OpenAI Structured Outputs with Label Studio

Using large language models (LLMs) for labeling tasks can significantly improve efficiency. However, these models typically generate freeform text, which typically requires additional preprocessing to format outputs into a usable structure. OpenAI’s new Structured Outputs feature allows you to ensure outputs conform to a defined JSON structure, making it ideal for integrations with tools like Label Studio. In this blog, we’ll explore how to leverage this feature for various labeling tasks.
Why Use Structured Outputs with Label Studio?
Label Studio supports a pre-annotations format for incorporating predictions into the labeling workflow, but integrating outputs from LLMs can be challenging. Freeform outputs usually require extensive pre- and post-processing to match specific data formats, which can increase development time and the likelihood of errors. Additionally, model outputs can vary inconsistently, often including explanations or differing result formats. Structured Outputs solve these issues by enabling developers to define the desired JSON structure in advance, ensuring consistent and predictable results.
Defining data schemas directly with JSON schema can be cumbersome and error-prone, especially compared to Python-native libraries like Pydantic. JSON schema requires meticulous manual definition of each field, lacks direct integration with Python’s type system, and complicates validation. In contrast, Pydantic simplifies this process by allowing schema definitions using Python classes with type hints, which enhances code readability and error handling.
For example, consider defining a simple user schema with a name and age:
Using JSON Schema:
{
"type": "object",
"properties": {
"name": {"type": "string"},
"age": {"type": "integer", "minimum": 0}
},
"required": ["name", "age"]
}Using Pydantic:
from pydantic import BaseModel, conint
class User(BaseModel):
name: str
age: conint(ge=0)With Pydantic, the schema is more concise, integrates seamlessly with Python code, and offers additional benefits like type checking and validation during development, making it a preferred choice for managing data schemas in Python applications.
Examples
An accompanying notebook is provided with this blog, allowing you to interact with the code and examples as you follow along with the content.
Let’s explore how to generate predictions with OpenAI Structured Outputs for different tasks. We’ll initialize our OpenAI client before continuing.
from openai import OpenAI
client = OpenAI()Summarization
Summarization involves creating a concise version of a longer text while retaining its key information. This is useful for content curation, document indexing, or summarizing research articles. By defining a schema that specifies the required fields (like summary text and confidence scores), you ensure that the model output aligns directly with what Label Studio expects, minimizing the need for post-processing and enabling seamless integration.
First, we’ll define our Label Studio schema using Pydantic.
from enum import Enum
from typing import List, Union, Optional, Literal
from pydantic import BaseModel, Field
class Label(BaseModel):
score: float
text: str
class ResultItem(BaseModel):
id: str
from_name: Literal["answer"] = "answer"
to_name: Literal["text"] = "text"
type: Literal["textarea"] = "textarea"
value: Label
class Prediction(BaseModel):
model_version: str
result: List[ResultItem]
class Data(BaseModel):
text: str
class Summarization(BaseModel):
data: Data
predictions: List[Prediction] After defining the schema, we request predictions by passing the schema as the response_format.
completion = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{
"role": "system",
"content": """You are a Summarization assistant.
Your job is to identify a best, single sentence summary
for a given piece of text. Ensure that there is only a single
summary for the given text.""",
},
{
"role": "user",
"content": "The 2024 Summer Olympics,[a] officially the Games of the XXXIII Olympiad[b] and branded as Paris 2024, were an international multi-sport event that occurred from 26 July to 11 August 2024 in France, with the opening ceremony having taken place on 26 July. Paris was the host city, with events (mainly football) held in 16 additional cities spread across metropolitan France, including the sailing centre in the second-largest city of France, Marseille on the Mediterranean Sea, as well as one subsite for surfing in Tahiti, French Polynesia."
}
],
response_format=Summarization
)The output populates our schema as intended:
{
"data": {
"text": "The 2024 Summer Olympics, branded as Paris 2024, were an international multi-sport event held from 26 July to 11 August 2024 in Paris and 16 additional cities across France, with surfing events in Tahiti."
},
"predictions": [
{
"model_version": "1",
"result": [
{
"id": "result",
"from_name": "answer",
"to_name": "text",
"type": "textarea",
"value": {
"score": 1.0,
"text": "The 2024 Summer Olympics were held in Paris and other locations across France and French Polynesia from 26 July to 11 August 2024."
}
}
]
}
]
}This JSON result can be directly imported into a Label Studio text summarization project.
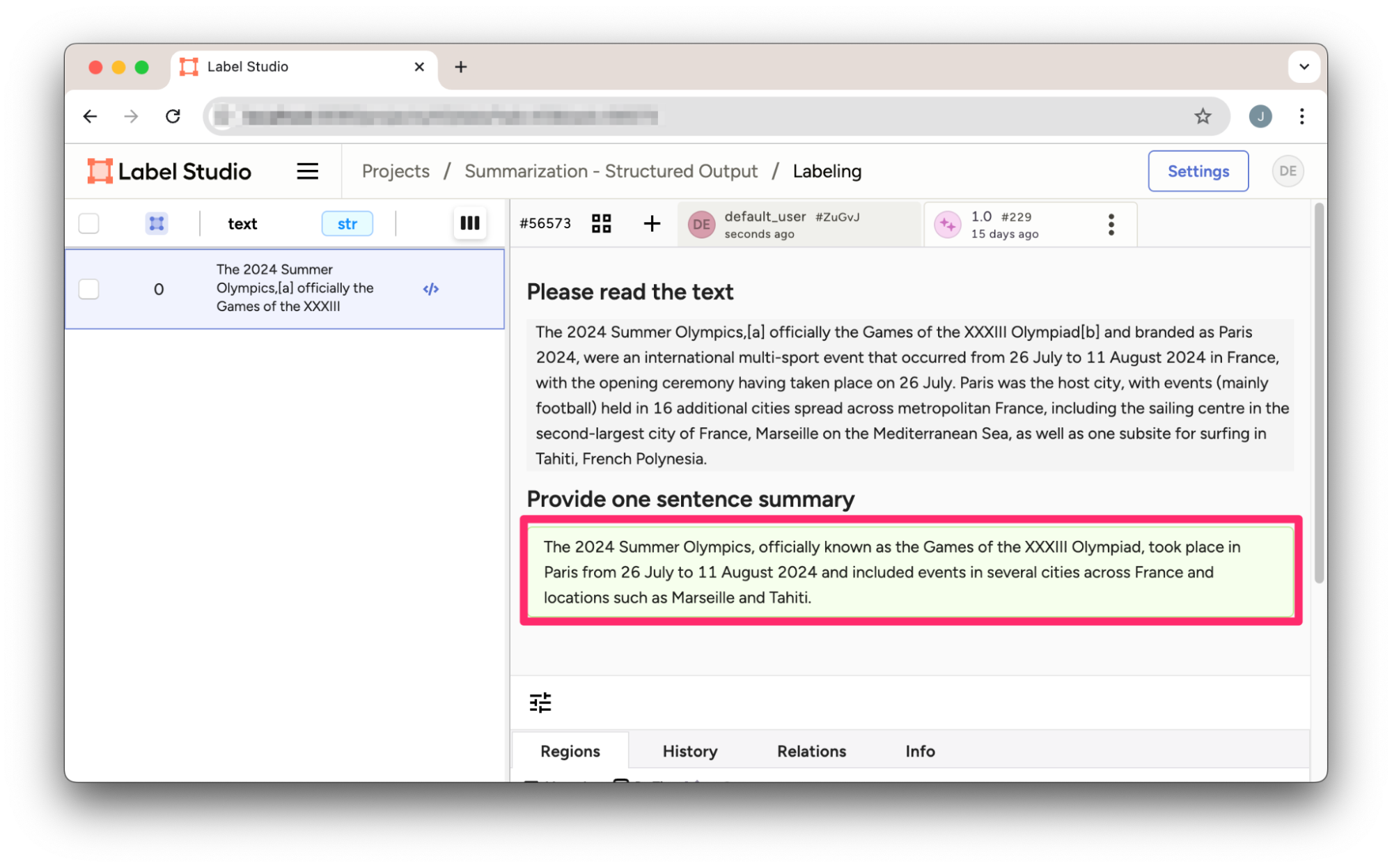
Figure 1: Summarization prediction in Label Studio imported from OpenAI’s Structured Outputs result.
Text Classification
Text classification involves assigning a string of text to a predefined category, such as sentiment analysis (e.g., positive, negative, neutral), topic categorization, or spam detection. Classification is typically a bit trickier when it comes to using LLMs to predict labels, as the exact categories can get confused in the generation process.
Using Structured Outputs for text classification lets us define the exact schema to dictate the classification results. Not only can we control the exact names of the class labels that will be returned, but confidence score and additional metadata can be incorporated if the predictions are unclear. By using this approach, the output is directly importable into Label Studio to incorporate human review to work towards curating a high-quality dataset. Let’s look at how we would implement this for the sentiment analysis project template.
Again, we’ll define our Label Studio schema in Pydantic.
class EntityType(str, Enum):
positive = "Positive"
negative = "Negative"
neutral = "Neutral"
class Label(BaseModel):
score: float
choices: List[EntityType]
class ResultItem(BaseModel):
id: str
from_name: Literal["sentiment"] = "sentiment"
to_name: Literal["text"] = "text"
type: Literal["choices"] = "choices"
value: Label
class Prediction(BaseModel):
model_version: str
result: List[ResultItem]
class Data(BaseModel):
text: str
class Classification(BaseModel):
data: Data
predictions: List[Prediction] Once we’ve defined our schema, we’re ready to request predictions, passing the schema as the response_format.
completion = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{
"role": "system",
"content": """You are a Sentiment analysis assistant.
Your job is to provide the sentiment for
for a given piece of text. Ensure that there is only a single
sentiment for the given text.""",
},
{
"role": "user",
"content": "We're excited to announce the 1.13 release of Label Studio! This update includes a refreshed UI and some new Generative AI templates for you to use."
}
],
response_format=Classification
)When we review the output, we can see that the completion has populated our schema exactly as we wanted.
{
"data": {
"text": "We\u2019re excited to announce the 1.13 release of Label Studio! This update includes a refreshed UI and some new Generative AI templates for you to use."
},
"predictions": [
{
"model_version": "1.3",
"result": [
{
"id": "1",
"from_name": "sentiment",
"to_name": "text",
"type": "choices",
"value": {
"score": 0.98,
"choices": [
"Positive"
]
}
}
]
}
]
}Saving the JSON result, we can directly import it into Label Studio.
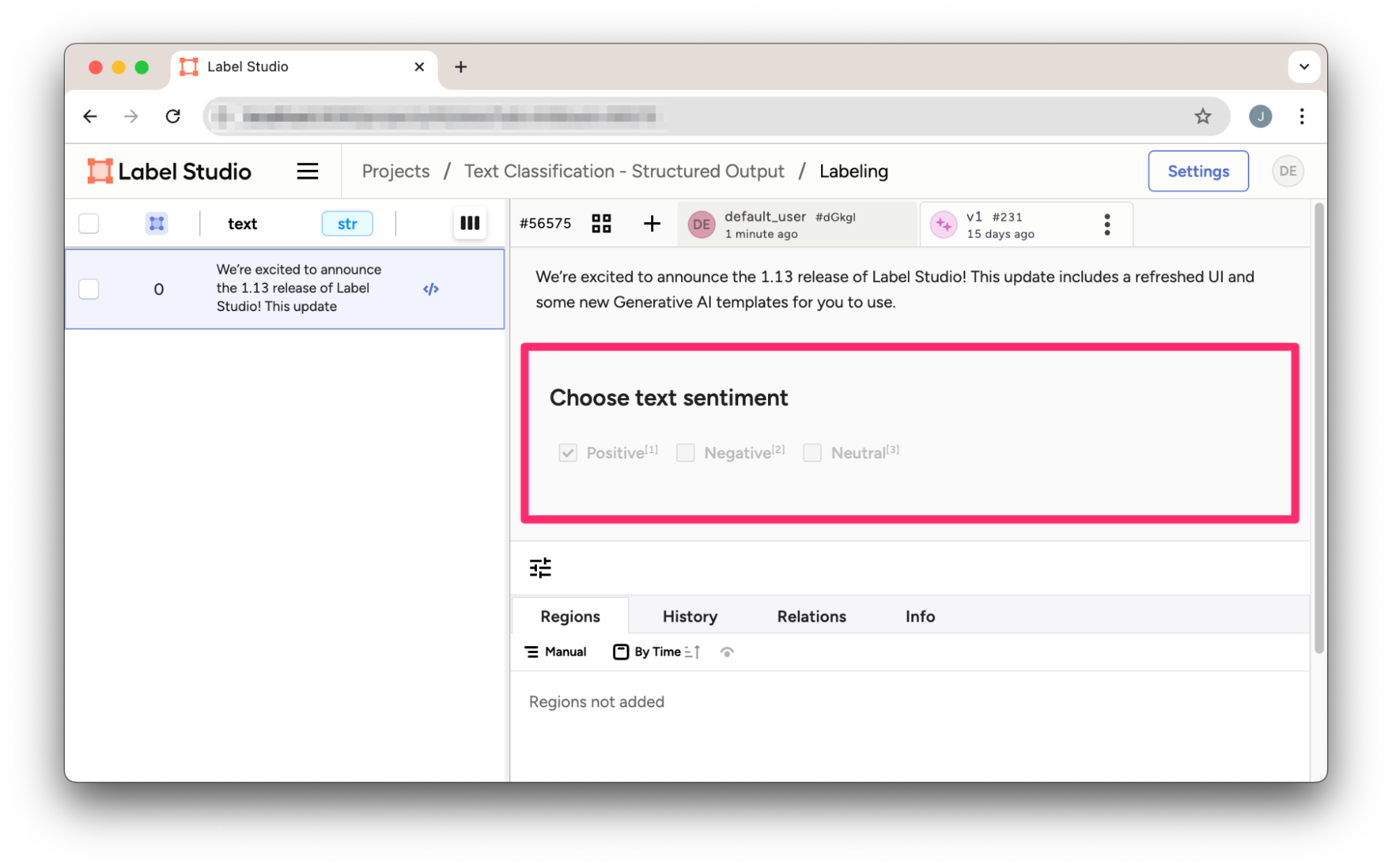
Figure 2: Text classification prediction in Label Studio imported from OpenAI’s Structured Outputs result.
Named Entity Recognition
Named Entity Recognition (NER) involves identifying entities like people, organizations, locations, and dates within text. This task is more complex as it requires identifying entity names and their positions within the text. While LLMs can identify entities, obtaining exact character offsets (start and end positions) can be challenging. By defining a schema that includes these details, you can format the output for Label Studio, which will include generated predictions for these entries, but the correctness may not be reliable. As we’ll see in our case here, some post-processing adjustments are likely to still be needed.
We define our Label Studio schema for the NER template using Pydantic:
class EntityType(str, Enum):
person = "Person"
organization = "Organization"
location = "Location"
datetime = "DateTime"
product = "Product"
percent = "Percent"
fact = "Fact"
money = "Money"
class Label(BaseModel):
start: int
end: int
score: float
text: str
labels: List[EntityType]
class ResultItem(BaseModel):
id: str
from_name: Literal["label"] = "label"
to_name: Literal["text"] = "text"
type: Literal["labels"] = "labels"
value: Label
class Prediction(BaseModel):
model_version: str
result: List[ResultItem]
class Data(BaseModel):
text: str
class NamedEntities(BaseModel):
data: Data
predictions: List[Prediction]Once we’ve defined our schema, we’re ready to request predictions, passing the schema as the `response_format`.
completion = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{
"role": "system",
"content": """You are a Named Entity Recognition (NER) assistant.
Your job is to identify and return all entity names and their
types for a given piece of text. You are to strictly conform
only to the following entity types: Person, Location, Organization
and DateTime. If uncertain about entity type, please ignore it.
Be careful of certain acronyms, such as role titles "CEO", "CTO",
"VP", etc - these are to be ignore.""",
},
{
"role": "user",
"content": "Samuel Harris Altman (born April 22, 1985) is an American entrepreneur and investor best known as the CEO of OpenAI since 2019 (he was briefly fired and reinstated in November 2023)."
}
],
response_format=NamedEntities
)When we review the output, we can see that the completion has populated our schema exactly as we wanted. Although, we should be skeptical of the start and end character offsets. We’ll import the data into Label Studio to see what we get.
{
"data": {
"text": "Samuel Harris Altman (born April 22, 1985) is an American entrepreneur and investor best known as the CEO of OpenAI since 2019 (he was briefly fired and reinstated in November 2023)."
},
"predictions": [
{
"model_version": "2023.10.01",
"result": [
{
"id": "1",
"from_name": "label",
"to_name": "text",
"type": "labels",
"value": {
"start": 0,
"end": 19,
"score": 0.95,
"text": "Samuel Harris Altman",
"labels": [
"Person"
]
}
},
{
"id": "2",
...
]
}
]
}The model accurately identifies entities, but it struggles with providing the correct character offsets needed for Label Studio to pinpoint their positions in the text.
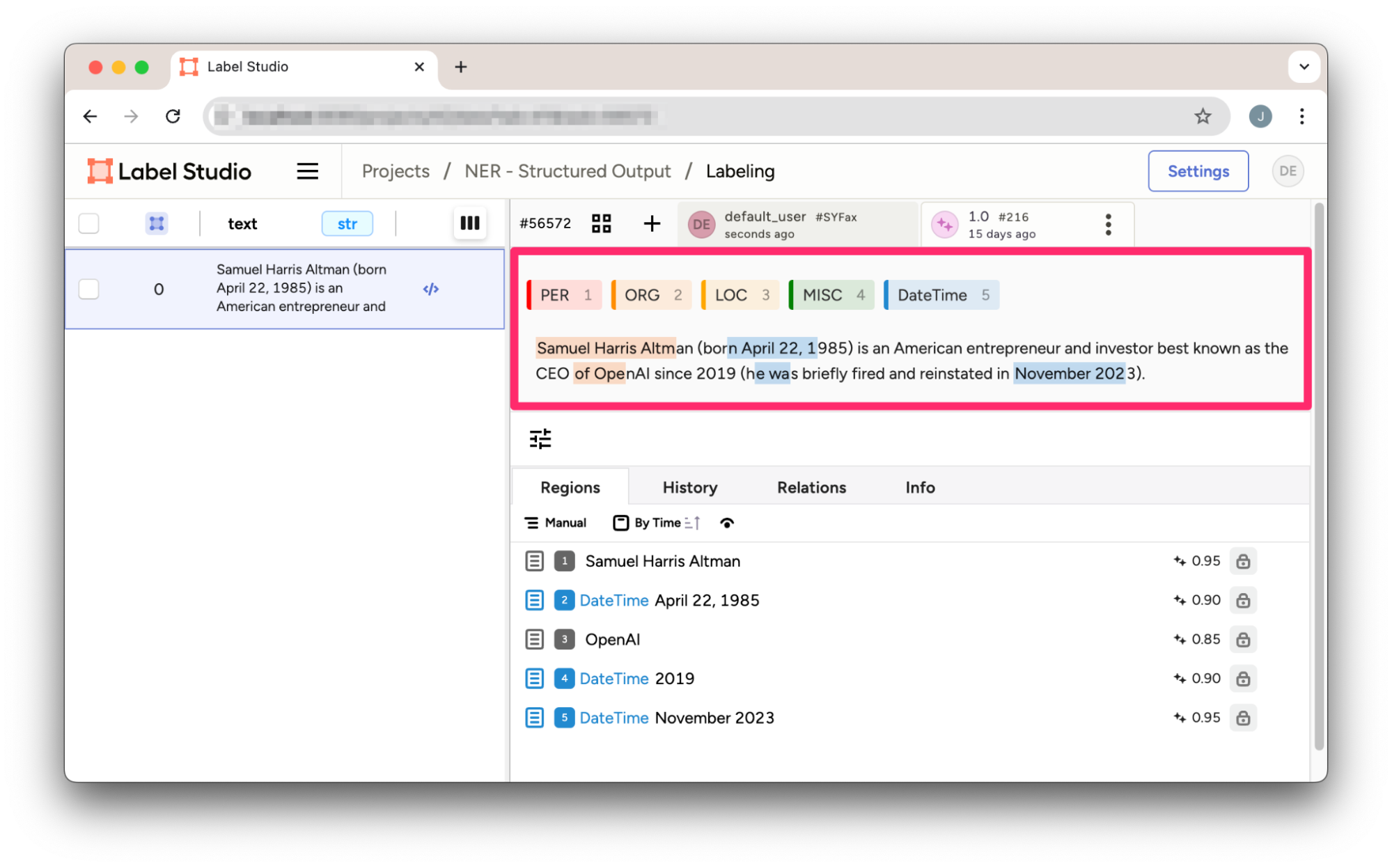
Figure 3: NER prediction in Label Studio imported from OpenAI’s Structured Outputs result. Notice the character offsets do not correctly align to the entities identified.
While identifying entities is the more complex task, the model’s character offsets—which indicate the entities’ locations in the text—are inaccurate. Since determining the exact position of characters in a string is straightforward programmatically, a regex or similar post-processing technique can be used to adjust and align the entities correctly. Here’s a simple python snippet to fix this issue.
import re
json_data = json.loads(completion.choices[0].message.content)
# Extract the text to search in
text = json_data["data"]["text"]
# Iterate over each result in predictions to update start and end indexes
for prediction in json_data["predictions"]:
for result in prediction["result"]:
# Get the text to find in the main text
search_text = result["value"]["text"]
# Use regex to find the exact position of the search_text in text
match = re.search(re.escape(search_text), text)
if match:
# Update start and end indexes with exact positions
result["value"]["start"] = match.start()
result["value"]["end"] = match.end()
# Print the updated JSON
print(json.dumps(json_data, indent=4))Once these adjustments are made, the output can be imported into Label Studio for further review or validation.
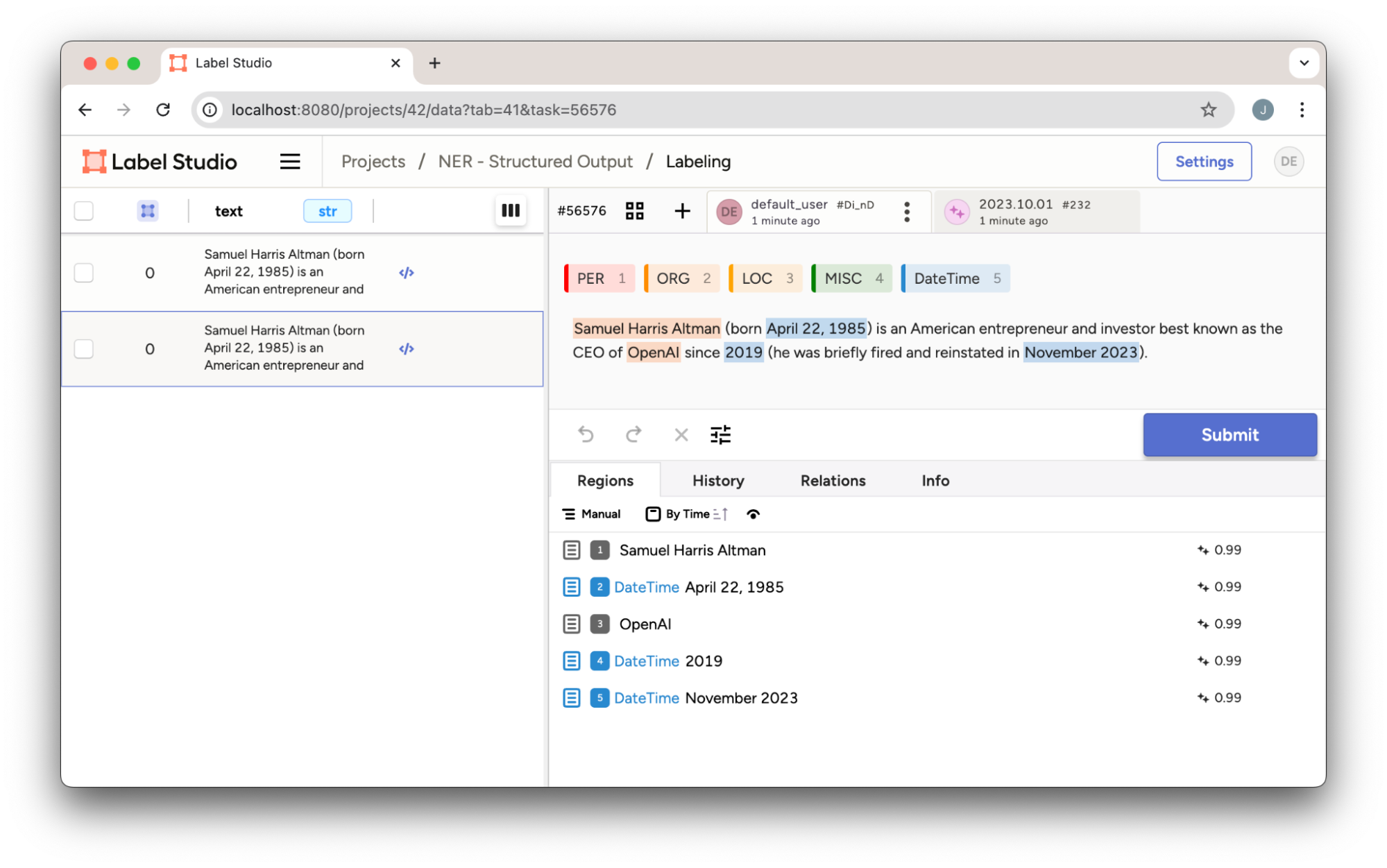
Figure 4: Aligned NER prediction in Label Studio after post-processing OpenAI’s Structured Outputs result. Notice the character offsets correctly align to the entities unlike Figure 3.
As we can see the predictions are now aligned to the text.
Tips for Using Structured Outputs Effectively
- Choosing the Right Model and Parameters: Select the appropriate model (e.g., gpt-4o-2024-08-06) and adjust parameters like temperature, max tokens, and stop sequences to optimize output quality.
- Crafting Effective Prompts: Remember that the task prompt significantly influences structured outputs. Ensure your prompt is clear and aligns with the expected format of your Label Studio project to achieve consistent results.
- Post-Processing Techniques: For tasks requiring precise details, like Named Entity Recognition (NER), use post-processing methods such as regex or string matching to correct offsets or refine outputs. It’s also essential to validate critical elements like URLs and verify the accuracy of responses when necessary.
- Schema Validation: Validate your schema before using it to identify and resolve any errors early. This step helps ensure your structured outputs align with the defined schema, reducing integration issues with Label Studio.
Conclusion
OpenAI’s Structured Outputs feature makes generating predictions for data labeling much more powerful. By ensuring outputs conform to predefined schemas, boosting reliability, and minimizing preprocessing, you can enhance the overall efficiency of your Label Studio workflow. We outlined a few examples, showing how you can use Structured Outputs, but the flexibility of these examples should allow you to extend and adapt the structured outputs to a wide range of use cases, making it a powerful solution for various data labeling challenges across different projects.
Related Content
-
Building A Labeling Config in Label Studio Enterprise
How do you build the right labeling interface in Label Studio? This video walks through a practical progression: start with templates, customize with XML tags, extend with React Code, and standardize workflows with plugins.
-

Learn how to connect YOLO26 to a Label Studio project using the YOLO ML Backend so annotators can start from model predictions and focus on review and correction instead of drawing boxes from scratch.

Micaela Kaplan
February 12, 2026
-

Getting started with Label Studio
Everything you need to know about Label Studio to get started, from downloading and installing the tool to creating your first project, adding new members, and more!