Why Human Review is Essential for Better RAG Systems

Retrieval-Augmented Generation (RAG) has been the go to approach for adapting AI for your domain. Slap an LLM on top of your documents, and boom – instant knowledge expert.
Unfortunately, like much in the ML world, the hype often runs ahead of the messy reality. Getting a RAG system running is one thing. Getting it right – reliable, accurate, and actually useful – is another beast entirely. If you deploy a RAG system without a solid plan for evaluation and improvement, you're not building a smart assistant; you're potentially building a confident liar.
Why the caution? Because RAG systems can fail in numerous ways, often silently. Maybe the retriever pulls irrelevant documents. Maybe the LLM hallucinates details not present in the sources. Maybe it ignores perfectly good context. As outlined in Seven Ways Your RAG System Could Be Failing, the potential pitfalls are many. Just getting a response isn't enough; you need the right response, grounded in the right information.
Metrics Are a Starting Line, Not a Finish Line
There are many approaches to suss out the problems in our RAG system. And given the amount of effort human review takes, automated metrics are the obvious first step. Frameworks like Ragas give us scores for things like faithfulness (does the answer match the sources?) and context_relevance (did we retrieve useful stuff?). Furthermore, projects like RAGBench are pushing for standardized datasets and evaluation to improve on evaluation techniques, which is crucial for progress in RAG systems.
But here's the catch: the metrics tell you what might be wrong, but rarely why. A low faithfulness score could mean many things. Did the LLM hallucinate? Did it misinterpret subtle wording in the source? Was the source itself ambiguous? The metric alone doesn't know.
What we can do is use metrics to prioritize human evaluation to make sure we’re addressing the biggest problems first. That’s what we’ll do in our example notebook accompanying this post. We use the Ragas metrics to prioritize potentially incorrect answers that we can review in Label Studio. It gives us a starting point. To solve these issues, we can once again look at Seven Ways Your RAG System Could Be Failing to go about addressing them.
First, let’s get some data we can work with. We’ll use a RAGBench dataset that has precomputed Ragas metrics to simplify the analysis. We can set some thresholds and pull out the examples that look suspect.
def identify_critical_samples(df, thresholds):
"""
Identify examples that need human evaluation based on Ragas metrics
"""
# Identify problematic examples
critical_samples = df[
(df['ragas_faithfulness'] < thresholds['ragas_faithfulness']) |
(df['ragas_context_relevance'] < thresholds['ragas_context_relevance'])
].copy()
# Calculate overall severity score (weighted equally by hallucination and relevance)
critical_samples['severity_score'] = 1 - (
critical_samples['ragas_faithfulness'] * 0.5 +
critical_samples['ragas_context_relevance'] * 0.5
)
return critical_samples.sort_values('severity_score', ascending=True)
# Cutoff values for critical samples
thresholds = {
'ragas_faithfulness': 0.7, # Lower risk of hallucination
'ragas_context_relevance': 0.6 # Lower error in relevance
}
# Get critical samples
critical_samples = identify_critical_samples(df, thresholds)What Happens Next: Human-in-the-Loop Review
Now that we’ve isolated the responses that are most likely to be problematic, the next step is to actually dig in and understand what’s going wrong. This is where automated metrics hand off the baton to human reviewers.
Reviewers play a crucial role in identifying why something failed. Did the model hallucinate an answer that sounded plausible? Did it miss key information that was actually in the retrieved sources? Was the user’s question misunderstood? These nuances are often invisible to automated tools but obvious to a person reading the full exchange.
But just saying “add human review” isn’t enough. If it’s too manual or scattered, it becomes a bottleneck. That’s why we need to design a lightweight, focused review loop.
Making Human Review Structured and Efficient
The key to scalable human-in-the-loop evaluation is giving reviewers exactly the context they need—no more, no less. For each flagged response, we want to package up:
- The original user query
- The model’s answer
- The documents retrieved by the retriever
- The relevant Ragas metrics (so reviewers know why this was flagged)
Using tools like Label Studio, we can present this context in a structured UI and ask reviewers to provide feedback on specific dimensions:
- Accuracy: Is the response factually correct based on the documents?
- Relevance: Did the retrieved documents contain the necessary info?
- Completeness: Did the model include all the relevant points?
- Metric alignment: Do the Ragas scores reflect what the reviewer sees?
Here’s an example of what a single review task might look like.
{
"id": "sample_001",
"data": {
"user_query": "How do I enable Ambient Mode on my TV?",
"assistant_response": "To enable Ambient Mode, press the 'Ambient' button on your remote.",
"retrieved_sources": "<div>Instructions for Picture Mode...</div><div>Ambient Mode details...</div>",
"metrics": {
"ragas_faithfulness": 0.45,
"ragas_context_relevance": 0.30,
"severity_score": 0.875
}
}
} This format makes it easy to scale review across a team or crowdsource it within your org. It also turns vague model feedback into concrete, actionable data. Note: In the notebook, we perform a few modifications to the retrieved_sources to display it nicely in the UI.
Once we load our task data into Label Studio, we can see how it’s neatly structured in the UI—examples are shown in the figures below (see the example notebook for full details).
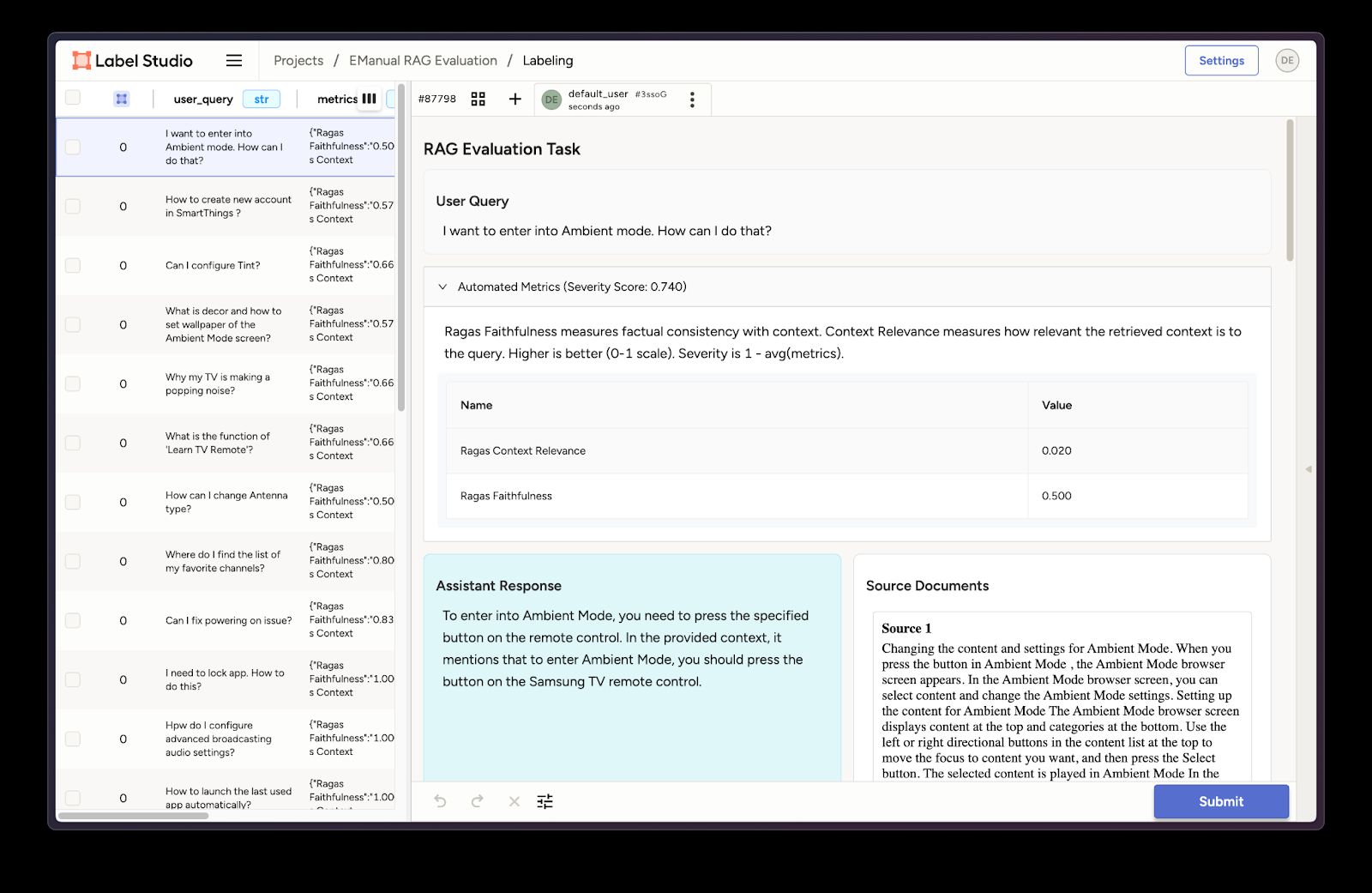
Figure 1: RAG Review template in Label Studio.
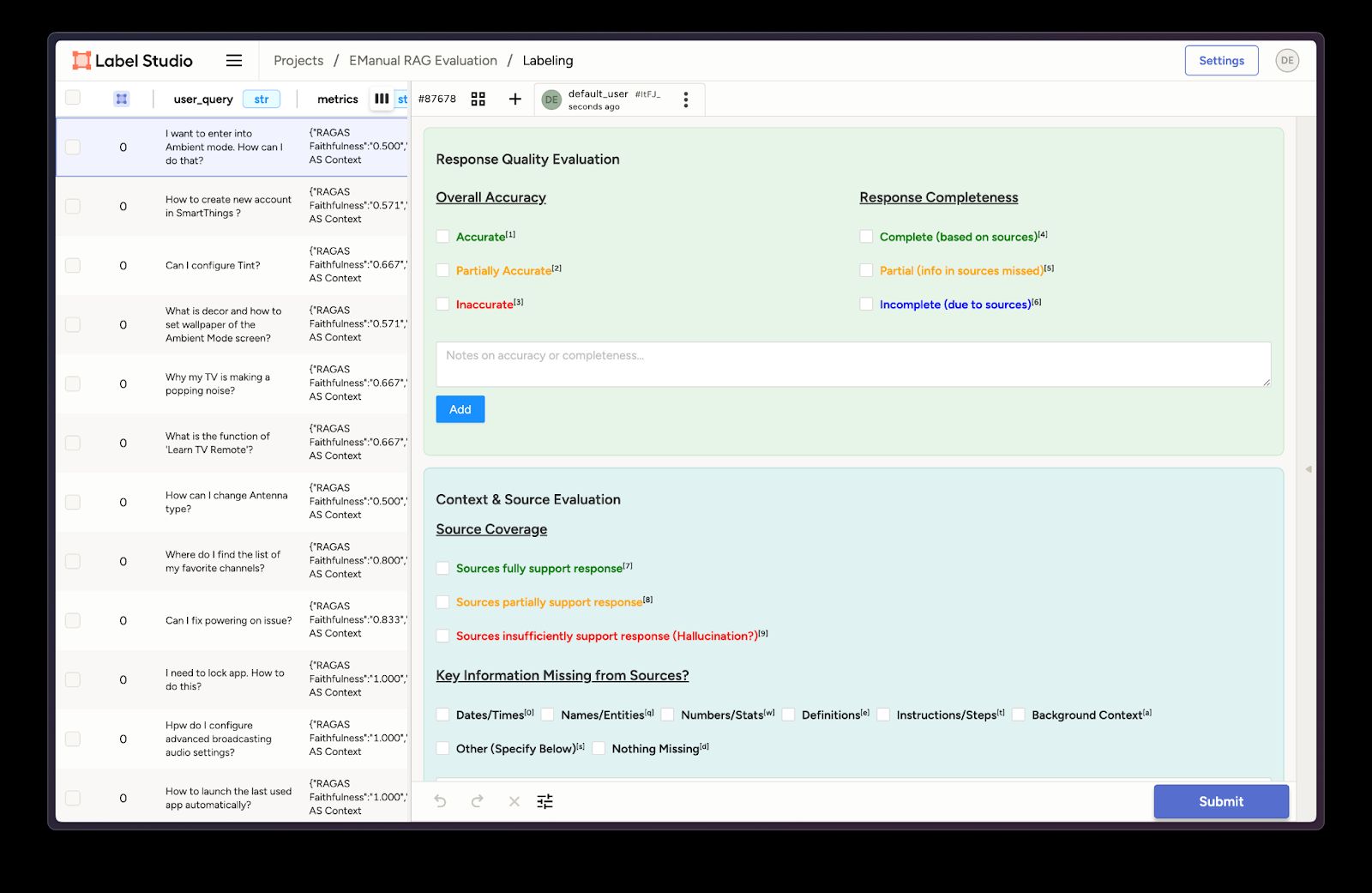
Figure 2: Review questions for our RAG Evaluation.
Closing the Loop: From Feedback to System Improvement
Once reviewers have provided structured feedback, we can do more than just catalog errors—we can act on them. This is where the real value of human-in-the-loop evaluation kicks in. Each reviewed example becomes a case study in what’s going wrong and what can be improved.
Some common patterns you might see:
- Low faithfulness with high context relevance? The retrieval was good, but the model hallucinated—time to revisit your prompt or model parameters.
- Low context relevance? The retriever is failing—maybe your embedding model isn’t domain-tuned, data needs to be added, or your indexing strategy needs adjustment.
- Correct answer, but low metric scores? Your metrics may be misaligned with what humans consider accurate, and that's a valuable signal, too.
This feedback becomes a direct input into iterative improvement:
- Refine retrieval logic (e.g., reranking, hybrid search)
- Tune generation prompts or parameters
- Curate or augment your document set
- Retrain embedding models with domain-specific data
Most importantly, you can recalibrate your evaluation process. If reviewers consistently disagree with the metrics, that’s a cue to refine thresholds, adjust metric weighting, or even develop custom evaluators that better fit your domain.
Human Review as a Continuous Process
It’s tempting to treat human review as a one-time QA step—something you do before launch and then move on. But like any ML system, a RAG pipeline is never really “done.” New documents get added. User behavior shifts. Retrieval gets stale. Evaluation thresholds drift.
That’s why the goal isn’t just to “add human review” but to embed it in your RAG development cycle. A small, consistent loop of evaluation and refinement goes much further than a one-off deep dive.
Even a light-touch review process—say, 10–20 examples a week—can surface recurring issues that lead to big quality gains. And once you have the right structure in place, you can expand or automate parts of the process as needed.
Final Thoughts
RAG systems offer a powerful way to adapt large language models to your domain—but only if they’re built with care. Automated metrics like Ragas are a great starting point for spotting issues, but they don’t tell the full story. Human review fills that gap, helping you understand why things go wrong and how to fix them.
By combining metrics to prioritize, structured tools like Label Studio to streamline review, and a steady feedback loop to drive iteration, you can move beyond flashy demos and build RAG systems that are actually trustworthy.
Production-ready RAG doesn’t come from clever prompts or fancy metrics alone. It comes from thoughtful iteration.
Related Content
-

How Human Oversight Solves RAG’s Biggest Challenges for Business Success
RAG is transforming how businesses use AI, but without human oversight, its accuracy and reliability suffer. This blog explores the biggest challenges in RAG implementation and how human expertise improves data quality, retrieval relevance, and AI-driven decision-making.

Nikolai Liubimov
March 6, 2025
-
RAG: Fundamentals, Challenges, and Advanced Techniques
Explore the fundamentals of RAG, its advantages over fine-tuning, and the challenges of implementation.

Jimmy Whitaker
February 26, 2025