Combining the Power of Good Data with Pachyderm’s Versioning Tools
Data is King
In the world of machine learning, data is king. Your data's integrity and the work put into dataset development will make or break your model’s performance. The complexity of any algorithm or model architecture is significantly less impactful on the model's quality than the quality and quantity of training data.
Data labeling ensures that our models are handed with trust and care. By curating examples with human intelligence, we provide our machine-learning models with the foundation they need to learn and make accurate predictions.
This all being said, labeling data is no easy task. It's time-consuming and labor-intensive. Ensuring that each example is labeled correctly requires a lot of effort. And even if you manage to get your labeled dataset right, you will likely need to add or change it over time. Versioning your models becomes crucial.
Label Studio answers questions such as “who labeled this image?” or “how have these labels changed over time?” However, this doesn’t always give us the complete picture when retraining models over a long period of time. Different tools are needed to track the downstream effects of labeling and further understand the accuracy of your models over time. Combining the power of Label Studio’s data labeling tools with Pachyderms versioning resources — you can get a holistic picture of what’s happening across the entire cycle. Pachyderm goes beyond versioning your labels. The tool tracks every change you make to any file or pipeline you create, providing immutable versions of your source data, labels, and other elements you may need. With Pachyderm, evaluate what’s changed and how it has affected your models.
Versioning data with Pachyderm
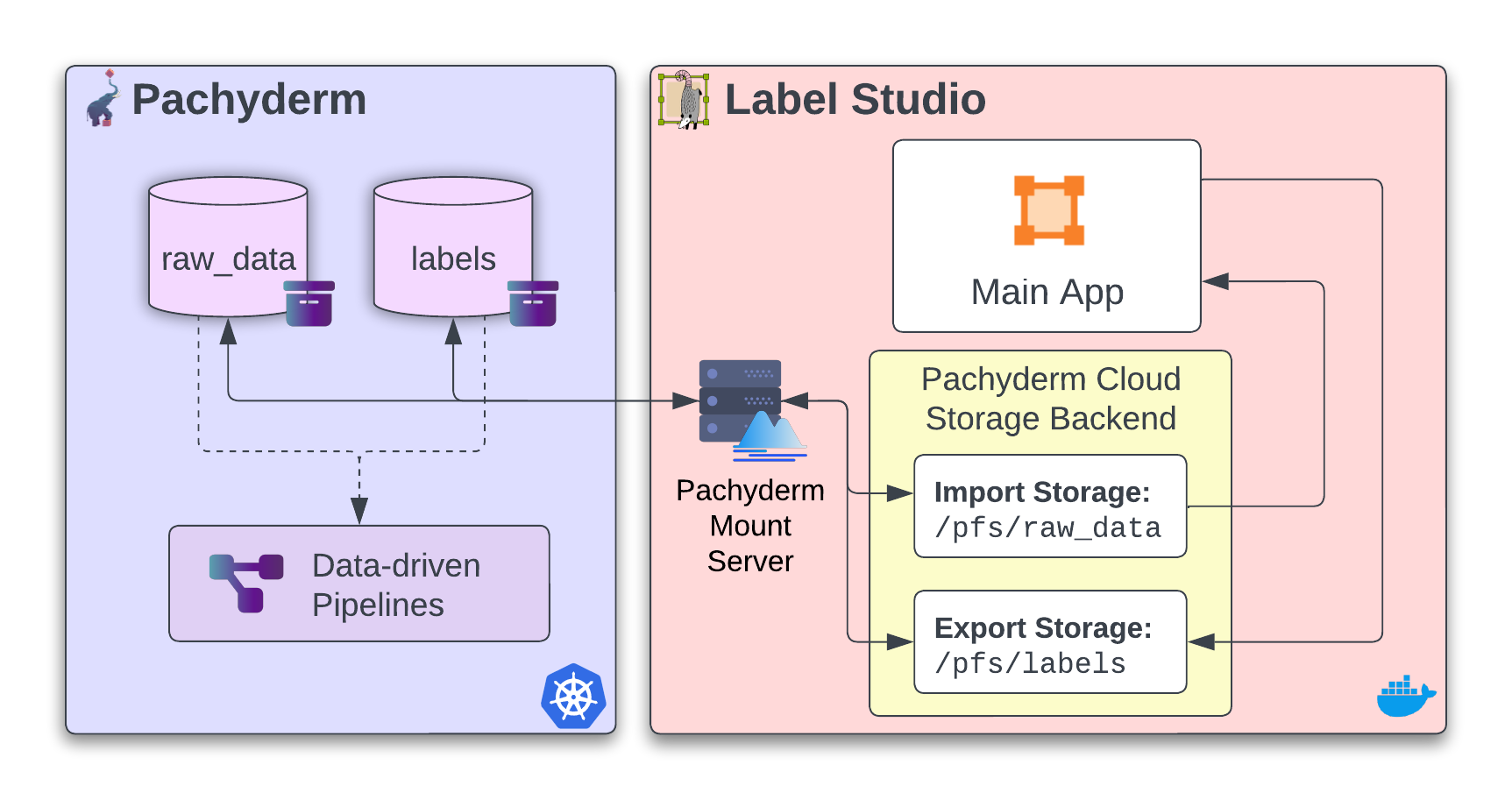
The Pachyderm integration with Label Studio makes incorporating data versioning into data team’s labeling process easier.
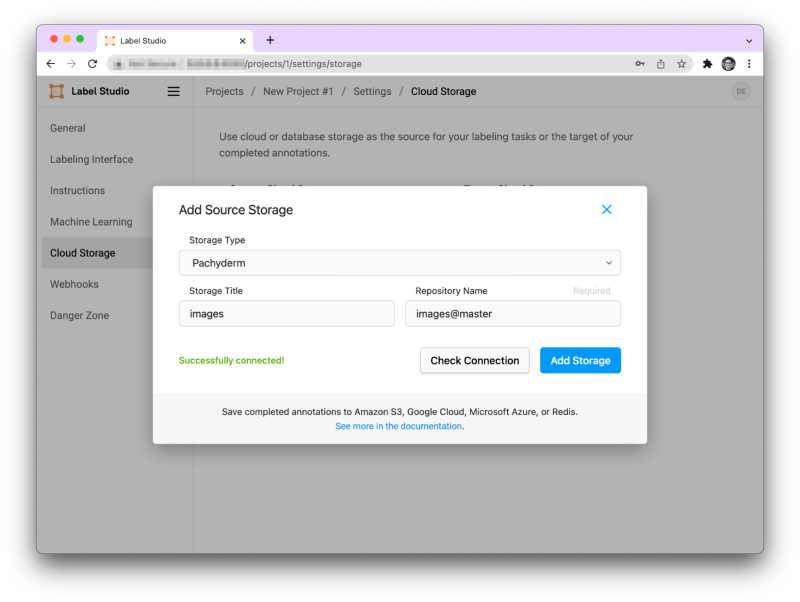
Adding Pachyderm as a storage source to Label Studio.
Similar to Git, Pachyderm stores and versions data in data repositories. In the integration, we’ve created a new storage backend inside Label Studio to reference Pachyderm data stored in repositories. Users now have the ability to pull raw data and store labels while keeping track of everything that has changed. Pachyderm also allows the labeler to choose when their labeled data gets committed to Pachyderm. The end goal is to provide a simple, responsive tool for data scientists to work with.
Exploring the integration
Let's take a deeper look at this integration and how it works. Under the hood, the integration uses a mount server designed explicitly for Pachyderm. The mount server treats a versioned data repository in Pachyderm as a file system running on your system or container. In Label Studio, it simulates a mounted drive into your environment, appearing as if the versioned data is directly in your local file system.
This is all achieved by using a FUSE mount to map data from the data repository into the local file system of the Label Studio inside a docker container. Label Studio can then read and write data directly from and to the Pachyderm data repositories. This is all a clever solution enabling anyone in the process to seamlessly work with versioned data in Label Studio without worrying about the complexities of working with Pachyderm directly.
After the data is passed to Pachyderm, the platform's data-driven pipelines take over. These pipelines are triggered automatically whenever new data is committed to a repository. Pachyderm's highly flexible pipelines allow them to be customized to run everything from tests to triggering a model retrain. This could be used to create a pipeline that automatically triggers a model training session whenever new labels are added to the repository.
Built with integrity in mind
With these pipelines in place, data science and ML teams can set up various workflows to suit whatever needs one might have. Pimples can be set up to test labels for outliers, curate a dataset, and retrain a model each time new labels are added — with the assurance in place that the data one works with is in sync. The models provided constantly learn from the latest labeled examples, creating the most accurate and seamless process.
By automating the data management process, Pachyderm allows data science and machine learning teams to focus on what matters most: the quality of your labeled datasets. All of this combined creates better ML processes and models. The Label Studio and Pachyderm integration allows teams to streamline their machine-learning workflows, creating more time to spend iterating on the data. At the end of the day, we all know what matters most — and that’s the integrity of the data we all work with.
Continue reading Part 2 of this series, How to Integrate Pachyderm with Label Studio.
Related Content
-
How to Integrate Pachyderm with Label Studio
Read step-by-step instructions to integrate Label Studio and Pachyderm, including code examples.

Jimmy Whitaker
March 6, 2023