How to Generate Synthetic Data with Prompts in Label Studio

Synthetic data generation is becoming a core part of building scalable AI systems, especially when labeled data is scarce or costly. In this blog, based on our recent webinar, ML Evangelist Micaela Kaplan walks through how to use Label Studio's Prompts feature to generate synthetic Q&A pairs from existing data. Whether you’re building RAG systems or augmenting data for evaluation, this guide will help you get started.
Why Synthetic Data Matters for RAG and LLM Evaluation
Synthetic data enables you to fill in gaps where your existing datasets fall short, especially useful in scenarios like:
- Building retrieval-augmented generation (RAG) systems
- Simulating Q&A pairs from product specs or technical docs
- Expanding model training data for specific domains
You have: Data from your company– technical answers, product specs, user information
You need: Question/Answer pairs for a RAG system
We can generate what you need from what you have!
Project Setup: What You’ll Need
To follow along, you’ll need:
- Access to Label Studio
- A labeling configuration for Q&A
- An OpenAI-compatible API key (included in the trial)
- Project data: A CSV derived from the CMU Book Summary dataset on Kaggle, truncated to 50 rows. For this walkthrough, we’re using only three fields: BookTitle, Author, and Summary
Once you upload the dataset, your tasks will contain text fields that describe each book.
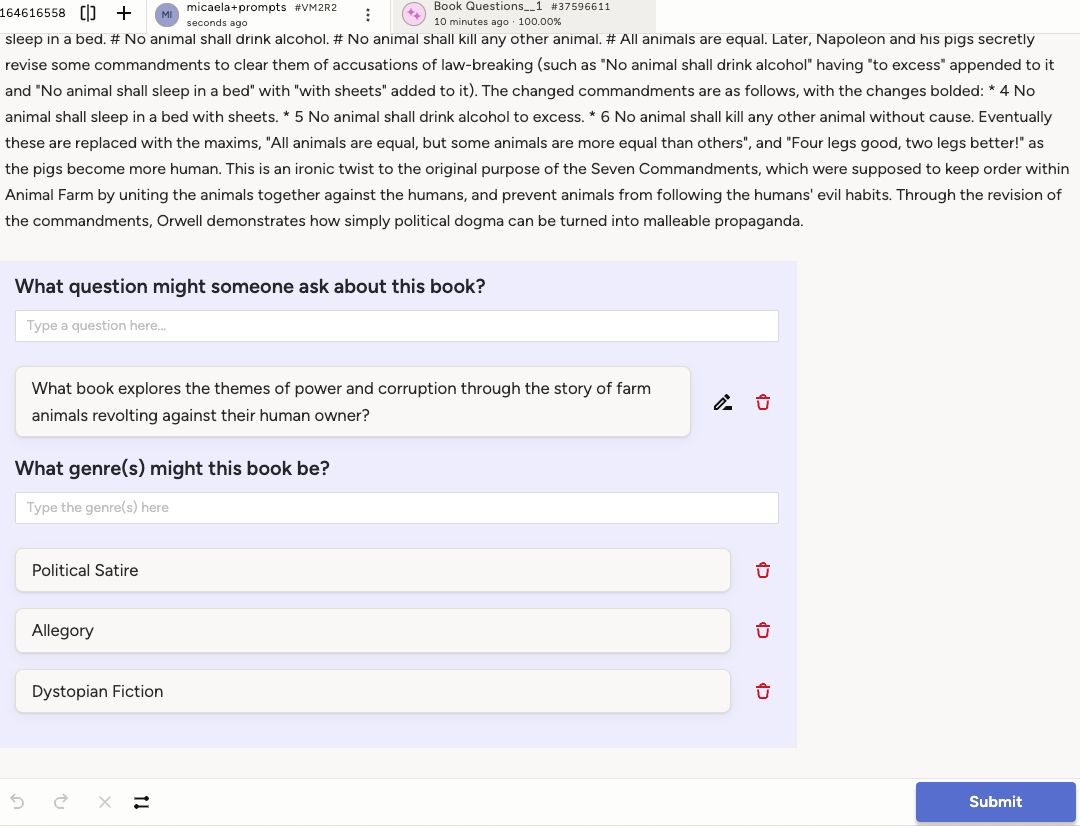
Project Setup in Label Studio
Here’s the label config used in this project:
<View>
<Style>
.question {font-size: 120%;
width: 800px;
margin-bottom: 0.5em;
border: 1px solid #eee;
padding: 0 1em 1em 1em;
background: #EDEDFD;}
</Style>
<Header value="Title"/>
<Text name="book_title" value="$BookTitle"/>
<Header value="Author"/>
<Text name="author" value="$Author"/>
<Header value="Summary"/>
<Text name="summary" value="$Summary"/>
<View className="question">
<Header value="What question might someone ask about this book?"/>
<TextArea name="question" toName="book_title,author,summary" editable="true" placeholder="Type a question here..."/>
<Header value="What genre(s) might this book be?"/>
<TextArea name="genre" toName="book_title,author,summary" placeholder="Type the genre(s) here" />
</View>
</View>
This setup allows both human and model-generated input, so you can review and edit outputs easily.
Prompt body example
Label Studio Prompts lets you configure a structured input-output task for an LLM. In this example, we used the following prompt body:
You are given the following data:
BookTitle: the title of a book
Author: the author of the book
Summary: the summary of the book.
Your task is to generate a question that a user could ask to result in the specified book.
We expect the following output fields:
– question: A question that could be asked to get the given book as a result
– genre: a list of up to 3 genre classifications.
Exporting and Using the Data
Once you're happy with the outputs:
- You can turn predictions into annotations with one click
- Export in JSON format, preserving both original and generated data
- Use the data as training input for downstream tasks or as documents in your RAG pipeline
Synthetic Data You Can Generate with Label Studio
While the webinar focused on generating Q&A pairs for book summaries, Label Studio Prompts supports a wide range of synthetic data generation tasks, especially useful when your training data is limited or incomplete.
Some examples include:
- Image Captioning: Generate natural language descriptions from images using models like Gemini or GPT-4. Great for accessibility, search indexing, or dataset bootstrapping.
- Document Summarization: Condense long texts (e.g., product manuals, support tickets, legal docs) into short summaries for faster retrieval or classification.
- Multi-label Classification: Assign categories to complex inputs like product descriptions, reviews, or support logs, especially helpful in customer service automation.
- Named Entity Recognition (NER): Use prompts to extract or simulate labeled spans (like names, dates, or locations) from raw text, speeding up annotation workflows.
- Image-based Metadata Generation: While Label Studio doesn’t generate images, you can generate metadata for image datasets, captions, tags, or contextual Q&A, based on the visual input.
These prompt flows can be used on real data, synthetic inputs, or even combinations of both, ideal for pretraining, evaluation, or stress-testing models in edge cases.
Want to build your own use case? You can mix and match image, text, and audio inputs with your own custom prompt templates inside Label Studio.
How to Evaluate the Quality of Synthetic Data
Generating synthetic data is only half the challenge, the other half is knowing whether it's any good. Inaccurate or irrelevant outputs can silently degrade your model performance, so having a structured evaluation plan is essential.
Here are several strategies you can use, depending on your use case:
1. Compare Against Ground Truth (When Available)
If you already have a labeled dataset, you can benchmark the synthetic outputs against it. In Label Studio, this can be done automatically by enabling agreement metrics like:
- Exact match
- Edit distance
- Task-level agreement scores
Use this when: You're generating additional examples to expand an existing dataset.
2. Human-in-the-Loop Review
Have annotators validate, edit, or reject LLM-generated outputs. This helps:
- Ensure relevance (e.g., is the generated question actually answerable from the input?)
- Improve fluency and factual accuracy
- Catch hallucinations or misclassifications
Label Studio makes this easy by letting users convert predictions to editable annotations with one click.
Use this when: You’re seeding a dataset from scratch and want to maintain quality control.
3. Back-Evaluation Through Downstream Tasks
Use your synthetic data to train or fine-tune a model, then evaluate that model’s performance on a separate test set. This helps you indirectly measure whether the synthetic examples improved the model’s real-world behavior.
Use this when: You’re generating training data for a specific application (like RAG or classification).
4. Dual-LLM Evaluation (With Caution)
Some teams experiment with using one LLM to generate data and a second to evaluate it. While not a substitute for human review, this can help triage large volumes of outputs.
Use this when: You have massive output volume and need an automated first pass.
5. Statistical Audits and Distribution Checks
Check for consistency across:
- Label distribution (e.g., over-representation of certain genres or types)
- Input diversity
- Length and complexity of generated outputs
Use this when: You want to ensure synthetic data isn’t skewing your dataset in unexpected ways.
Ready to Try It Yourself?
Whether you're building a RAG pipeline or just need a faster way to bootstrap labeled data, synthetic generation with prompts gives you a flexible, cost-effective path forward. The best part? You can try it right now.
- Start your free trial of Label Studio Starter Cloud
- Join our community Slack to ask questions, share feedback, or get inspired by other users
Start experimenting and let us know what you build!
Related Content
-

Video Object Segmentation and Tracking with VideoVector tag for SAM 2 in Label Studio
Draw a box around any object and follow it as it moves instead of segmenting frame by frame.

Micaela Kaplan
July 15, 2026
-
Building A Labeling Config in Label Studio Enterprise
How do you build the right labeling interface in Label Studio? This video walks through a practical progression: start with templates, customize with XML tags, extend with React Code, and standardize workflows with plugins.
-

Learn how to connect YOLO26 to a Label Studio project using the YOLO ML Backend so annotators can start from model predictions and focus on review and correction instead of drawing boxes from scratch.
Micaela Kaplan
February 12, 2026