Building Agents for Data Labeling

Introduction
Much of the discourse in AI today centers on Large Language Models (LLMs) like GPT-4 and their potential to revolutionize everything. These LLMs, celebrated for their human-like text generation, owe their proficiency to algorithmic sophistication and rigorous human-led data curation and labeling, underscoring the symbiotic relationship between human expertise and AI efficacy.
Why does this matter? Because our reliance on these AI models is intensifying. They're transcending basic task execution, actively participating in decision-making, providing critical information, and often serving as our initial interaction point. Integrating LLMs into the data labeling workflow isn't merely about task automation; it's primarily about enhancing human expertise with AI efficiencies.
Several weeks ago, we began a discussion on the pivotal role of agents in data labeling. Now, we're delving further, exploring how LLMs and agents can be leveraged to transform this process, aiming for greater efficiency, accuracy, and scalability in data labeling.
LLMs as Initial Label Predictors
The journey begins with utilizing LLMs for initial label predictions. The model receives raw data and generates first-pass labels, serving as a foundation rather than a conclusion. Herein lies the crucial role of subject matter experts (SMEs): they evaluate these preliminary labels, endorsing accurate ones and rectifying those that miss the mark.
What's the benefit? It significantly speeds up the labeling process. With a preliminary analysis already in hand, labelers aren't confronted with the daunting task of starting from a blank slate. This approach saves time and diminishes the cognitive burden, potentially enhancing overall label quality by reducing label fatigue.
Consider a scenario where we classify text samples as either "Subjective" or "Objective."
| index | text | label |
|-------|----------------------------|-------|
| 0 | So there is no way for | 0 |
| | me to plug it in here in | |
| | the US unless I go by a | |
| | converter. | |
| 1 | "Good case, Excellent | 1 |
| | value." | |
| 2 | Great for the jawbone. | 1 |
| 3 | Tied to charger for | |
| | conversations lasting more | |
| | than 45 minutes. | |
| | MAJOR PROBLEMS!! | 0 |
| 4 | The mic is great. | 1 |By leveraging the OpenAI API, we can quickly produce predictions for each instance in a few lines of code.
prefix = '''\
Classify the text based on whether it presents an objective fact or a subjective opinion.'''
inputs = df.text.apply(lambda text: f'{prefix}\nInput:{text}\Output:\n').tolist()
completions = []
step = 20
for i in range(0, len(inputs), step):
result = openai.Completion.create(
model="gpt-3.5-turbo-instruct",
prompt=inputs[i:i+step]
)
completions.extend(c['text'] for c in result['choices'])However, this approach isn't without pitfalls. Relying solely on the LLMs to give you a prediction in the form you're expecting can be a gamble. The quality of LLM predictions isn't consistent across tasks. This can be especially true for complex or nuanced data. If we look at the results from our simple objective/subjective classification task, we can see that there is quite a lot of variation in our outputs.
{'\nObjective fact', '\nObjective fact.', '\nOpinion', '\nSubjective Opinion', '\nSubjective opinion', '\nSubjective opinion ', '\nSubjective opinion.', '\nsubjective opinion', ' \nSubjective opinion', 'Objective Fact', 'Objective fact', 'Objective fact ', 'Objective fact.', 'Subjective Opinion', 'Subjective opinion', 'Subjective opinion. ', 'This text presents a subjective opinion.', 'objective fact'}What can we do about this? Every interaction with an LLM starts with a prompt. This prompt is essentially the instruction or question you give to the model. It's easy to overlook its importance, but the prompt plays a massive role in the kind of responses you get. A well-crafted prompt can mean the difference between an LLM generating a useful prediction and delivering a response that's way off base.
In our case, we're currently getting different variants of our desired response. We can adjust the prompt to standardize the output format. Specifically, we'll use the guidance library to specify our request format and incorporate logprobs to assess prediction uncertainty. We'll go deeper into prompt adjustments in upcoming sections.
guidance.llm = guidance.llms.OpenAI("gpt-3.5-turbo-instruct")
labeler = guidance('''\
Classify the text based on whether it presents an objective fact or a subjective opinion.
Input: {{input}}
Output: {{select 'prediction' options=['Objective', 'Subjective'] logprobs='logprobs'}}''')
result = labeler(input=df.text[0])
result['prediction'], result['logprobs']Classify the text based on whether it presents an objective fact or a subjective opinion.
Input: So there is no way for me to plug it in here in the US unless I go by a converter.
Output: Subjective
('Subjective', {'Objective': -2.694936, 'Subjective': -0.06993622000000005})We can see that by changing the prompt, we can rely on a standardized output format for providing structured labels.
Human-in-the-Loop Curation
Ultimately, our primary objective is to develop advanced AI applications adept at solving complex real-world problems. To accomplish this, we need to combine human intelligence with AI capabilities, ensuring that the systems we create are efficient, context-aware, and reliable.
While AI systems, particularly LLMs, can process data at extraordinary scales and speeds, they can lack the nuanced understanding and critical judgment inherent to humans. By involving human expertise in the data labeling process, we infuse essential context, quality, and relevance into the data, characteristics that AI cannot reliably replicate. This human-in-the-loop model elevates the datasets from mere information to nuanced understanding.
Crafting a Ground Truth Dataset
Following the LLMs' predictions, the next critical phase is the formation of 'ground truth' datasets. Ground truth datasets are composed of data examples that have been meticulously reviewed and verified by human experts. They serve as the standard against which new data is evaluated and upon which machine learning models are trained and refined. Establishing this dataset ensures that our AI systems are built upon a foundation of verified, reliable data.

Since we standardized our format in the previous section, it is simple to import our predictions into a tool like Label Studio, which provides labelers with a streamlined interface to view predictions and modify labels. Once we have reviewed and corrected these predictions, we now have a reliable ground truth dataset.
Evaluating Predictor Quality
Once a ground truth dataset is in place, we must assess the initial predictions made by the LLMs. This evaluation is crucial in determining the current accuracy of our AI models and identifying areas where they can be improved. By understanding the strengths and weaknesses of the LLM predictions, we can fine-tune our prompts to improve the predictor's quality.
Once we have labeled our data in Label Studio, we can create a classification report to analyze how well our LLM predictions performed.
from sklearn.metrics import classification_report
labeled_tasks = project.get_labeled_tasks()
test_set = []
for task in labeled_tasks:
text = task['data']['text']
prediction = task['data']['prediction']
ground_truth = task['annotations'][0]['result'][0]['value']['choices'][0]
test_set.append({'text': text, 'ground_truth': ground_truth, 'prediction': prediction})
test_set = pd.DataFrame.from_records(test_set)
print(classification_report(test_set.ground_truth, test_set.prediction))This will give us the following report.
| | precision | recall | f1-score | support |
|------------|-----------|--------|----------|---------|
|Objective | 0.86 | 0.75 | 0.80 | 8 |
|Subjective | 0.67 | 0.80 | 0.73 | 5 |
|accuracy | | | 0.77 | 13 |
|macro avg | 0.76 | 0.78 | 0.76 | 13 |
|weighted avg| 0.78 | 0.77 | 0.77 | 13 |After running this, we can see that our LLM predictor is giving us an accuracy of 77% on the small subset that we started with — a decent start, but there's room for improvement.
Manual Prompt Refinement
Diving deeper into the mechanics of LLMs in data labeling, we encounter the concept of prompt engineering — a critical component that significantly influences the quality of an LLM's predictions. We have already done some prompt engineering, tweaking it to provide a consistent output format, but let's dig deeper.
The Power of the Prompt
Every Large Language Model (LLM) interaction begins with a prompt. It is the command or question you pose to the model. The prompt's formulation significantly influences the responses you receive.
Prompt engineering involves the careful crafting and continuous refinement of these prompts. It's not just about asking the right questions; it's about asking them in a way that the model understands and can respond effectively. This can involve providing the LLM with clear, concise instructions or specific examples to guide its thinking.
Few-shot Prompting
Here's where few-shot prompting comes into play. This technique involves providing the LLM with a handful of labeled examples to improve the quality of its output. We're essentially equipping the model with additional context, specifically in areas where it has previously faltered or shown a lack of understanding.
But why does few-shot prompting work? It comes down to how LLMs like GPT-4 are trained. They are trained on vast amounts of text data, identifying patterns, structures, and associations between different pieces of information. When we use few-shot prompting, we're leveraging the model's foundational training by giving it specific examples that mirror the patterns it has already learned. These examples help to clarify our expectations and create a 'path of least resistance' toward the correct answer or output.
By showing the model what we're looking for, we help it apply its pre-existing knowledge more accurately. It's like reminding an expert of the work they've done in the past that's similar to your current problem; with that in mind, they can more easily apply their skills and knowledge to suit your needs. This is how few-shot prompting enhances LLM's performance, making it a powerful tool in prompt engineering.
error_examples = test_set[test_set.ground_truth != test_set.prediction]
prompt = '''\
Classify the text based on whether it presents an objective fact or a subjective opinion.
{{~#each examples}}
Input: {{this.text}}
Output: {{this.ground_truth}}
{{~/each}}
Input: {{input}}
Output: {{select 'prediction' options=['Objective', 'Subjective'] logprobs='logprobs'}}'''
labeler = guidance(prompt)
examples = error_examples.to_dict(orient='records')
result = labeler(input=df.text[0], examples=examples[1:4])This gives us the following output.
Classify the text based on whether it presents an objective fact or a subjective opinion.
Input: A usable keyboard actually turns a PDA into a real-world useful machine instead of just a neat gadget.
Output: Objective
Input: Nice docking station for home or work.
Output: Subjective
Input: So there is no way for me to plug it in here in the US unless I go by a converter.
Output: ObjectiveFew-shot prompting guides the model by providing explicit examples of desired outputs, helping it understand the context or the specific pattern of response we're looking for. However, one issue that arises is the potential for overfitting. The model might become too aligned with the examples in the prompt, limiting its ability to effectively generalize responses to new, unseen examples. Essentially, it may give accurate responses to scenarios very similar to the examples provided but may falter when encountering slightly different situations or nuances. This over-reliance on the examples can lead the model to generate contextually inappropriate or factually incorrect predictions, particularly when the provided examples don't encompass a broad enough range of possibilities.
This is where techniques like Chain-of-Thoughts prompting come in.
Chain-of-Thoughts
Chain-of-Thoughts prompting extends beyond few-shot prompting by asking the model to explain the reasoning behind the answer it produces. This additional step compels the model to form a sort of "logical pathway" that leads to its conclusion, which we can then assess for validity.
We can achieve a few things by requiring the model to justify its answers. First, it provides an opportunity to catch and correct potential biases or logical fallacies that the model might otherwise propagate unchallenged. Second, it allows users to understand the basis of the model's responses, fostering a greater trust in AI-generated content. Lastly, it pushes the model's capabilities further, encouraging a more nuanced understanding and response generation beyond the simple pattern matching that can result from overfitting to the initial examples.
In this way, Chain-of-Thoughts prompting complements few-shot learning. It helps mitigate some of the risks of overfitting by demanding a deeper, more explainable form of reasoning from the model, thereby improving the reliability and quality of the LLM's predictions.
labeler = guidance('''\
Classify the text based on whether it presents an objective fact or a subjective opinion.
Describe your reasoning step-by-step.
Input: {{input}}
Reasoning: {{gen 'reasoning'}}
Output: {{select 'prediction' options=['Objective', 'Subjective'] logprobs='logprobs'}}''')
result = labeler(input=df.text[0])
result['logprobs']This gives us the following output.
Classify the text based on whether it presents an objective fact or a subjective opinion.
Describe your reasoning step-by-step.
Input: So there is no way for me to plug it in here in the US unless I go by a converter.
Reasoning:
The text presents an objective fact. This is because it states a specific situation and limitation, without expressing any personal feelings or beliefs. The use of words like "no way" and "unless" indicate a factual statement rather than an opinion. Additionally, the mention of a converter suggests a practical solution to the problem, rather than a subjective preference.
Output: Objective
{'Objective': -4.123248299946159e-06, 'Subjective': -12.375005}The possibilities for prompt modification can be endless, giving us tremendous potential for improving the quality of our predictions. Let's now pivot towards automating our prompt improvement approach.
Automating Prompt Refinement
Currently, much of prompt engineering is a manual process. It involves a lot of trial and error: giving the LLM a prompt, reviewing its predictions, tweaking the prompt, and then repeating the process until the quality of our predictions improves. While effective, this iterative process can be labor-intensive and time-consuming.
Furthermore, it requires a deep understanding of how LLMs process information. You need to anticipate what aspects of a prompt might confuse the model and know how to adjust your language or add the proper context to get the desired response. So, how can we alleviate this prompt tuning process?
You can probably see where we're going if you read our previous blog on agents. Agents allow us to solve problems by LLMs to iterate towards an answer. In our case, we want to produce an optimized set of instructions for our LLM to achieve the best score on our ground truth set.
We can systemize this process with three steps: Label, Evaluate, and Adapt. You can see the complete code in our notebook.
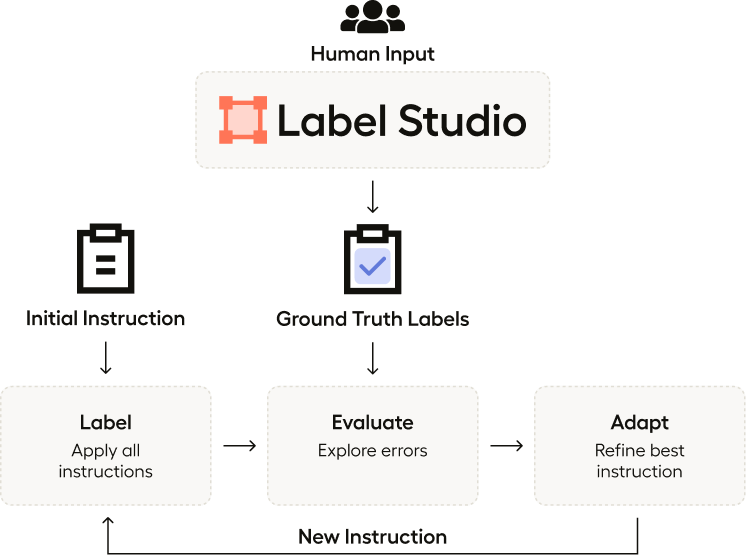
Label
The Label step is the one we've seen the most so far. This is the predictor our data. We have been tuning and tweaking our labeler instructions to provide better predictions on our model.
def label(df, instruction):
df[['prediction', 'logprob']] = df.progress_apply(label_row, axis=1, result_type='expand', instruction=instruction)
return dfEvaluate
The Evaluate step is used to compute and compare the accuracy of our most recent predictions with the ground truth as well as returning the problematic examples. We can then use the problematic examples as needed for updating the prompt for our labeling stage. We can consider this a tool for evaluating our prediction quality in the agent framework.
def eval_instructions(df, candidate_instructions):
result = []
for candidate_instruction in candidate_instructions:
print(candidate_instruction)
df_pred = label(df.copy(), candidate_instruction)
accuracy = (df_pred['prediction'] == df_pred['ground_truth']).mean()
result.append({
'instruction': candidate_instruction,
'accuracy': accuracy,
'errors': df_pred[df_pred['prediction'] != df_pred['ground_truth']]
})
return sorted(result, key=lambda x: x['accuracy'], reverse=True)Adapt
What brings everything together is the Adapt stage. This function takes the error list and accuracy scores computed in the Evaluate stage and uses an LLM to revise the instructions for the LLM.
def adapt(current_instruction, errors):
num_samples = min(3, errors.shape[0])
errors_list = errors.sample(n=num_samples).apply(lambda r: f'INPUT: {r.text}\nPREDICTED OUTPUT: {r.prediction}\nEXPECTED OUTPUT: {r.ground_truth}\n', axis=1)
errors_str = "\n".join(errors_list.tolist())
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": '''\
Act as an 'Instruction Tuner' for the LLM. You will be given the inputs:
- The [CURRENT INSTRUCTION] used to guide the LLM's classification, including specific examples with ground truth labels.
- [CURRENT ERRORS] that emerged when this instruction was applied to a dataset.
The current errors are presented in the following format:
INPUT: [input text]
PREDICTED OUTPUT: [predicted label]
EXPECTED OUTPUT: [ground truth label]
Carefully analyze these errors and craft a revised concise instruction for the LLM to fit the expected outputs. \
Include 2-3 examples at the end of your response to demonstrate how the new instruction would be applied. \
Use the following format for your examples:
Input: [input text]
Output: [expected output label]
Use specific error examples and generalize them to address any observed errors that may occur in the future.
Deliver your response as the refined instruction.'''},
{'role': 'user', 'content': f'''\
CURRENT INSTRUCTION: {current_instruction}
CURRENT ERRORS:
{errors_str}
New refined instruction:
'''}])
new_instruction = response['choices'][0]['message']['content']
return new_instructionAs we can see, we have a carefully curated prompt that is doing most of the heavy lifting. This LLM query is tasked with producing the instructions that will update the prompt for our Label stage.
The final step to create our Labeling Agent is to iterate through these steps. We can bring it all together with one last function.
def optimize_instructions(df, initial_instruction, max_iterations=3, max_instructions=3):
candidate_instructions = [initial_instruction]
for iteration in range(max_iterations):
results = eval_instructions(df, candidate_instructions)
print(f'\nResults for the iteration #{iteration}:')
display(pd.DataFrame.from_records([{'instruction': r['instruction'], 'accuracy': r['accuracy']} for r in results]))
best_instruction = results[0]
errors = best_instruction['errors']
if errors.empty or iteration == max_iterations - 1:
return best_instruction['instruction']
print('Adapting the best instruction...')
refined_instruction = adapt(best_instruction['instruction'], best_instruction['errors'])
candidate_instructions.insert(0, refined_instruction)
candidate_instructions = candidate_instructions[:max_instructions]
return refined_instructionWhen we run this function, we'll see our agent at work, optimizing our prompt and evaluating the results of our Labeler. After a few iteration through the process, we can view our optimized instructions provided to our Label step.
Please classify the following sentences as being 'Objective' or 'Subjective'. An 'Objective' statement is based on verifiable facts with no influence of personal emotions, opinions or interpretations. On the other hand, 'Subjective' sentences reflect personal judgement, feelings, or perspectives.
Additionally, objective sentences can sometimes reference individuals or groups of people, as long as the statement doesn't reflect a personal perspective, sentiment, or judgment. For example, "People couldn't hear me talk", though it references a personal experience, should be categorized as 'Objective' because it's a factual statement not influenced by emotions or personal bias.
At the same time, be aware that a sentence could start or even seem objective but ends up being subjective because it carries an opinion, evaluation, or judgement. For instance, sentences beginning with "This device is great" followed by personal favorites, preferences or the likes are inherently subjective.
Here are few examples to illustrate the above points:
1.)
Input: A usable keyboard actually turns a PDA into a real-world useful machine instead of just a neat gadget.
Output: Objective
2.)
Input: People couldn't hear me talk and I had to pull out the earphone and talk on the phone.
Output: Objective
3.)
Input: This device is great in several situations.
Output: SubjectiveIn the end, our agent moved the accuracy of the predictor up to 92% accuracy - quite the improvement from our original 77%.
Conclusion
Agent-based labeling represents a leap forward in machine learning. By implementing a dynamic, iterative process that combines the strength of human expertise and AI capabilities, we're not just streamlining the data labeling process, we're also significantly elevating the accuracy and reliability of the data that fuels our AI models.
Label Studio facilitates this balance in the ecosystem. Its user-friendly interface and flexible functionalities enable skilled professionals to contribute profoundly while efficiently automating repetitive tasks. This approach ensures we capitalize on automation effectively without overshadowing the irreplaceable insights that human expertise offers.
The future of Large Language Models (LLMs) in data labeling hinges not merely on advanced models but also on fostering improved collaboration between humans and AI, a goal that Label Studio is focused on achieving.
Make sure to check out our notebook for the full code of all the examples we've provided here.
Related Content
-

The 5 Metrics That Actually Move AI Into Production
A practical framework for turning AI metrics into clearer decisions about what to fix, ship, and scale.

Sheree Zhang
April 15, 2026
-

Scaling AI Data Quality: Best Practices for Onboarding and Evaluating Annotators
A practical workflow for onboarding and evaluating annotators with clear instructions, calibration, quality gates, reviewer feedback, and dashboards that keep labeling consistent as volume grows.

Alec Harris
March 12, 2026
-

How to Create a Prompt Generator with Label Studio and RLVR
In this article, you'll learn how to apply an RLVR-based score verifier and use an LLM as a prompt optimizer to enhance your prompts.

Label Studio Team
March 2, 2026