of Annotators.
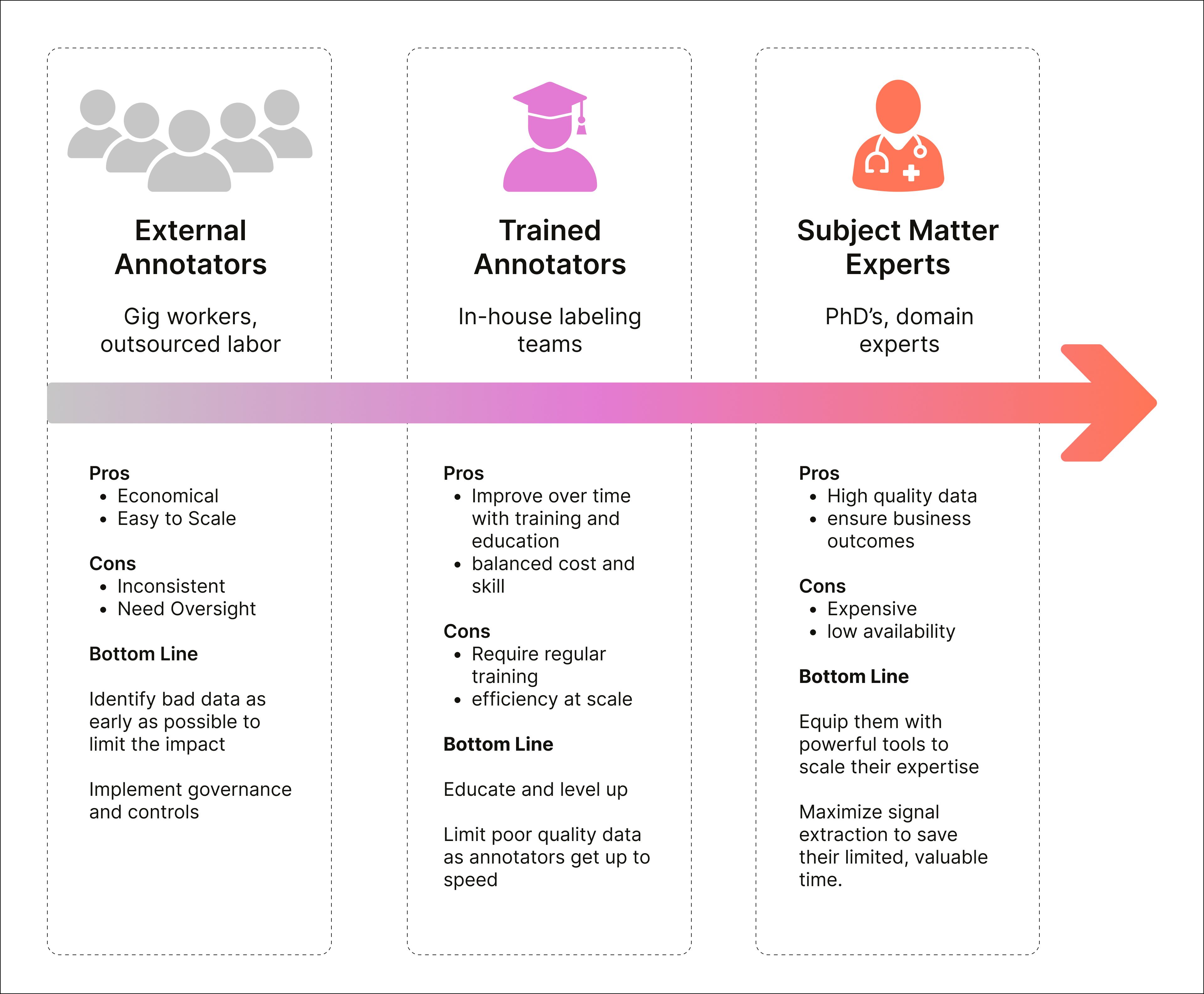
Spectrum of Annotators
Labeling data is not as simple as the demos let on. Identify a bird, segment a stop sign, sure, those are relatively straightforward. But enterprises are venturing into unknown spaces—problems that are unsolved, rapidly shape-shifting, and ever expanding in our increasing multi-modal world. An individual piece of data often needs multiple sets of eyes to ensure accuracy across pre-labeling, labeling, and reviewing. In aggregate, data labeling is a team sport.
So, the question is, what does your team look like? To simplify, we often see data annotators and reviewers spread out across a spectrum of expertise.
Pattern 1: Max Human Power
A large outsourced team supported by a small in-house group
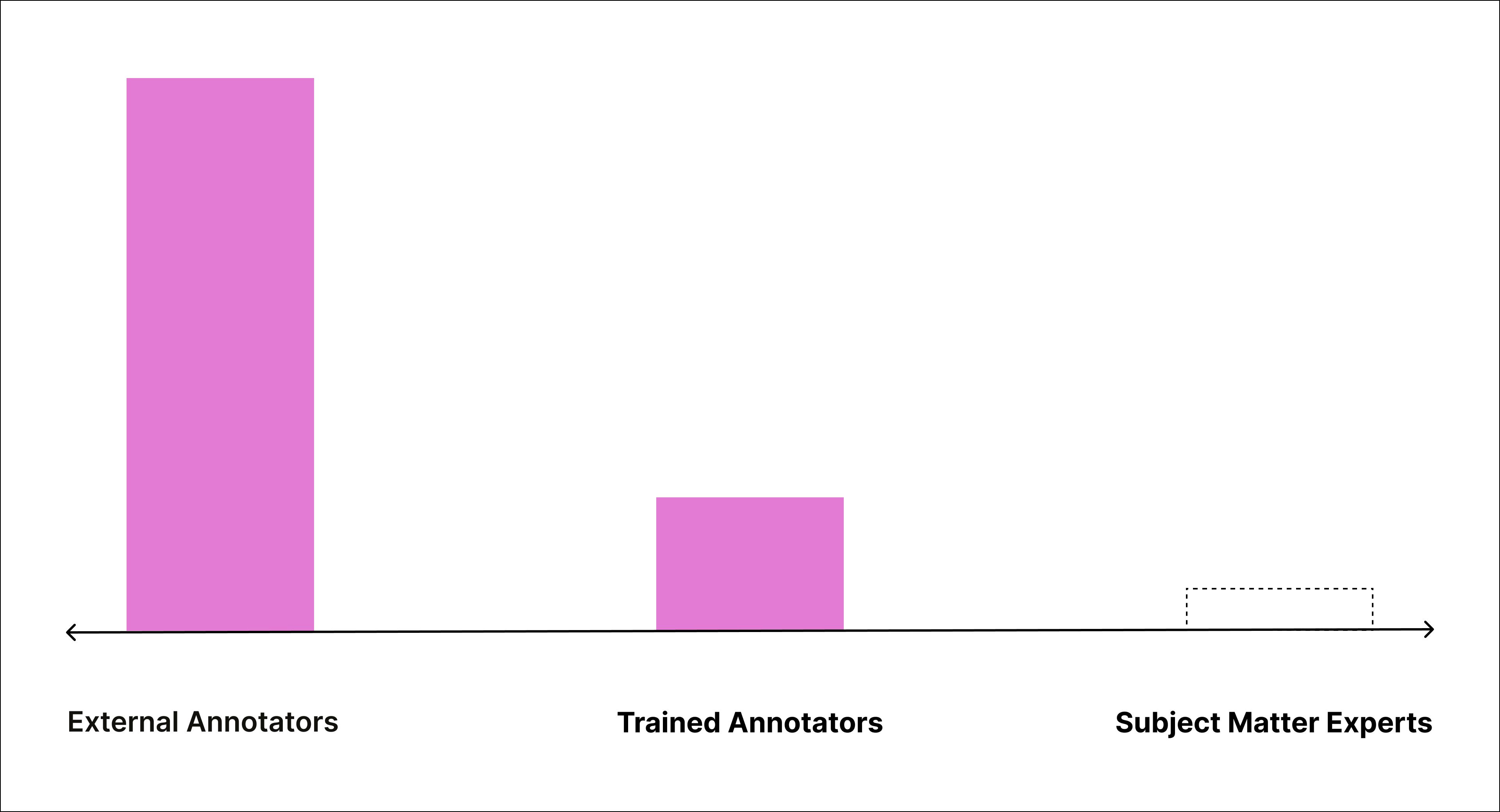
In this setup, we often see a large outsourced data labeling team supported by a small internal group and, occasionally, a few SMEs. This structure is common in use cases like content moderation, where annotation needs to scale quickly but still requires oversight from people due to a fast-moving environment—changes to community guidelines, new legislation, emerging terminology in an adversarial space.
Quality is achieved by increasing the number of people that annotate each task and using the in-house team to handle disagreement, a strategy often referred to as a "2+1" approach. Efficiency comes from the ability to scale the outsourced workforce.
| Challenge | Label Studio Solution |
| Low annotator reliability | <strong>High Overlap + Agreement Scores:</strong> Send each task to multiple annotators and measure where they agree. Helps detect confusing cases early and flags low-quality inputs. |
| Spam or biased inputs | <strong>Spam Prevention + Identity Hiding:</strong> Block rapid submissions, limit over-contribution, and anonymize annotator names to prevent familiarity bias in review. |
| Difficult task routing | <strong>RBAC + Auto Task Distribution:</strong> Automatically send tasks to the right users while keeping external and internal teams separated and organized. |
| Overloaded in-house reviewers | <strong>Low Agreement Strategy + Performance Dashboard:</strong> Automatically escalate only ambiguous tasks to reviewers and surface top/bottom performers to focus coaching efforts. |
Pattern 2: In-House Balance
A trained internal team with SME support

This pattern relies on a medium-sized in-house annotation team supported by a smaller group of SMEs who drive continuous training and quality assurance. A common use case here is document processing, for example, a financial institution that allows clients to upload forms through a secure portal. Annotation tasks can range from general document classification to fine-grained OCR with region-level detection.
Because these industries evolve based on consumer trends, regulation, and internal business priorities, continuous education is critical. Teams must identify which annotators need training, what educational content needs updating, and which parts of the interface should evolve. At the same time, SMEs must be directed toward tasks that make the most of their expertise.
Common Challenges and Label Studio Solutions
| Challenge | Label Studio Solution |
| Annotators ramping up on complex topics | <strong>Annotator Evaluation:</strong> Gate new contributors until they hit an accuracy threshold to ensure quality before production. Flag errors for coaching annotators as they ramp up. This helps educate teams without slowing down production. |
| SME review is hard to prioritize | <strong>Agreement Scores:</strong> Use disagreement data to escalate only unclear tasks to SMEs. Keeps them focused on what matters. |
| Difficulty monitoring progress and quality across annotators | <strong>Members Dashboard:</strong> Get a clear view of annotator accuracy and performance trends over time. Identify who’s improving, who may need intervention, and where to focus training efforts to support ongoing education and skill development. |
| Feedback lacks clarity and context | <strong>Comments</strong> let reviewers leave contextual, in-task notes so annotators can understand exactly what to correct and learn from real examples. |
| Annotation is slower than expected | <strong>Prelabels</strong> give annotators a head start, so they’re not starting from a blank screen on every task. <strong>Performance Dashboards</strong> help identify who’s working slowly, so you can provide targeted coaching to improve speed and reduce bottlenecks. |
Pattern 3: Mighty Team of SMEs
Domain experts handling labeling and review themselves
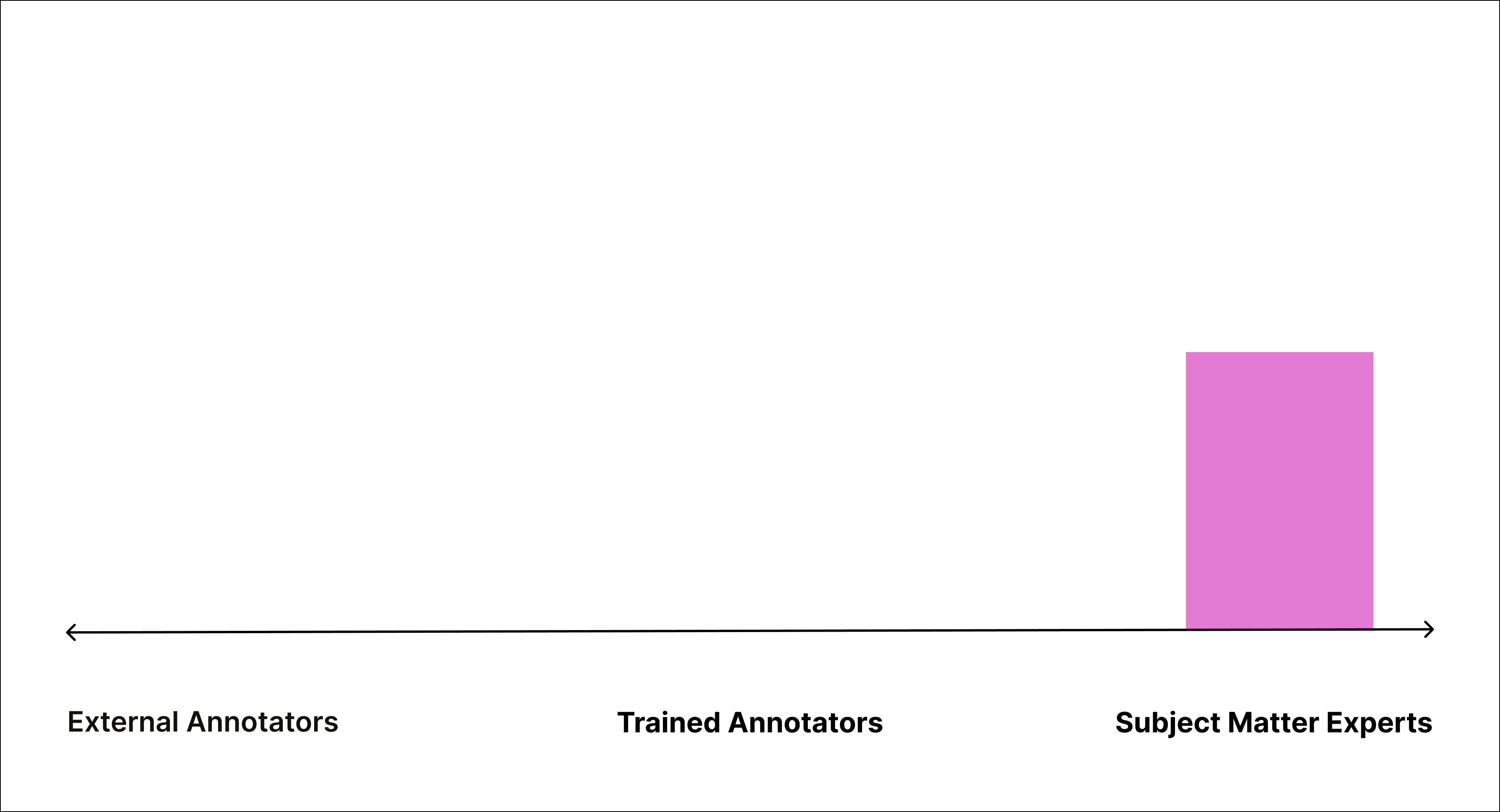
Here, a medium-sized team of internal domain experts manages the entire labeling process, from annotation to review. A common use case for this pattern is medical imaging classification or detection, where labeling tasks often require clinical expertise, and in many cases, credentials like PhDs or board certification. These tasks are not only complex but often subject to regulatory oversight, making subject matter expertise a non-negotiable requirement.
The use cases that fit this pattern tend to be complex and high-stakes. Tasks often require deep expertise and may take several minutes or even hours to complete. Since SME time is expensive and limited, efficiency becomes the key constraint. Reducing time per task, supporting quick collaboration, and surfacing the highest-value tasks are all essential to success.
Common Challenges and Label Studio Solutions
| Challenge | Label Studio Solution |
| Time-consuming annotation and high-cost SME effort | <strong>Prelabels + Prompts:</strong> Give your SMEs a head start with prelabels so they’re not starting from scratch. Prelabels can be generated by connecting a model via the ML backend or by using a custom prompt with an LLM. *For high-cost expert teams, the time savings quickly add up. A 10% reduction in labeling time—for example, from 166,667 to 150,000 hours—can lead to significant cost savings, especially when SME time is valued at $100+ per hour. |
| Inefficient collaboration and peer review | <strong>Commenting:</strong> Leave in-task comments so SMEs can ask for second opinions, share rationale, and collaborate without switching tools—creating a quality feedback loop that supports shared understanding and more consistent labeling. |
| Difficulty scaling expert decisions across similar tasks | <strong>Bulk Labeling + AutoLabel with Prompt Tuning:</strong> Help SMEs scale their expertise efficiently. Use Bulk Labeling to quickly apply the same decision across filtered examples. For even greater reach, let experts refine a prompt against Ground Truth data, then use LLMs to label similar tasks accurately at scale. |
| Dataset bias risks | <strong>Project Dashboard:</strong> Visualize label distribution to catch overrepresented or missing classes across your dataset. |
Optimize Your Annotation Workflow — No Matter the Team
Effective data labeling isn’t just a technical detail—it directly shapes a model’s real-world impact, affecting customer experience and business outcomes. Label Studio is built to adapt to your workflow, no matter your team’s shape. Connect with us to see what’s possible and start a free trial.
Related Content
-

The 5 Metrics That Actually Move AI Into Production
A practical framework for turning AI metrics into clearer decisions about what to fix, ship, and scale.

Sheree Zhang
April 15, 2026
-

Scaling AI Data Quality: Best Practices for Onboarding and Evaluating Annotators
A practical workflow for onboarding and evaluating annotators with clear instructions, calibration, quality gates, reviewer feedback, and dashboards that keep labeling consistent as volume grows.

Alec Harris
March 12, 2026
-

How to Create a Prompt Generator with Label Studio and RLVR
In this article, you'll learn how to apply an RLVR-based score verifier and use an LLM as a prompt optimizer to enhance your prompts.

Label Studio Team
March 2, 2026