How to Evaluate and Compare LLMs Using Prompts in Label Studio
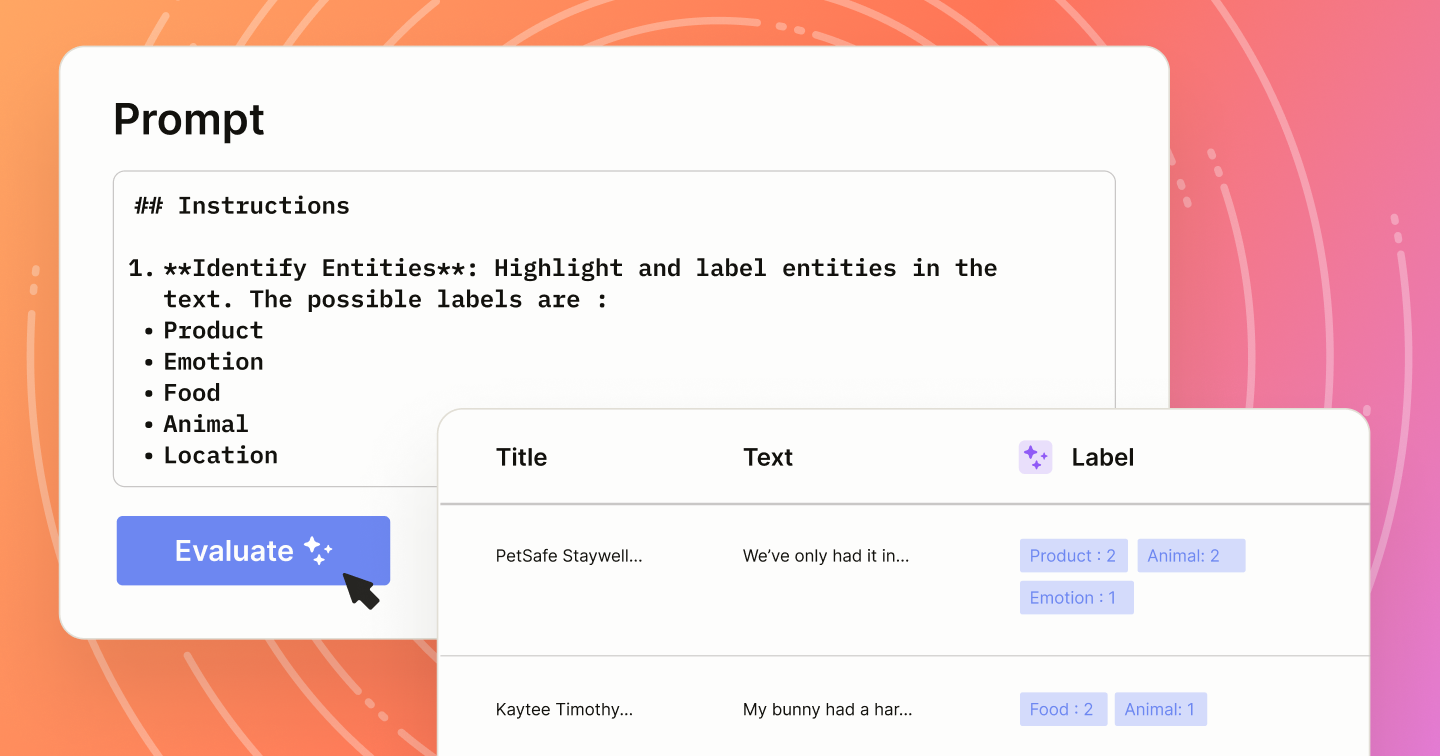
As large language models become more central to labeling workflows, one question comes up again and again: how do you know if a model is performing well for your specific use case? Whether you're using an LLM to pre-label data, auto-generate annotations, or assist human reviewers, evaluating model outputs is critical to building trust and scaling your system with confidence.
In this blog, we’ll explore two approaches for assessing model quality in Label Studio. The first relies on ground truth data to generate accuracy scores. The second compares model predictions in cases where ground truth is unavailable, helping you identify gaps and make informed decisions about which models to use or fine-tune.
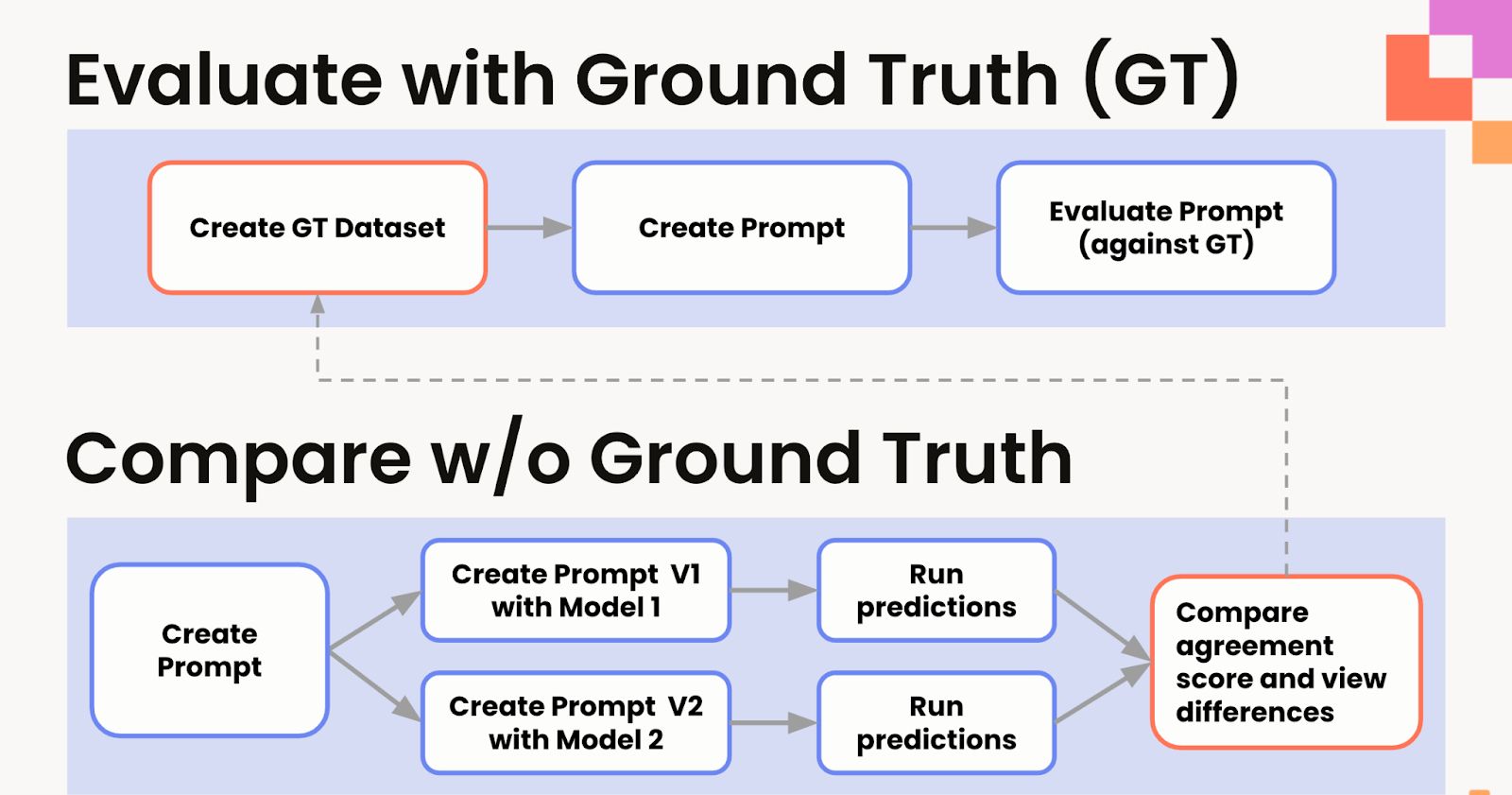
Why LLM Evaluation Needs Structure
Using LLMs to label data offers a major speed boost, but without a clear evaluation method, it's easy to lose track of quality. Manual inspection is time-consuming and subjective. What’s needed is a structured, repeatable way to compare outputs, both against existing annotations and across different models or prompt versions.
Label Studio’s Prompts feature makes this possible. It allows users to:
- Connect to leading model providers or custom endpoints
- Build and version prompts directly within the UI
- Run evaluations on any project, with or without ground truth
- Compare results side by side
- Automatically annotate tasks with selected model outputs
With Prompts, you get a complete loop for testing, improving, and operationalizing LLM-based labeling. You can try Prompts within Label Studio by signing up for a free trial of Label Studio Starter Cloud here! (The trial includes some free OpenAI credits to test roughly 10,000 annotations with.)
Workflow 1: Evaluate with Ground Truth
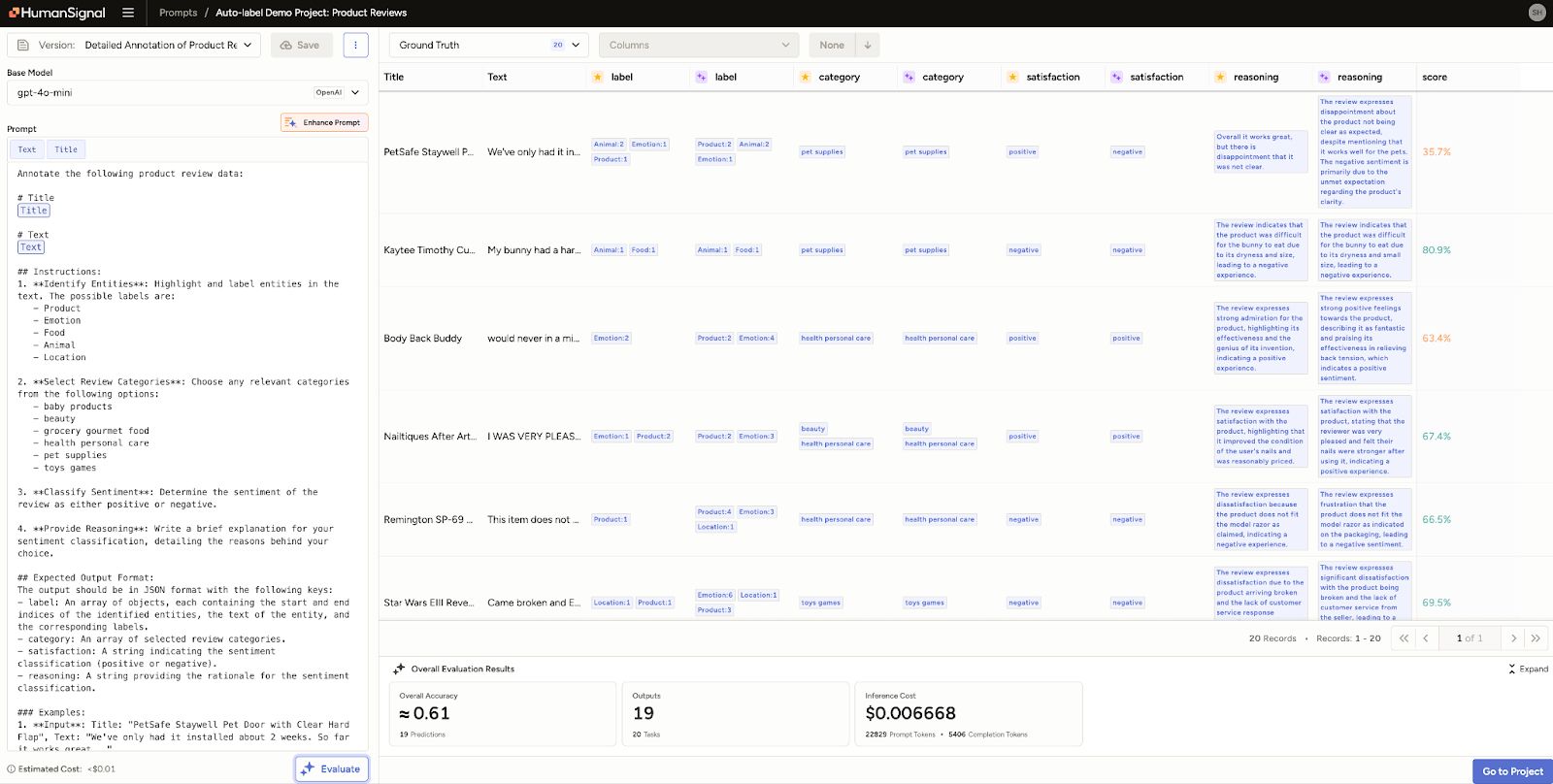
When you already have a labeled dataset, evaluating a model is straightforward. In Label Studio, this starts by marking a subset of tasks as ground truth. You can then run a prompt using a selected base model and compare the model's predictions to the ground truth annotations.
Label Studio displays both outputs side by side, highlighting differences. It also calculates an agreement score for each task, as well as a macro-level score across all evaluated tasks. This helps you answer questions like:
- How close is the model output to human-reviewed labels?
- Are there specific types of inputs where the model underperforms?
- What’s the cost-performance tradeoff across different models?
You can also evaluate multiple models or prompt variations within the same interface by creating new prompt versions. Each version is stored with its associated model, instruction, and results, making it easy to track what changes had the biggest impact.
Use Case: Image Captioning with Pre-Labeled Data
In the live workshop, the team walked through a real-world image captioning project. The dataset contained 200 images that needed both classification and descriptive captions. Rather than labeling each image from scratch, the team used Prompts to test two models—GPT-4 and Gemini 1.5 Pro—against a small ground truth set.
Despite similar accuracy scores, Gemini delivered comparable results at a significantly lower cost. This allowed participants to see firsthand how tradeoffs between performance and price can shape production decisions.
Workflow 2: Compare Without Ground Truth
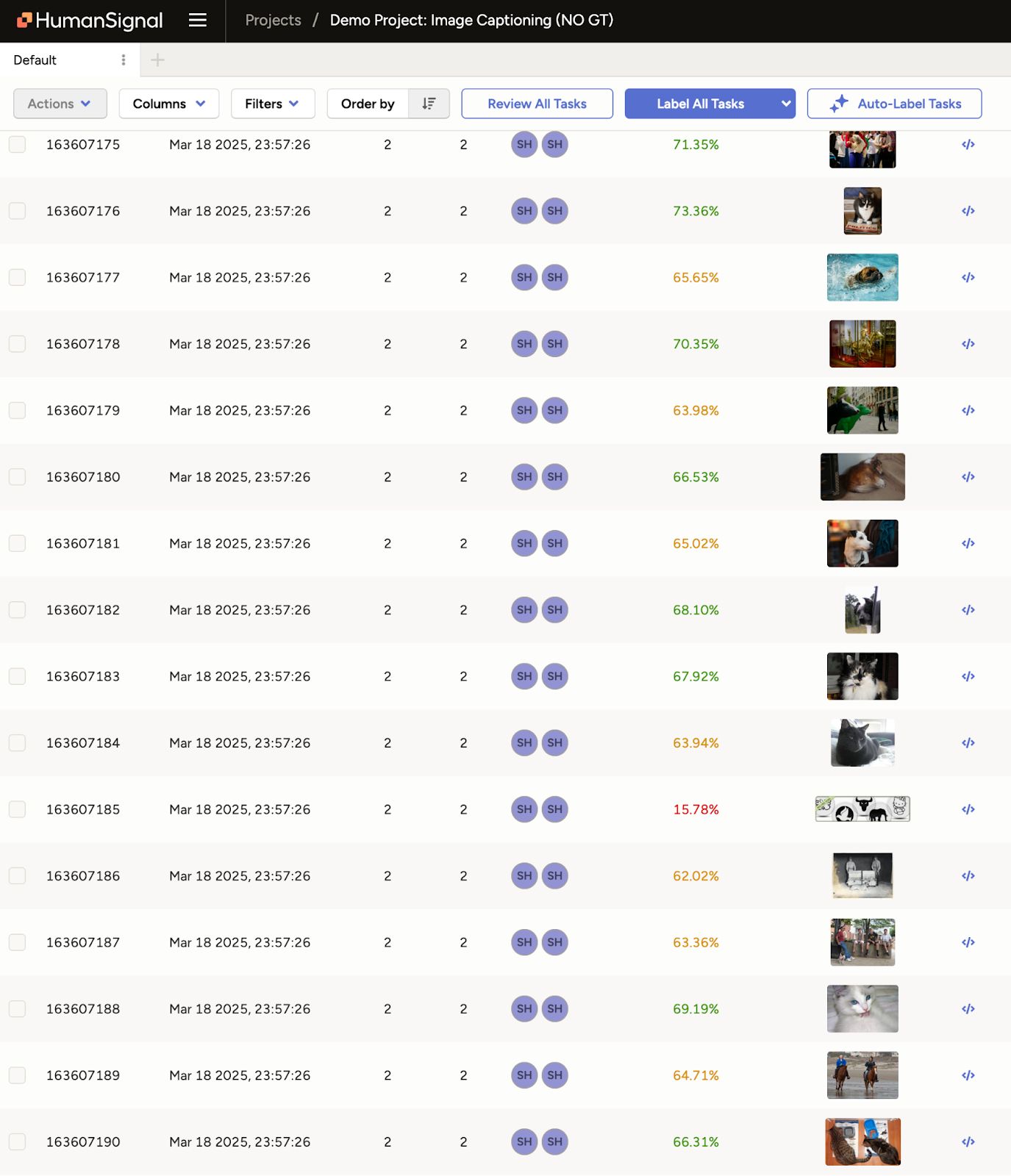
When ground truth isn't available, Label Studio still gives you a way to evaluate. Instead of comparing model outputs to existing annotations, you compare two different model predictions to each other.
The steps look like this:
- Run a prompt using Model A on your dataset
- Save the predictions as annotations
- Run a prompt using Model B on the same dataset
- Save those predictions as well
- Use Label Studio’s agreement scoring to compare the annotations
This approach helps identify disagreement areas where model behavior diverges. Those tasks often represent edge cases, ambiguous inputs, or gaps in model coverage.
From there, you can prioritize human review on the most problematic tasks or convert them into new ground truth examples. This iterative workflow helps you bootstrap evaluation even in early-stage projects.
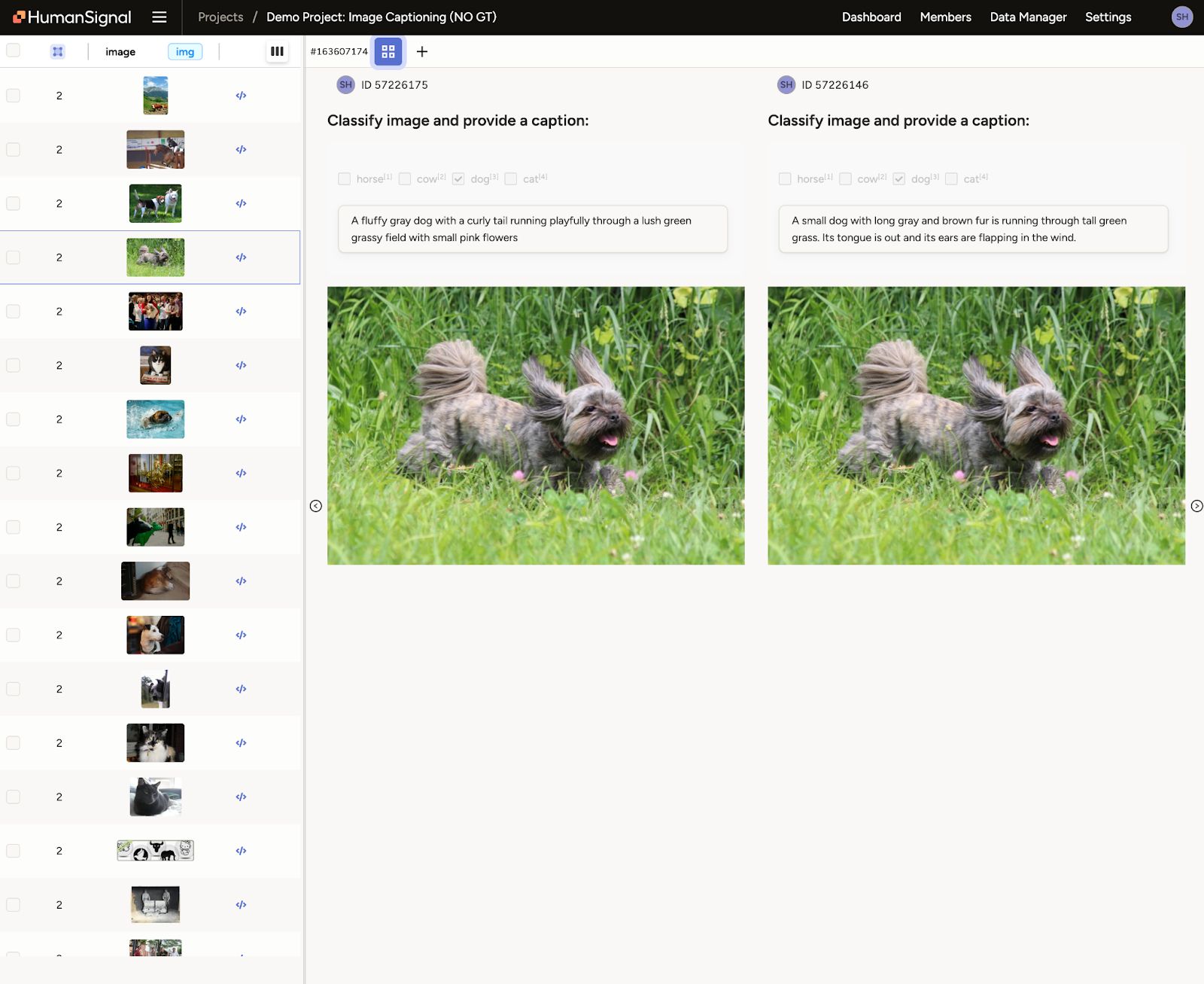
Use Case: PII Detection and Summarization
Another example covered in the session was a text-based project involving conversation transcripts. The task was to detect PII and summarize call topics. Two models, Claude Haiku and GPT-4, were run on the same inputs, and their outputs were compared.
By converting predictions into annotations and scoring agreement, the team quickly pinpointed where the models aligned and where they diverged. This helped highlight sensitive cases that warranted closer inspection and potential ground truth creation.
Track Model Cost Alongside Accuracy
When evaluating models, performance isn’t the only metric that matters. Label Studio also tracks inference cost, giving you visibility into what it would take to scale a particular model across your full dataset.
For example, if two models have similar agreement scores but one is three times more expensive, that may influence which model you deploy for production pre-labeling or auto-annotation. Being able to balance quality and cost is essential when scaling human-in-the-loop systems.
Flexible Evaluation for Any Data Type
The workflows described above work for both text and image tasks and support a wide range of annotation types, including:
- Text classification
- Named entity recognition (NER)
- Text summarization and extraction
- Image captioning and classification
Prompts can be used with standard LLMs or connected to custom models hosted in your own environment. You can also customize agreement metrics in the settings, allowing for more advanced evaluations beyond simple accuracy.
Building Confidence, One Prompt at a Time
Evaluating and comparing models shouldn't require writing scripts or manually reviewing every output. Prompts in Label Studio give teams a fast, structured way to test models, adjust prompts, and build better labeling workflows over time.
Whether you're working with ground truth or starting from scratch, you can use these tools to build trust in your model’s predictions and speed up your data pipeline with confidence.
Watch the full webinar below:
Related Content
-

Video Object Segmentation and Tracking with VideoVector tag for SAM 2 in Label Studio
Draw a box around any object and follow it as it moves instead of segmenting frame by frame.

Micaela Kaplan
July 15, 2026
-
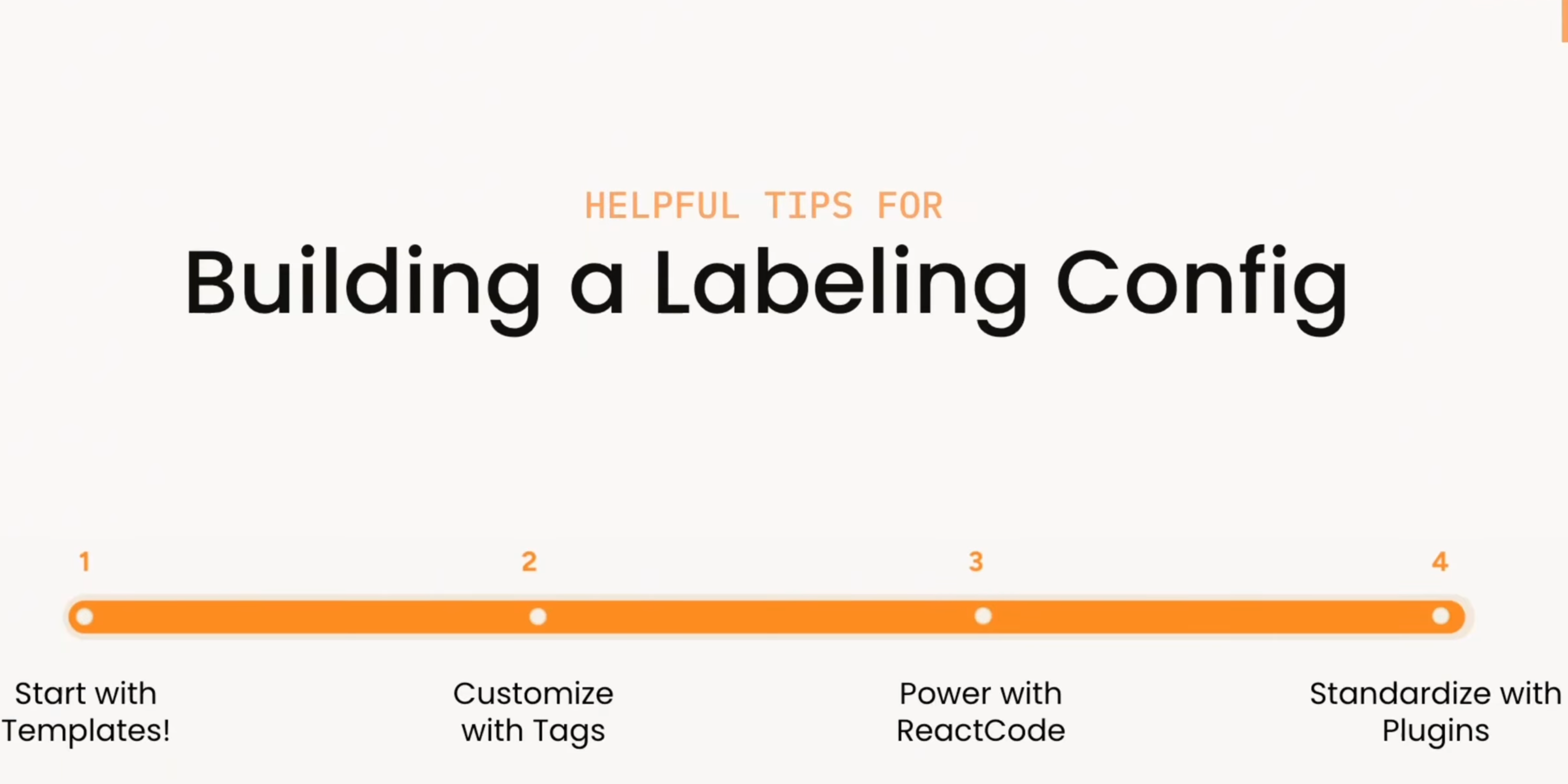
Building A Labeling Config in Label Studio Enterprise
How do you build the right labeling interface in Label Studio? This video walks through a practical progression: start with templates, customize with XML tags, extend with React Code, and standardize workflows with plugins.
-

Learn how to connect YOLO26 to a Label Studio project using the YOLO ML Backend so annotators can start from model predictions and focus on review and correction instead of drawing boxes from scratch.
Micaela Kaplan
February 12, 2026