Building a RAG System with Label Studio
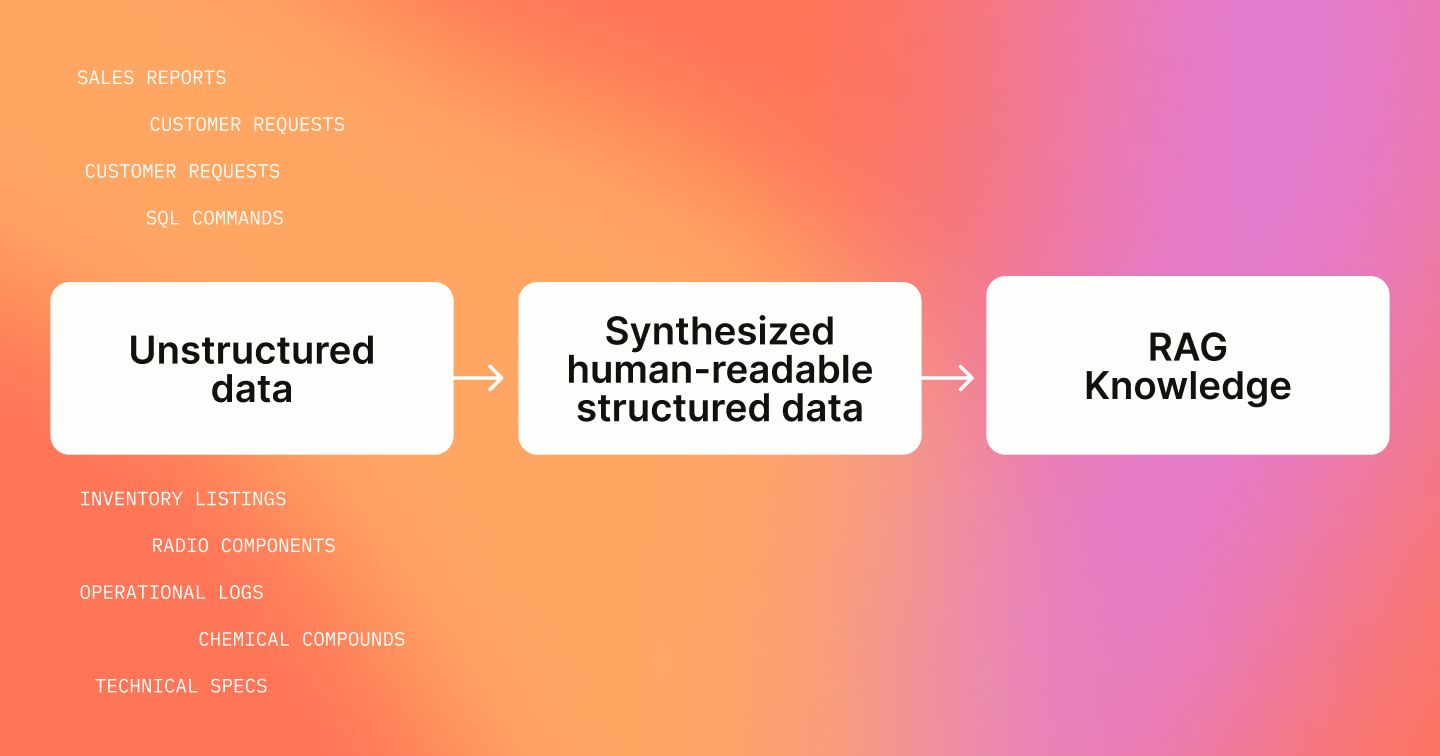
Retrieval Augmented Generation (RAG) is a great way to embed proprietary or specific knowledge in a Large Language Model (LLM). By providing sets of question-and-answer (QA) pairs from your data, you can build a RAG QA system that helps users find the answers they need. However, obtaining these QA pairs is a challenge. A growing best practice in industry is to synthesize Q&A pairs from domain data to improve RAG performance [Gretel, Huggingface]. These synthetic Q&A pairs serve both as evaluation benchmarks and as training data for retrievers, especially when the initial data source is messy and unreliable.
While developing the AskAI feature, a RAG-based agent designed to answer user questions in Label Studio, we quickly recognized that the data was too messy to be useful and required a more effective approach to training the system.
In this article, we’ll dive into our process of building a RAG system, leveraging Label Studio and Label Studio’s Prompts feature to synthesize datasets and ensure data quality. This can guide building other production-driven RAG systems like this.
Step 0: Breaking down the Q&A Problem into Subtasks
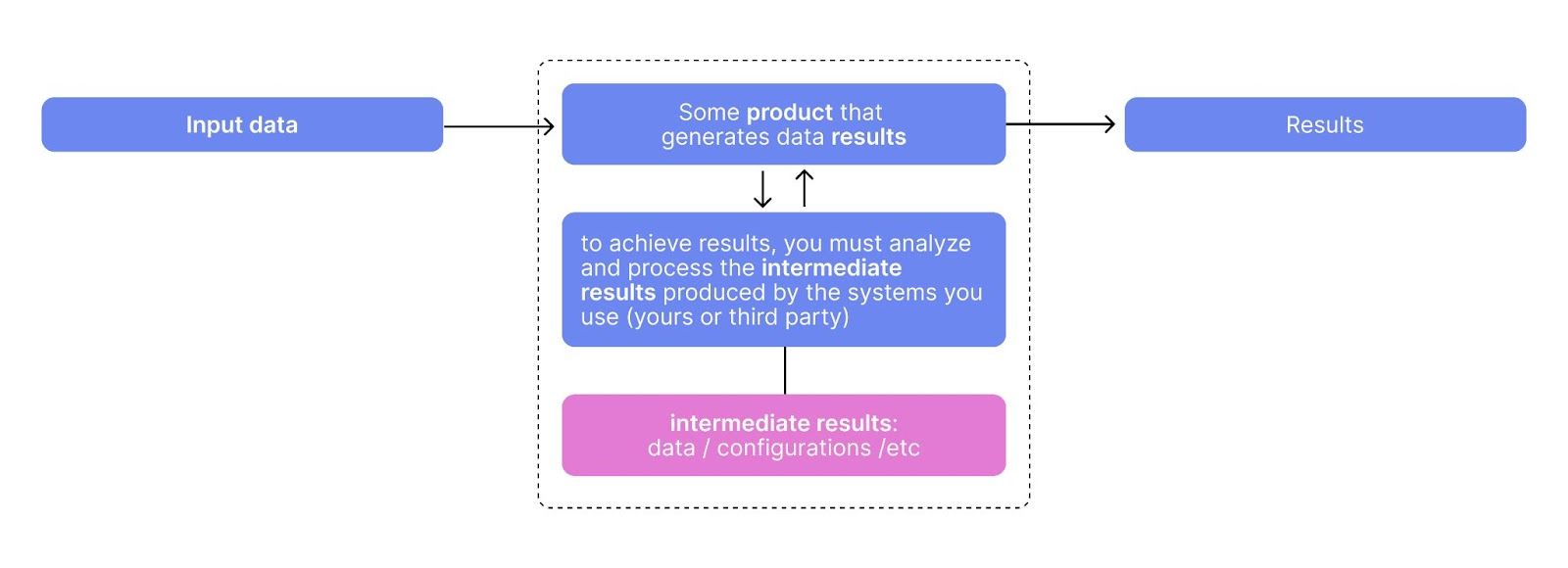
Before building a RAG system, we needed to rethink the problem at hand. We found that asking a RAG system to solve an entire product task was ineffective. It was too complex, and the LLM-generated answers required human review. Asking the LLM to do too much led to lower-quality responses, slower compute times, and longer human evaluation cycles. Instead, we focused on subtasks that make up a whole task. These subtasks produced structured intermediate results, making the RAG system more effective and providing more data to work with.
For example, one of the important functionalities of the AskAI agent is the ability to generate labeling interfaces based on user prompts. To narrow down the general customer support problem, we extracted structured information from user questions and responses – such as validated labeling configurations and corresponding user descriptions about them – as intermediate results. We then converted these intermediate results into clear, human-readable narratives that illustrate user workflows and practical use cases. Breaking down the process into smaller, well-formatted subtasks significantly reduced the manual effort needed to ensure quality. Here is an example of the data we collected:
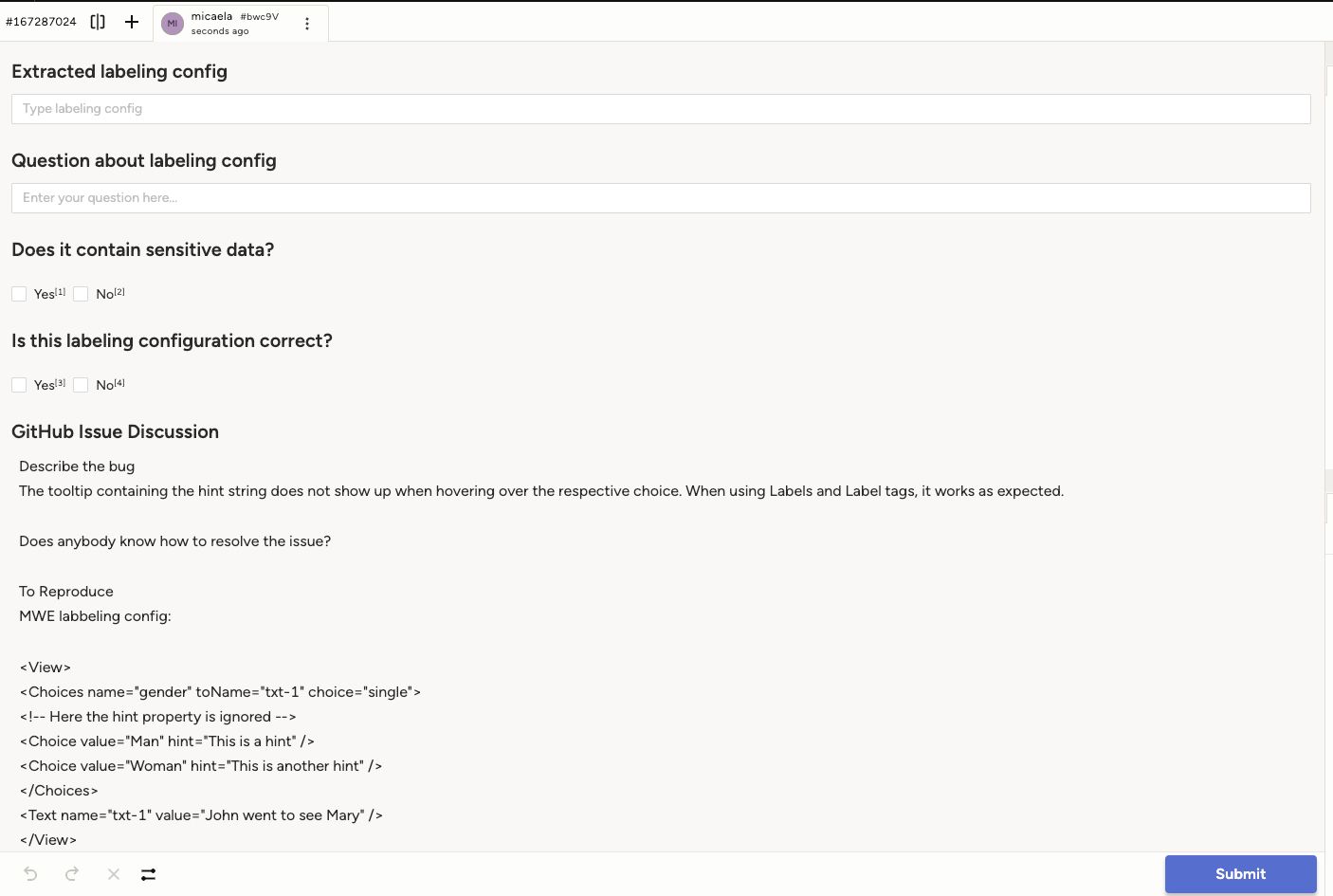
Step 1: Collect and Clean up the Data

After breaking down the problem into smaller training tasks, it was crucial to make sure the data was clean and ready. This meant removing any personal details, private information, and anything that wasn’t relevant, while also double-checking that the information we pulled out was correct.
In our situation, we looked through GitHub community discussions and took out the information we needed. We made sure everything was accurate and that no user's private data was included. Label Studio was really helpful in keeping the data clean. We could connect a Machine Learning model that finds personal information to the system to clean the data faster, and then have people check it to be extra sure. Label Studio's flexible setup made this whole process easier.
Here is the workflow implemented:
- Identify Subtasks: First, the overall problem was divided into smaller, manageable tasks such as labeling configurations and user discussions about them.
- Data Collection and Curation: Collected GitHub discussions were reviewed, and relevant issues were sorted out, whereas irrelevant items were removed.
- PII Data Cleaning: Personal and sensitive information was removed, and irrelevant content was discarded. A PII ML tool for finding personal information was connected to speed up the cleaning.
- Human in the loop Review: People checked the data to ensure accuracy after the automated cleaning. By using a Label Studio template as a starting point, doing this human in the loop review was straightforward.
Step 2: Synthesizing our Questions

Once the cleaned dataset of intermediate results was ready, we could generate QA pairs. LLMs excel at this task, and Label Studio’s Prompts feature made it even easier. With Prompts, we could run our cleaned data through an LLM using a predefined prompt and receive synthetic QA pairs directly in Label Studio, allowing for human supervision.
Following the previous findings, here is the structure of the optimal Synthetic Q&A data generation prompt identified in our experiments:
Input Data Description:
Include a description of all the input data fields from Label Studio tasks (in our case, GitHub messages). The LLM will be able to use them to generate the output we’re asking for (synthetic questions and answers).
Goal:
Next, define the task goal: “Synthesize pairs of a human question and extract a labeling configuration for the RAG system”. By explaining this in clear language, the LLM gets a better understanding of the goal at hand.
Expected Output Format
Then, list and define each JSON key that should appear in the Prompts’ output. This helps to ensure quality output data.
Few Shot Context
Finally, provide a few examples of the data that the LLM will use to generate this synthetic data, and the expected output
Here is the prompt preview:
This task involves generating data based on the provided Label Studio project details. The input includes the following variables:
- discussion: The Github discussion including the main text and comments.
My goal is to synthesize pairs of a human question and extract a labeling configuration for the RAG system.
The output should be a JSON object with the following keys:
- human_question: A user's question that might result in generating this labeling configuration. You have to make up a human question that will lead to the extracted labeling configuration:
* I'm working on a use-case to label extracted data from PDF documents. I'm going to be labeling key: value pairs and I don't have a set number of them for each document. Is there a way to dynamically allow adding additional key: value annotation fields?
* I wonder, is there a good way to create such matrix questions? Note that the criteria (to be rated relevant/irrelevant) are dynamic and depend on the question/answer.
* How do I make multiple questions within a labeling config?
* How can I setup config for multi-view image labeling?
* I might have several images of a chair, and I want to predict its class simultaneously like the image.
* I'm trying to create a labeling interface for named entity recognition, where a document has any number of entities, who have any number of properties.
- labeling_config: Extract a labeling configuration for Label Studio from Github discussion. It must be XML and starts and ends with the <View> tag.
- sensitive_data: Does this labeling configuration contains sensitive data? Yes or No. Try to remove it if it's possible.
- correctness: Is the extracted labeling config correct from the Label Studio perspective? Yes or No.
### Examples:
Input: {"discussion": "My problem is bla bla."}
Output: {"user_question": "{user_question}", "labeling_config": "{labeling_config}", "sensitive_data": "{sensitive_data}, "correctness": "{correctness}"}
# Github Discussion
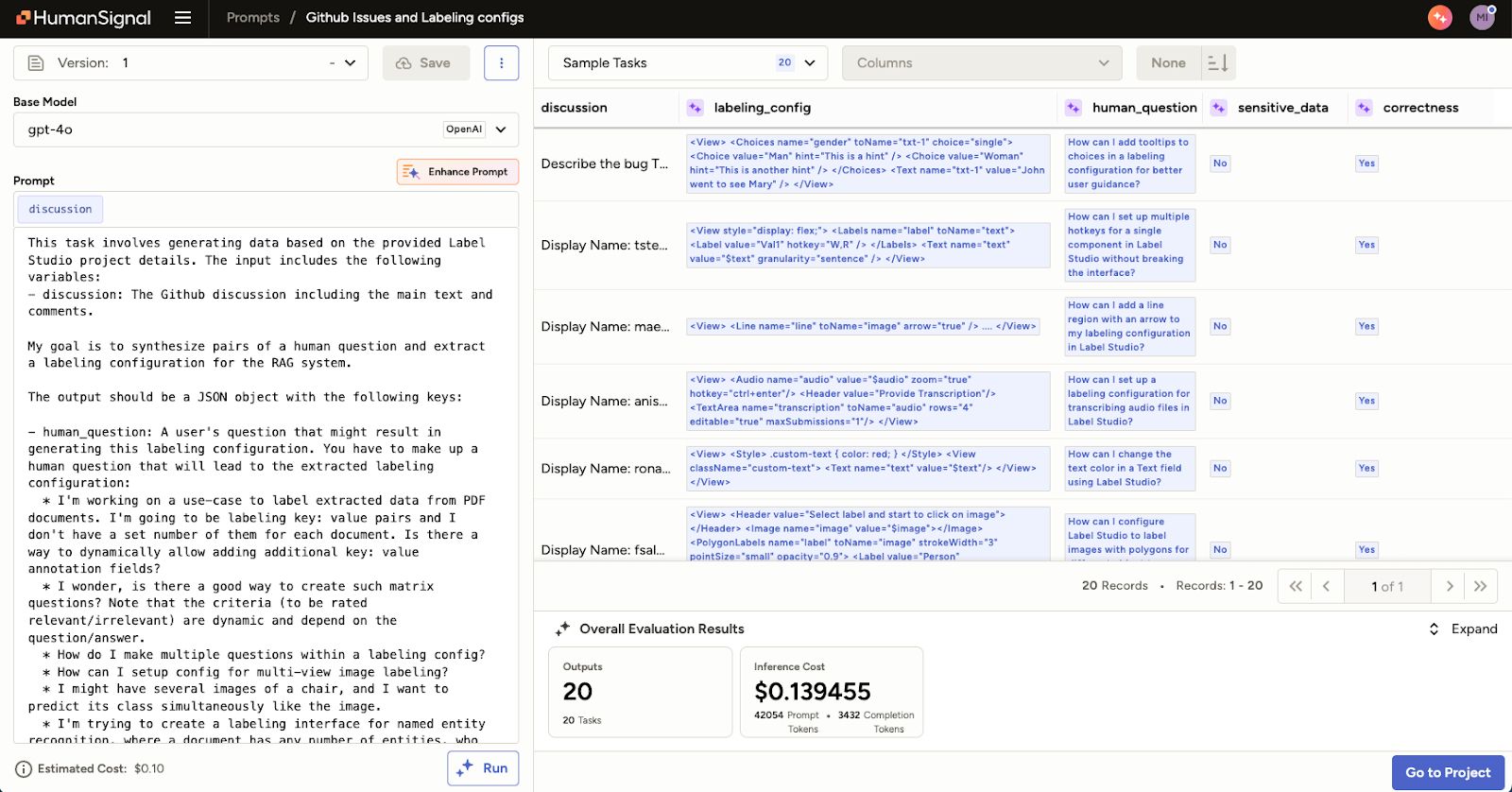
{discussion}We utilized structured output generation to create metadata such as expected labeling project titles and descriptions, along with possible user questions. These human-readable stories became the documents in our knowledge base, combining existing intermediate results with LLM-generated metadata.
The example of the generated data in Prompts:
Step 3: Review Synthetic Dataset in Label Studio
Thanks to the versatile data UI, we effectively used Label Studio to quickly review and correct synthetic data errors in the generated dataset, achieving high quality.
It is worth noting that as a result, we obtained a dataset that we split into two parts: test and train datasets consisting of 10% and 90% of the samples, respectively. This automatically provided us with the opportunity to test the accuracy of our system, which we believe is one of the most important steps in building agent-based AI systems.
Step 4: Plug it in RAG Context
Once the dataset was ready, we built a retriever for the input user questions by searching through question and answer pairs. As a vector store, we used ChromaDB with the following approaches:
- Split all documents into chunks with a size of 500.
- Use openai-3-large embeddings for the human-question field only, ignoring the labeling configuration part to avoid unnecessary noise that might be caused by XML tags.
- Retrieve the first 10 chunks and include the fully corresponding and concatenated documents into the LLM context.
Then we implement the final steps for RAG: we pass the context and the original user question to LLM. As output, we ask LLM to produce a structured output with a labeling config in XML format, a sample task, and an explanation of this configuration.
Step 5: Test the RAG System
We tested the system using the synthetic questions from our test set. We ran these synthetic questions through the RAG system and compared the LLM-generated intermediate results with the human-verified results from Label Studio (pairs of questions and labeling configurations).
We used another LLM to determine if two labeling configurations were identical. Each pair of labeling configurations was passed to the LLM with the question: are they identical in functionality? As a result, we received a yes or no answer. By comparing the original and generated labeling configurations, we calculated an accuracy score. We then averaged the results to obtain concrete performance metrics.
There are many reasons why your RAG system might not perform the way you want it to – check out our blog to learn more about the 7 Ways RAG Fails and How to Fix Them!
What’s next?
After training our RAG system, we were able to do some additional research. A RAG system is based on embeddings, which can be projected into a two-dimensional space, enabling us to visually identify clusters, detect noise or outliers, and gain deeper insights into our data. By plotting these embeddings and exploring the resulting visualization, we could better understand the types of documents within our RAG system, uncover discrepancies, and, if user data is involved, derive valuable insights about our users.
If you're looking to take your system from functional to production-grade, human oversight becomes even more important. From data quality to retrieval precision, adding expert review at key points can significantly improve performance. Explore how human-in-the-loop strategies solve RAG’s biggest challenges in this blog post.
Related Content
-
Label Studio SDK 2.0.0: Your Migration Guide
We’ve released Label Studio SDK 2.0.0, bringing expanded project settings, new Enterprise endpoints, and improved documentation. Here’s what’s new and how to upgrade.

HumanSignal Team
August 21, 2025
-

Integrating Label Studio with Model Context Protocol (MCP)
Large language models can reason and plan but they can’t act. Learn how to integrate Model Context Protocol (MCP) with Label Studio to automate and simplify your annotation workflows.

Jimmy Whitaker
June 2, 2025