How to Integrate Pachyderm with Label Studio
Why integrate these tools?
Label Studio and Pachyderm create a powerful combination providing folks across both the dataset development phase and retraining and active learning phases with tools they need to build better, more enhanced models. Both tools are data-driven and strongly emphasize the integrity and accuracy of the datasets they work with.
Widely adopted across a variety of industries and use cases, both Label Studio and Pachyderm provide flexible, community-driven open source offerings as well as enterprise cloud services and on-prem offerings as well. Depending on the stage and level of your organization or data annotation teams — Pachyderm and Label Studio offer solutions for almost any scale and level for you.
Read Part 1 of this series to learn how versioning tools like Pachyderm and Label Studio enable dataset development and ML accuracy here.
Get started with the Pachyderm and Label Studio integration
Before starting with the Pachyderm and Label Studio integration, ensure you have instances running each. Get started with Label Studio by signing up for a free trial here or using our get-started tutorial here. It will also help to map out your existing machine learning workflow so that everyone is on the same page across your data science and ML team.
Step-by-step instructions
- Set up a Pachyderm Cluster. Follow the instructions in the Pachyderm documentation to set up a Pachyderm cluster. This will involve creating a Kubernetes cluster and installing the Pachyderm software.
- Create data repositories. Once the Pachyderm cluster is set up, create data repositories to store your data. Use the Pachyderm CLI or one of the language clients to create a new repository. The ability to create pipelines is also available to process data when labeled.
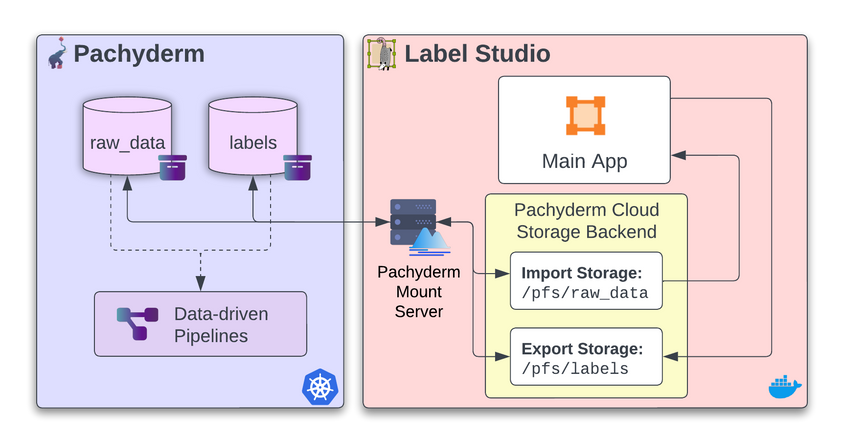
- Run the Label Studio Docker container. Next, run the Label Studio Docker container with the packaged Pachyderm mount server. Provide the container with your Pachyderm configuration so that it can access the cluster. See the integration on GitHub for more details.
- Ingest raw data. Once the Label Studio Docker container is up and running, use the Pachyderm integration to set the Source and Target storage areas. Once you press “Sync Storage,” the repositories will be mounted and the data will appear in Label Studio.
- Label your data. After importing your data, start annotating using the Label Studio web interface as usual.
- Sync target storage. After creating your labels, sync the target storage to push all the labels to the target Pachyderm data repository.
For more details, check out the integration on GitHub or see Pachyderm’s step-by-step walkthrough on Medium and YouTube. We also have an object detection example incorporating Label Studio and applying this integration into a complete machine-learning workflow.
To sum things up
Labeling data is crucial for improving machine learning models, and versioning is essential to the labeling process. By using Label Studio to integrate with a platform like Pachyderm, you can track and manage changes to your data, ensuring that you have the highest quality labeled data to train your models on and enable reproducibility across your ML life cycle.
Related Content
-
Combining the Power of Good Data with Pachyderm’s Versioning Tools
The Pachyderm integration with Label Studio makes incorporating data versioning into any data team’s labeling process easier.

Jimmy Whitaker
Data Scientist in Residence at HumanSignal