The Virtuous Cycle of Using Your Brain Alongside GenAI - A Case Study

Recently I experienced a case where, had I blindly followed GenAI, I would’ve provided terribly incorrect information to a customer. Last week, I was attempting to help a customer create a Custom Agreement Metric. So I consulted our AI support agent which I use daily. I asked to generate a toy example as a starting point and found something interesting – I was getting a wrong answer. Our agent was saying we didn’t offer that functionality, yet I know we do.
GenAI can feel like magic. But without enough subject matter expertise, it can end up being a monkey’s paw instead. We’ve all heard horror stories of vibe-coded applications irreparably buried in tech debt. So the prevailing wisdom is: yes, GenAI is an incredibly powerful tool, but one that is most effectively wielded when there’s an expert in the loop.
Here’s how one small interaction led to three meaningful improvements to our GenAI-based support agent and why human-in-the-loop workflows are the not-so-secret sauce for reliable AI.
Win #1: Diagnosing a Silent Failure in the RAG Pipeline
I was helping a customer create a Custom Agreement Metric and turned to our support agent for a toy example. The answer I got back? Completely wrong. It said we didn’t support that functionality, which I knew wasn’t true.
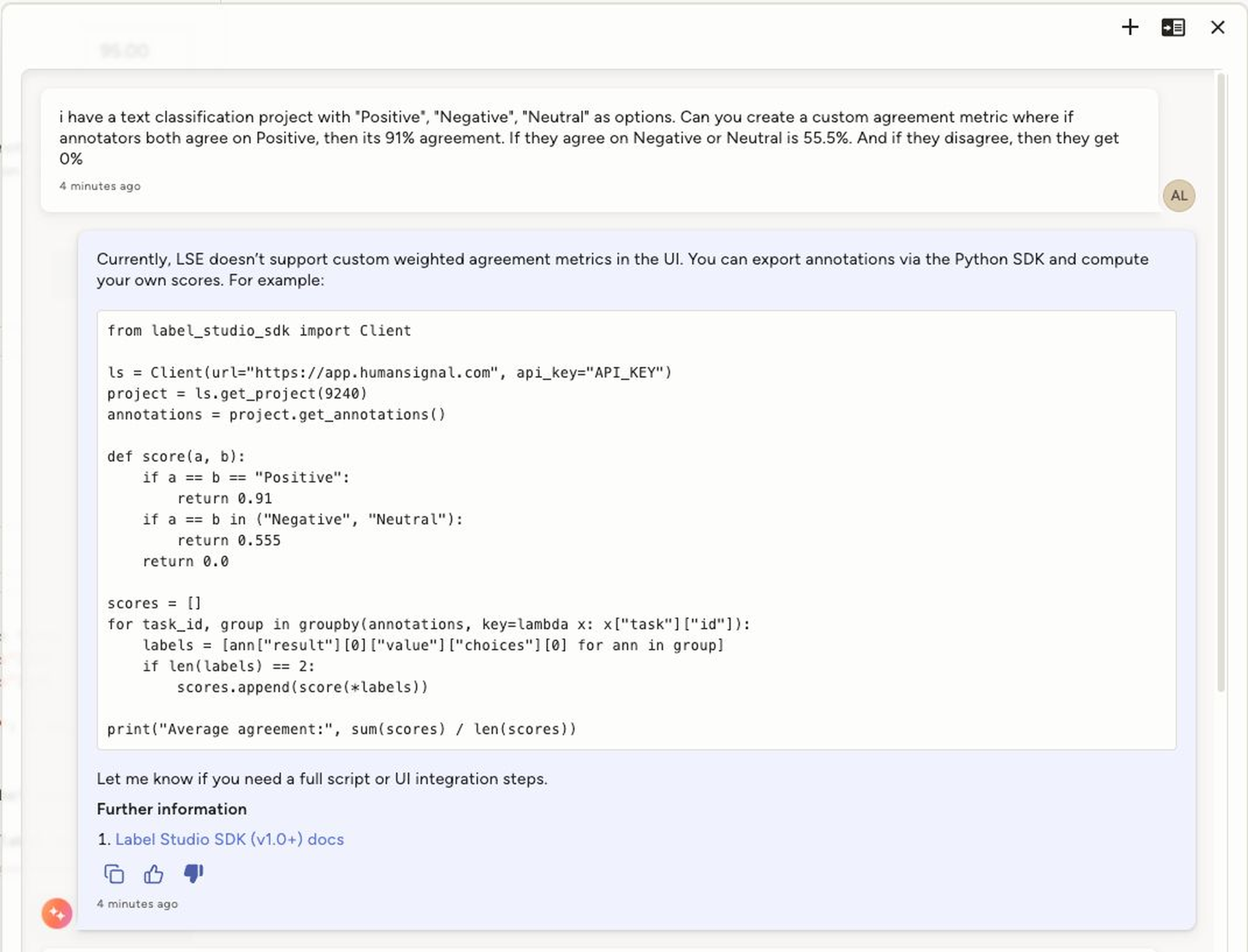
That incorrect response kicked off a quick, fruitful discussion internally. We discovered that a knowledge base source in our RAG pipeline had silently failed. First step: reboot the source. Five minutes later, the response improved.
To prevent this kind of silent failure from misleading users in the future, we added a guardrail to our agent: now we check for the presence of all expected sources before generating an answer. If anything is missing, it refuses to respond and serves a helpful error. That makes our Ask AI feature more error-resistant.
Result: The agent now checks for missing sources before responding. This prevents silent failures, ensures fewer errors, and improves response accuracy.
Win #2: Fixing Broken Docs That Generated Poor Responses
With the knowledge base fully back online, I asked the agent again for a toy example: whenever two annotations are labeled “Positive” sentiment, return a 91% agreement score, if not return 55.5%.
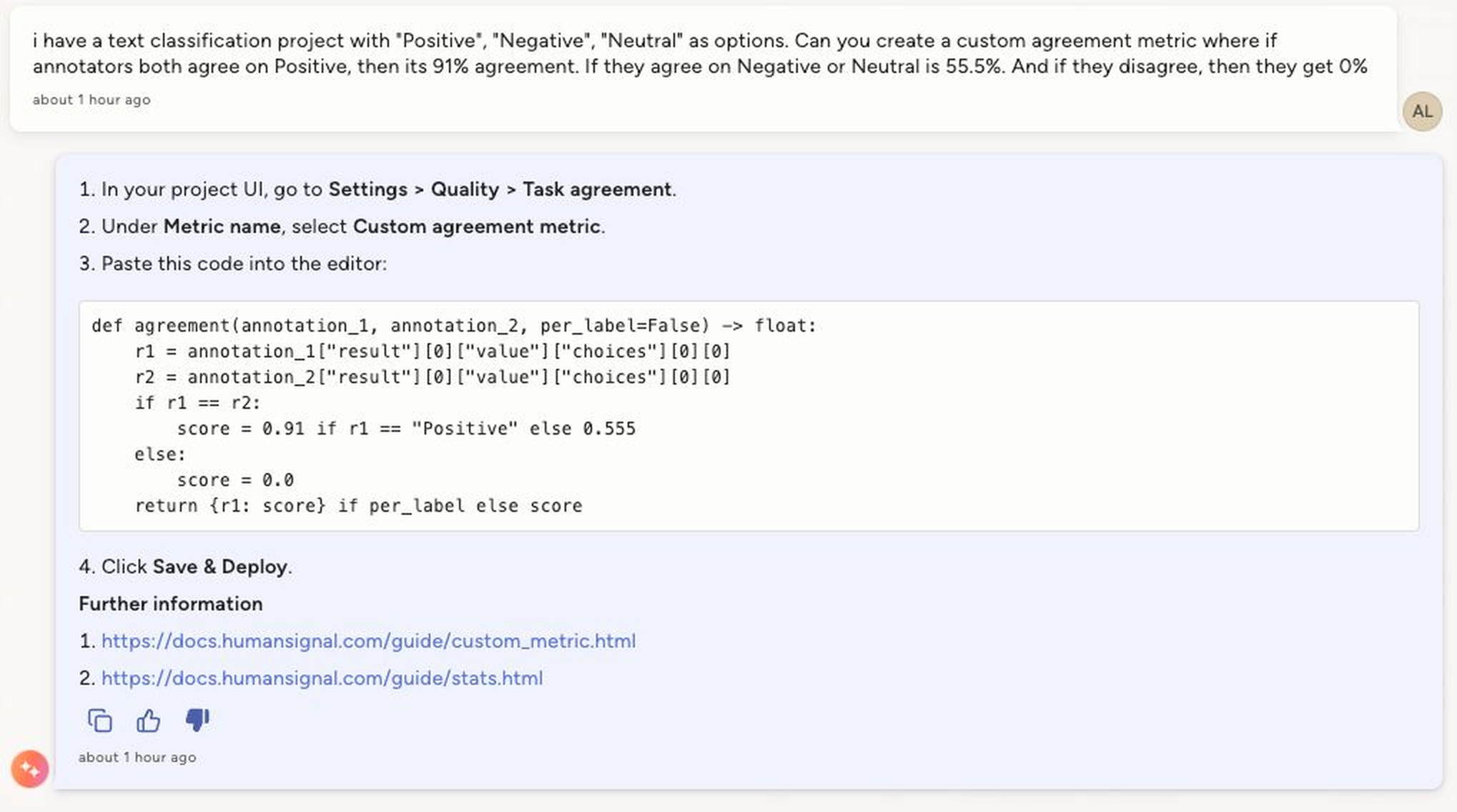
However, when I tested it out with a couple annotations marked “Positive”, the agreement metric came back at 55.5%. See our new Task Summary feature below:
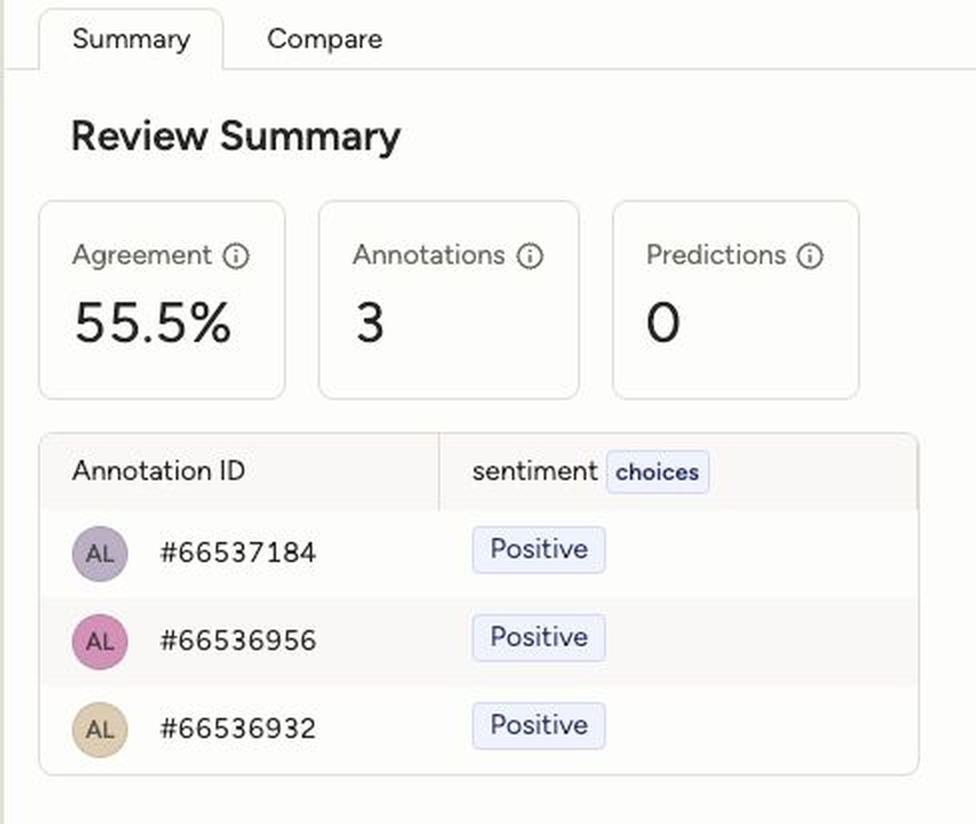
So, I consulted the docs our agent included in its response. After digging with a teammate, we figured out the issue: the docs themselves were wrong. They 1) failed to provide enough context with a valid labeling configuration, and 2) incorrect syntax was used in the example: it included “[0][0]” instead of the correct “[0]”. These two issues essentially ensured the agent was responding with incorrect information. Here’s a screenshot from the old docs:
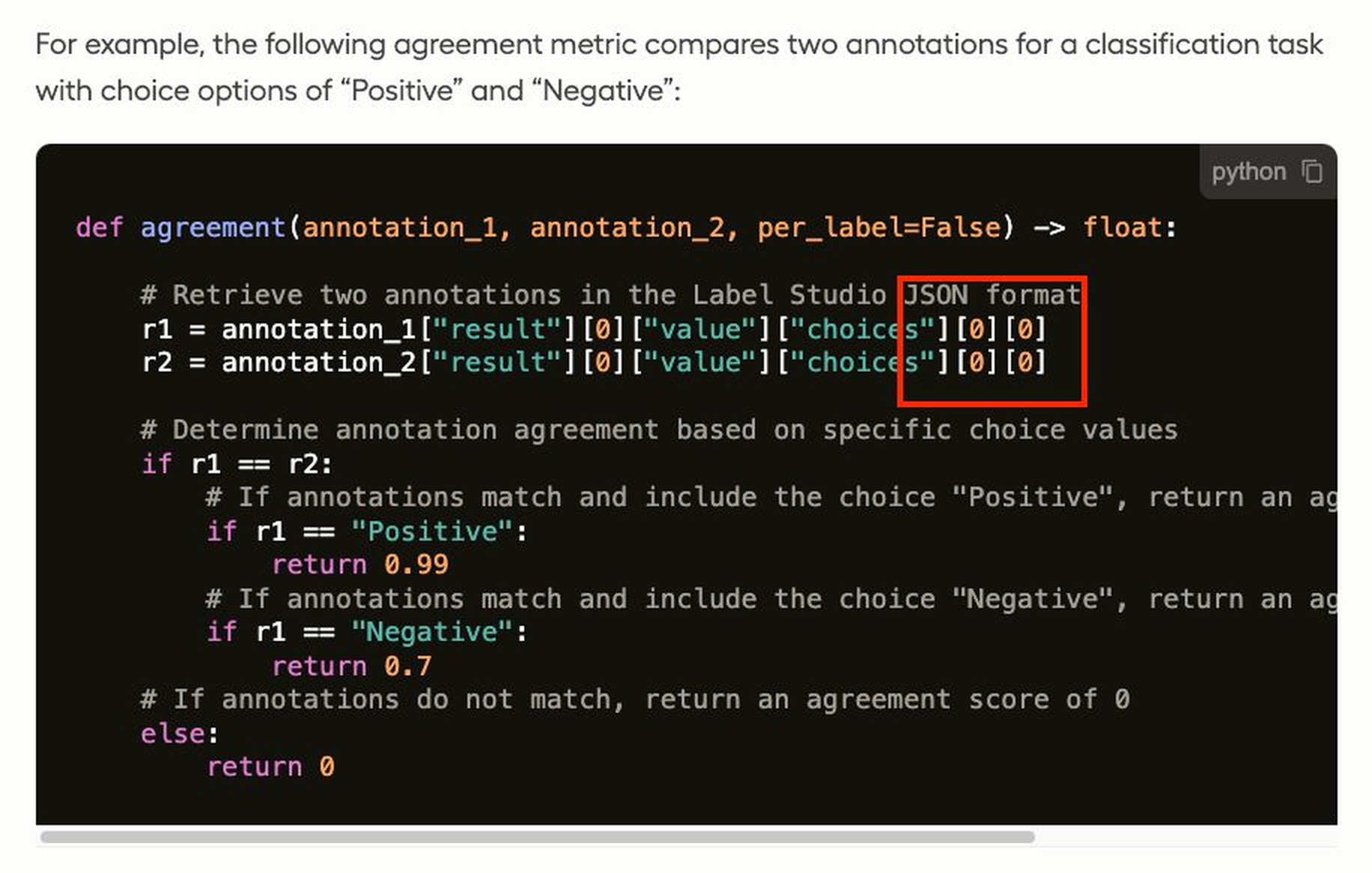
So, we updated our docs, which in turn updated our support agent’s knowledge base.
Result: Our docs in that section are correct, more informative, and most importantly, our agent provides correct information about Custom Agreement Metrics. Fixing the syntax and adding context resolved the confusion.
Win #3: Benchmarking to Future-Proof our Agent
Fixing today’s issue is good. Protecting against tomorrow’s regression is even better.
We added a generalized question and answer about custom agreement metrics to our support agent’s benchmark test set. That means in the future, if we experience drift in user behavior or are trying to upgrade our base model, we'll have confidence that we won’t be caught off-guard by a regression in this area.
Result: A smarter, more future-proof system, backed by structured evaluation.
What This Taught Us
This case study is a microcosm of what it’s like to constantly improve production-level GenAI. Releasing an agent to production is not a finish line. It’s the start of a virtuous feedback loop.
Subject matter expertise is what turns a brittle model into a robust system. It’s how you:
- Create a fault-tolerant RAG pipeline
- Improve documentation
- Build and bolster benchmarks that ensure accuracy over time
That’s the real magic: using your brain alongside the model, again and again. We’ve found both you and the model improve.
If you’re interested in setting up your own benchmarks to keep your models accurate and evolving, check out our AI Benchmarking series. And if you want to explore the features mentioned above, you’re always welcome to start an enterprise trial.
Related Content
-

The 5 Metrics That Actually Move AI Into Production
A practical framework for turning AI metrics into clearer decisions about what to fix, ship, and scale.

Sheree Zhang
April 15, 2026
-

Scaling AI Data Quality: Best Practices for Onboarding and Evaluating Annotators
A practical workflow for onboarding and evaluating annotators with clear instructions, calibration, quality gates, reviewer feedback, and dashboards that keep labeling consistent as volume grows.

Alec Harris
March 12, 2026
-

How to Create a Prompt Generator with Label Studio and RLVR
In this article, you'll learn how to apply an RLVR-based score verifier and use an LLM as a prompt optimizer to enhance your prompts.

Label Studio Team
March 2, 2026