Improving RAG Document Search Quality with Cohere Re-ranking

This article is part of a longer series that will teach you how to develop and optimize a question-answering (QA) system using Retrieval-Augmented Generation (RAG) architecture. Before you go further, we suggest you begin by starting here.
In this tutorial, we are going to show you how to create a retriever that selects relevant documents from a library, and then we will create a generator that builds responses based on those documents.
Because the quality of the answers generated by the LLM is primarily determined by the retrieved documents used as context, we are also going to show you how to improve the document search model by training a re-ranker model.
Together we’ll:
- Build a knowledge database with embeddings. Here we will use Label Studio’s GitHub documentation as the dataset and ChromaDB for embeddings.
- Set up a retrieval system using LangChain.
- Use OpenAI's GPT-4o LLM for answer generation.
- Integrate Label Studio to the QA system.
- Build an OpenAI GPT powered re-ranker for pre-labeling.
- Train a Cohere re-ranker on Label Studio annotations.
- Use the Cohere re-ranker within the RAG QA system.
Google Colab
We have provided a Google Colab notebook that contains all the code demonstrated in this tutorial.
https://colab.research.google.com/drive/1wGxKQHXPr3Dy-PjMThMda4FkbmfAmwMO?usp=sharing
Prerequisites
First, let’s ensure we have everything needed to get started.
1. Label Studio and ML backends
You should install Label Studio 1.12 (or you can use Label Studio Enterprise Cloud: https://app.humansignal.com).
pip install label-studio==1.12
label-studioAdditionally, you need to download the Label Studio ML Backend repository from the GitHub branch “feat-cohere-reranker”. It is highly recommended to run ML Backends using Docker Compose.
2. Install Required Libraries
For this tutorial we’ll be using LangChain, Cohere, and OpenAI. You can install the necessary Python libraries using pip. Run the following command in your Python environment:
!pip install git-python langchain langchain-community openai
langchain_openai cohere chromadb tiktoken label_studio_sdk tqdm3. Get Necessary API Keys
You'll need API keys from OpenAI, Cohere, and Label Studio. These keys are essential for accessing their respective services:
- OPENAI_API_KEY: Register and obtain your key from OpenAI here.
- CO_API_KEY: Sign up with Cohere to get your key here. Note: Cohere is free but it has limited API rates.
- LABEL_STUDIO_URL: http/https URL for your Label Studio instance.
- LABEL_STUDIO_API_KEY: This can be found on your account page in Label Studio.
Then run the following command, don’t forget to insert your keys and your Label Studio URL (it should start with http/https):
import os
os.environ['OPENAI_API_KEY']=""
os.environ['CO_API_KEY']=""
os.environ['LABEL_STUDIO_API_KEY']=""
os.environ['LABEL_STUDIO_URL']=""Build a RAG QA System
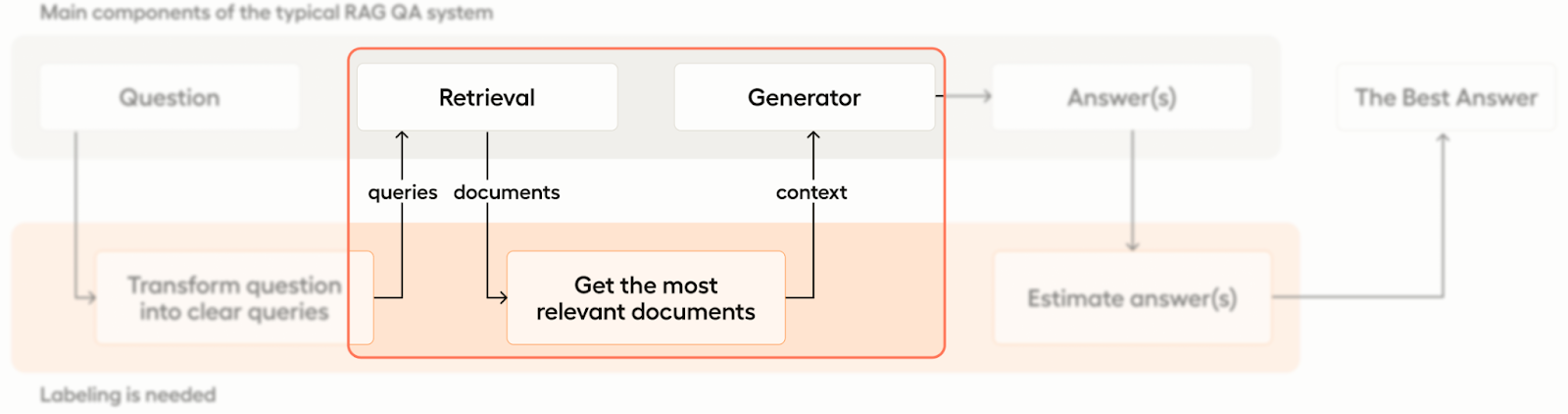
Let’s begin with a quick overview of how our RAG system will be structured and where labeling is needed.
As mentioned above, there are two main components of our RAG system - the retriever and the generator. The system is designed to take input in the form of a question and convert that question into a query that is then handed to the retrieval component. The retrieval system then uses the query to identify and pull relevant documents and return them to the generator component, which then generates an answer to the question.
The first step in building our RAG pipeline is to create a vector database with embeddings for the retrieval system to refer to. First we’ll establish the unstructured document source, then we’ll generate the embeddings.
1. Import Unstructured Data
We’ll use the Label Studio documentation for our unstructured document database. This documentation is accessible in GitHub as markdown files. LangChain facilitates this process, allowing us to establish our database efficiently with just a few lines of code.
import os
from git import Repo
from langchain.document_loaders.git import GitLoader
from langchain.text_splitter import MarkdownTextSplitter
# Download label-studio github repo to get md docs
repo_url = "https://github.com/HumanSignal/label-studio"
repo_path = "./data/label-studio-repo"
# if repo is already cloned, just open it
repo = Repo(repo_path) if os.path.exists(repo_path) else Repo.clone_from(repo_url, to_path=repo_path)
branch = repo.head.reference
loader = GitLoader(repo_path=repo_path, branch=branch, file_filter=lambda f: f.endswith('.md'))
data = loader.load()
# split docs into chunks for better embedding performance
text_splitter = MarkdownTextSplitter(chunk_size=500, chunk_overlap=250)
all_splits = text_splitter.split_documents(data)2. Use ChromaDB for Document Embeddings
To enhance the capabilities of our QA system, we’ll employ ChromaDB as our vector database. ChromaDB stores document embeddings, which are essential for comparing and retrieving documents based on semantic similarity rather than traditional keyword matching.
# Split the documents into chunks and make embeddings
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())# check how many docs we have in DB
vectorstore._collection.count()
# Out: 52723. Set Up Retrieval
Now that our unstructured document database and vector database are set up with document embeddings in ChromaDB, we can start retrieving relevant documents based on user queries:
question = "How to save tasks in storage?" vectorstore.similarity_search_with_relevance_scores(question)# Out:
[(Document(page_content='Your window will look like this:\n<img src="/images/local-storage-settings2.png" alt="Screenshot of the local storage settings for user task." class="gif-border">\n\nClick **Add Storage**, but not use synchronization (don\'t touch button **Sync Storage**) after the storage creation, to avoid automatic task creation from storage files.', metadata={'file_name': 'storage.md', 'file_path': 'docs/source/guide/storage.md', 'file_type': '.md', 'source': 'docs/source/guide/storage.md'}), 0.8026583189549272),
(Document(page_content='After adding the storage, click **Sync** to collect tasks from the database, or make an API call to [sync import storage](/api#operation/api_storages_redis_sync_create).', metadata={'file_name': 'storage.md', 'file_path': 'docs/source/guide/storage.md', 'file_type': '.md', 'source': 'docs/source/guide/storage.md'}), 0.7915639829479804),
(Document(page_content='After adding the storage, click **Sync** to collect tasks from the bucket, or make an API call to [sync import storage](/api#operation/api_storages_localfiles_sync_create).\n\n### Tasks with local storage file references \nIn cases where your tasks have multiple or complex input sources, such as multiple object tags in the labeling config or a HyperText tag with custom data values, you must prepare tasks manually.', metadata={'file_name': 'storage.md', 'file_path': 'docs/source/guide/storage.md', 'file_type': '.md', 'source': 'docs/source/guide/storage.md'}), 0.7857555360938758),
(Document(page_content='After adding the storage, click **Sync** to collect tasks from the container, or make an API call to [sync import storage](/api#operation/api_storages_azure_sync_create).', metadata={'file_name': 'storage.md', 'file_path': 'docs/source/guide/storage.md', 'file_type': '.md', 'source': 'docs/source/guide/storage.md'}), 0.7818900168092748)]4. Connect an LLM generator
Now let’s take a look at integrating the answer generation component. For this, you can use OpenAI's GPT-3.5 model for its speed. However, if you want better performance, we recommend using GPT-4o.
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
def generate_answer(question):
template = """Use the following pieces of context to answer the question at the end.\n
Context:\n{context}\n\n
Question:\n{question}\n\n
Your answer:
"""
prompt = PromptTemplate.from_template(template)
llm = ChatOpenAI(model="gpt-4o")
# Retrieve documents based on the question
# We use the high top k = 50, because we are going to rerank them
retrieved_docs = vectorstore.similarity_search(question, k=50)
# Format for passing context to the LLM
context = "\n\n".join(doc.page_content for doc in retrieved_docs)
formatted_input = prompt.format(context=context, question=question)
# Run LLM
response = llm.invoke(formatted_input)
parsed_response = StrOutputParser().parse(response)
# Return both the answer and the documents
return parsed_response.content, retrieved_docs
answer = generate_answer("How to save tasks in storage?")
print(answer[0])# Out:
To save tasks in storage using Label Studio, follow these steps:
1. **Open Label Studio**: Open Label Studio in your web browser.
2. **Navigate to Cloud Storage Settings**: For a specific project, go to **Settings > Cloud Storage**.
3. **Add Source Storage**:
- Click **Add Source Storage**.
- In the dialog box, select the storage type (e.g., Local Files, Amazon S3, Redis Database, etc.).
- Fill out the necessary fields, such as **Storage Title** and other configuration parameters specific to the storage type you selected.
4. **Sync Storage**:
- After adding the storage, click **Sync** to collect tasks from the storage bucket, database, or local directory.
- Alternatively, you can make an API call to sync import storage (e.g., for S3, GCS, Azure, etc., using the provided API endpoints).
5. **Import Tasks**:
- If you're importing JSON files directly, ensure that each JSON file contains one task if placed in a cloud storage bucket.
- If you are uploading a JSON file from your machine, you can include multiple tasks in one JSON file and import it via the Label Studio GUI by going to the Data Manager page, clicking the **Import** button, and dragging and dropping the file.
6. **Add Target Storage (Optional)**:
- For exporting completed annotations, repeat the steps for **Add Target Storage** to use a local file directory, cloud bucket, or database as the target storage. This ensures that annotated data is saved in the specified location.
### Additional Tips:
- **Complex Tasks**: For tasks with multiple input sources or complex configurations, you may need to prepare tasks manually and disable automatic task creation from media files.
- **Local Storage**: If you are using local storage, ensure that the **Absolute local path** leads to the directory with the files you want to include in the tasks.
- **Export Annotations**: After labeling, you can export the annotations from Label Studio, which are saved in JSON format in the specified target storage.
By following these steps, you can effectively save and manage tasks in Label Studio storage.Congratulations! You’ve established an enhanced RAG QA system using Label Studio! You can now query the system and get responses back through the LLM.
Problem
Embeddings, while powerful, are not flawless. To extract the most relevant documents from the KDB for user queries, you can fine-tune embeddings specifically for your domain. Additionally, re-ranking the search results can ensure the most pertinent documents appear first. You can also limit search results to the top 5 after re-ranking. This will reduce LLM hallucinations and make the answers more accurate.
This process requires a robust training dataset composed of positive examples and hard-negative examples, which are essential for training with the triplet-loss function.
Solution: Labeling, OpenAI and Cohere Rerankers
Utilizing LLM models can facilitate the pre-labeling for the classification of positive and negative documents, albeit somewhat slowly. This method is effective for establishing a solid starting point for further refinements. Initially, we will employ an OpenAI model to generate Label Studio pre-annotations.
Subsequently, these annotations will be used to train a Cohere re-ranking model, which can then be deployed in production to enhance the relevance of search results.
This workflow is illustrated below:

Integrate Label Studio with the QA System
Video Tutorial
As we jump into the tutorial, feel free to check out this accompanying video on integrating Label Studio, OpenAI, and Cohere with the Label Studio ML backend. It demonstrates the steps described below starting from 1. Integrate Label Studio and Get Tasks.
Labeling Config for Label Studio
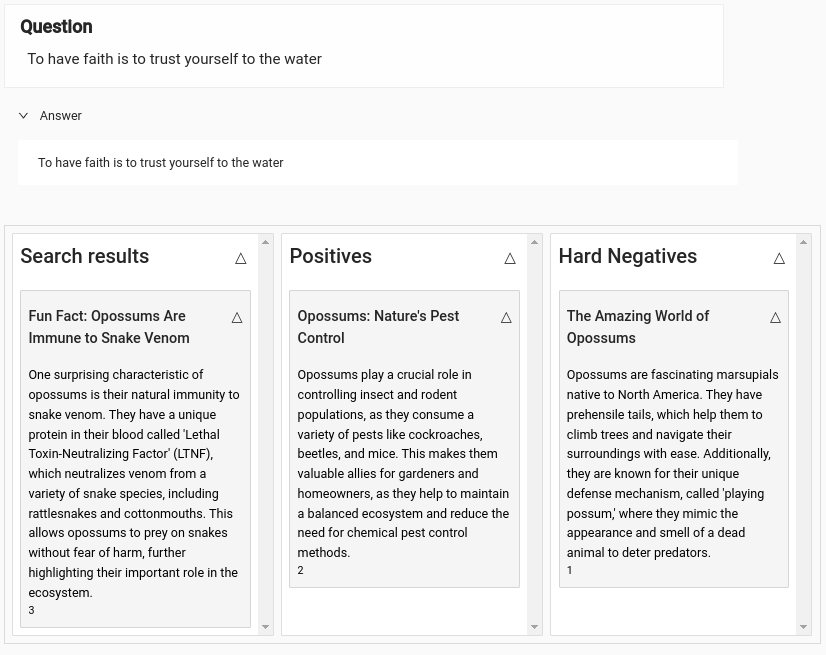
We will be using Label Studio to help manage the re-ranking training process. In the following labeling configuration, annotators are presented with a list of documents that are similar to the user's question. They are tasked with selecting the most relevant documents, which are placed in the "Positives" bucket. They must also identify and categorize the hard-negative documents — those that are similar but not relevant — into the "Hard Negatives" bucket. Documents that do not fit into these categories should be skipped.
To facilitate a deeper understanding of the context behind the user's question, additional fields are provided for the user's question itself and the corresponding answer. This context is crucial for annotators to make informed decisions regarding the relevance of each document.
<View>
<Style>
.htx-text { white-space: pre-wrap; }
.question {
font-size: 120%;
width: 800px;
margin-bottom: 0.5em;
border: 1px solid #eee;
padding: 0 1em 1em 1em;
background: #fefefe;
}
.answer {
font-size: 100%;
width: 800px;
background: #fff !important;
padding: 1em;
}
.doc-body {
white-space: pre-wrap;
overflow-wrap: break-word;
word-break: keep-all;
}
.doc-footer {
font-size: 85%;
overflow-wrap: break-word;
word-break: keep-all;
}
h3 + p + p { font-size: 85%; } /* doc id */
</Style>
<View className="question">
<Header value="Question"/>
<Text name="question" value="$question" />
</View>
<Collapse>
<Panel value="Answer">
<View className="answer">
<Text name="answer" value="$answer" />
</View>
</Panel>
</Collapse>
<View style="margin-top: 2em">
<List name="results" value="$similar_docs" title="Search results" />
<Ranker name="rank" toName="results">
<Bucket name="positives" title="Positives" />
<Bucket name="hard_negatives" title="Hard Negatives" />
</Ranker>
</View>
</View>
Task Example
{
"question": "When editing “Source Cloud Storage” of “AWS S3 (IAM role access)”, the three toggles below will always be turned on in the “Edit Source Storage” window.",
"answer": "I recommend reaching out with specific details so that the support team can escalate the issue appropriately.",
"similar_docs": [
{
"id": "id1",
"title": "document 1",
"html": "<i>Could you also comment</i> on the pre-signed url for images? I'm wondering why it needed to be turned on for PDF documents in S3. <a href='http://example.com'>link1</a>",
"page_content": "Clean text without html tags here: Could you also comment on the pre-signed url for images? I'm wondering why it needed to be turned on for PDF documents in S3."
},
{
"id": "id2",
"title": "document 2",
"html": "<h4>Please note!!!!</h4> The first link references the json file itself. <a href='http://example.com'>link 2</a>",
"page_content": "Please note!!!! The first link references the json file itself."
}
]
}
1. Integrate Label Studio and Get Tasks
1.1. Create a New Project: Start by setting up a new project using the labeling configuration outlined above.
1.2. Obtain Project ID: After creating the project in Label Studio, retrieve the project ID from the browser address bar (e.g. http://app.heartex.com/projects/<id>).
1.3 Populate the Project: The next step involves populating the project with user questions and the corresponding retrieved documents. Utilize the helper class provided by Label Studio for importing tasks:
import os
import time
import requests
import logging
from label_studio_sdk import Client
from langchain.docstore.document import Document
from typing import List
logger = logging.getLogger(__name__)
class LabelStudioImportQuestionAndSimilarDocs:
""" This class is used to import questions and similar documents to the Label Studio project.
"""
def __init__(
self,
url: str,
api_key: str = os.getenv("LABEL_STUDIO_API_KEY"),
project_id: int = int(os.getenv("LABEL_STUDIO_PROJECT_ID", 0)),
):
""" Initialize the Label Studio RAG client
:param url: Label Studio URL
:param api_key: Label Studio API key
:param project_id: Label Studio project ID
should return one of the following: "positives", "hard_negatives" or None
"""
self.url = url
self.api_key = api_key
self.project_id = project_id
if not self.api_key:
raise ValueError("LABEL_STUDIO_API_KEY is not set")
if not self.project_id:
raise ValueError("LABEL_STUDIO_PROJECT_ID is not set")
# Initialize the Label Studio SDK client
self.ls = Client(url=self.url, api_key=self.api_key)
self.project = self.ls.get_project(project_id)
self.tasks = []
def add_question_with_similar_docs(
self,
question: str,
similar_docs: List[Document],
answer: str
):
""" Add a question and similar documents to Label Studio
:param question: str, question to ask
:param similar_docs: List[Document], list of similar documents to questions
:param answer: str, generated answer to the question
"""
# Initialize a task
task = {"data": {"question": question, "similar_docs": [], "answer": answer}}
list_items = task["data"]["similar_docs"]
for i, doc in enumerate(similar_docs):
# Prepare pretty view of the List cards
body = (
f"<div class='doc-body'>{doc.page_content}</div><br>" +
f"<div class='doc-footer'>{doc.metadata.get('source', '')}</div>"
)
# Fill the task with List items from similar docs
list_items.append({
"id": 'id-' + str(i),
"title": doc.metadata.get('file_name', 'Untitled'),
"html": body,
"metadata": doc.metadata,
"page_content": doc.page_content,
})
logger.debug(f"Added question with {len(similar_docs)} similar docs to Label Studio")
self.tasks.append(task)
def import_tasks(self):
""" Import collected tasks to Label Studio and flash self.tasks
"""
if self.tasks:
try:
self.project.import_tasks(self.tasks)
except requests.exceptions.HTTPError as e:
logger.error(f"Error during importing tasks to Label Studio: {e}, retrying...")
time.sleep(5)
self.project.import_tasks(self.tasks)
logger.info(f"Imported {len(self.tasks)} tasks to Label Studio")
self.tasks = []1.4. Generate questions: Now we are going to ask the LLM model to generate about 256 questions for our documentation. We will iterate over all markdown files and use each of them as a context for the LLM to construct various questions covering the documentation. We need at least 256 different questions for Cohere re-ranker training.
import json
from tqdm import tqdm
def generate_questions_for_training(number=256):
""" Generate questions for training the Cohere reranker model
"""
# Concatenate md files as a context for getting questions
guide_dir = os.path.join(repo_path, 'docs', 'source', 'guide')
files = [os.path.join(guide_dir, f) for f in os.listdir(guide_dir) if f.endswith('.md')]
questions = []
questions_per_file = number // len(files) + 1
for file in tqdm(files):
with open(file, 'r') as f:
context = f.read()
# Format for passing context to the LLM
formatted_input = f"""1. Use the following documentation as a context and generate {questions_per_file} questions for it as a JSON list.\n
2. Make your questions as varied as possible to cover the documentation well.\n
3. For example: ["How to label data?", "What is the best way to annotate images?", ...]. You answer must be a JSON list with strings only.\n
4. Never use ``` in the beginning and the end.\n
5. Context:\n--------------------\n\n{context}\n\n--------------------\n\n
Your questions as a JSON list:\n
"""
llm = ChatOpenAI(model="gpt-4o")
# Run LLM
response = llm.invoke(formatted_input)
parsed_response = StrOutputParser().parse(response)
try:
qs = json.loads(parsed_response.content)
except json.JSONDecodeError:
print('Error while parsing LLM answer as JSON:', parsed_response.content)
continue
questions += qs
return questions
questions = generate_questions_for_training()
questions
100%|██████████| 75/75 [01:49<00:00, 1.46s/it]
['What is the first step to set up time series and video or audio labeling?',
'Which version of Label Studio supports this time series and video/audio labeling feature?',
'How do you synchronize the time series with the video in Label Studio?',
'What are the requirements for the video and CSV file hosting for this labeling setup?',
...
1.5. Integrate with Label Studio: Next we will use the helper class LabelStudioQuestionAndSimilarDocs and the generate_questions_for_training() function to generate questions with similar docs for each question. Then we will import the generated questions into Label Studio:
# Initialize the Label Studio helper class for importing tasks
from tqdm import tqdm
ls = LabelStudioImportQuestionAndSimilarDocs(
url="https://app.heartex.com", # replace with your Label Studio URL
api_key=os.getenv("LABEL_STUDIO_API_KEY"), # replace with your Label Studio API key
project_id=66886 # replace with your Label Studio Project ID
)
# ask lots of questions and get similar docs
for question in tqdm(questions):
answer, docs = generate_answer(question)
# add a question with similar docs to Label Studio
ls.add_question_with_similar_docs(question, docs, answer)
# finally import all collected tasks
print('Import started ...')
ls.import_tasks()
print('Tasks have been imported to Label Studio!')100%|██████████| 300/300 [00:00<00:00, 1033079.80it/s]
Import started ...
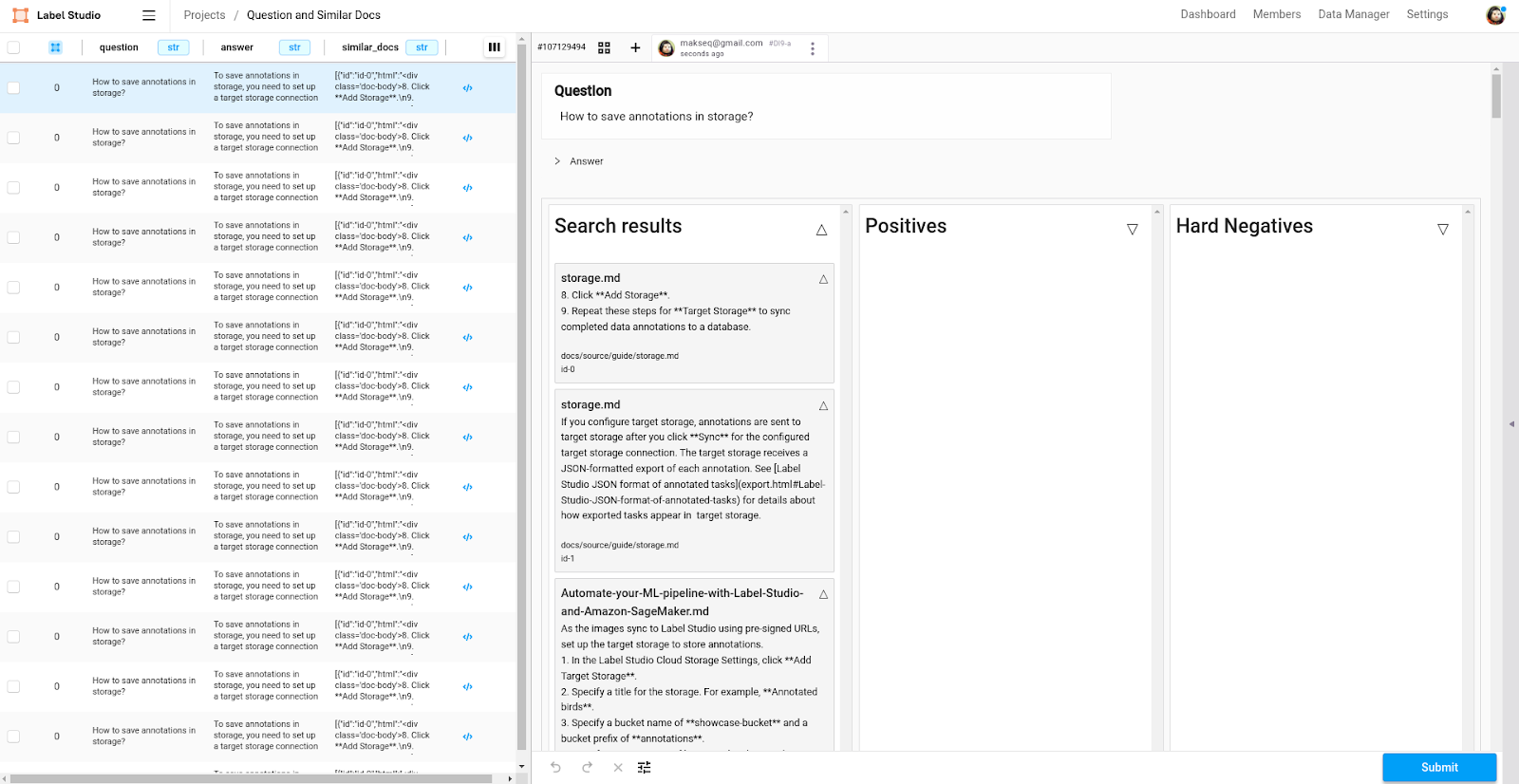
Tasks have been imported to Label Studio!Once complete, you should be able to see the newly generated tasks in the Label Studio project:
2. Pre-label with OpenAI
2.1. Connect OpenAI ML Backend: Link the OpenAI ML Backend to get pre-labeling for your tasks. Read more about the model connection in the Label Studio documentation.
Quickstart:
# Clone Label Studio ML backends repo
git clone --branch feat-cohere-reranker https://github.com/HumanSignal/label-studio-ml-backend.git
# Open the folder with OpenAI Reranker
cd label-studio-ml-backend/label_studio_ml/examples/rerankers/openai_reranker
# (Necessary) Edit docker-compose.yml and insert OpenAI and Label Studio API Keys and URL
# Run ML backend
docker-compose up --build # or docker compose up --build
# (Optional) If Label Studio is outside, use ngrock (https://ngrok.com/)
# ./ngrok http 9090From Label Studio, open your project and go to Settings > Model. Add a new model with the URL http://localhost:9090 (docker-compose.yml maps to port 9090 of your localhost; use an ngrok URL if needed).
To begin retrieving, go to the Data Manager and select all tasks. Then select Actions > Retrieve Predictions (or Batch Predictions if you’re using Label Studio Enterprise). This process typically takes about 10 minutes to complete. To monitor the progress, refresh the Data Manager page periodically and watch the task and annotation counters in the top right corner.
Note: It is a known issue that the OpenAI model can hang and fail to complete all predictions. If this happens, use the Data Manager filters to select all tasks without predictions and re-run the Retrieve Predictions action.
2.2. Convert Predictions to Annotations: When all tasks have predictions from the OpenAI model, refresh the Data Manager page. This updates the models available to select when creating annotations from predictions. Select all tasks and then select Actions > Create Annotations from Predictions. In the drop-down menu, select a “reranker-openai-...” version and click OK. This will convert the retrieved predictions from the OpenAI model into usable annotations within your project. Don’t perform this action until all tasks have predictions from the OpenAI model.
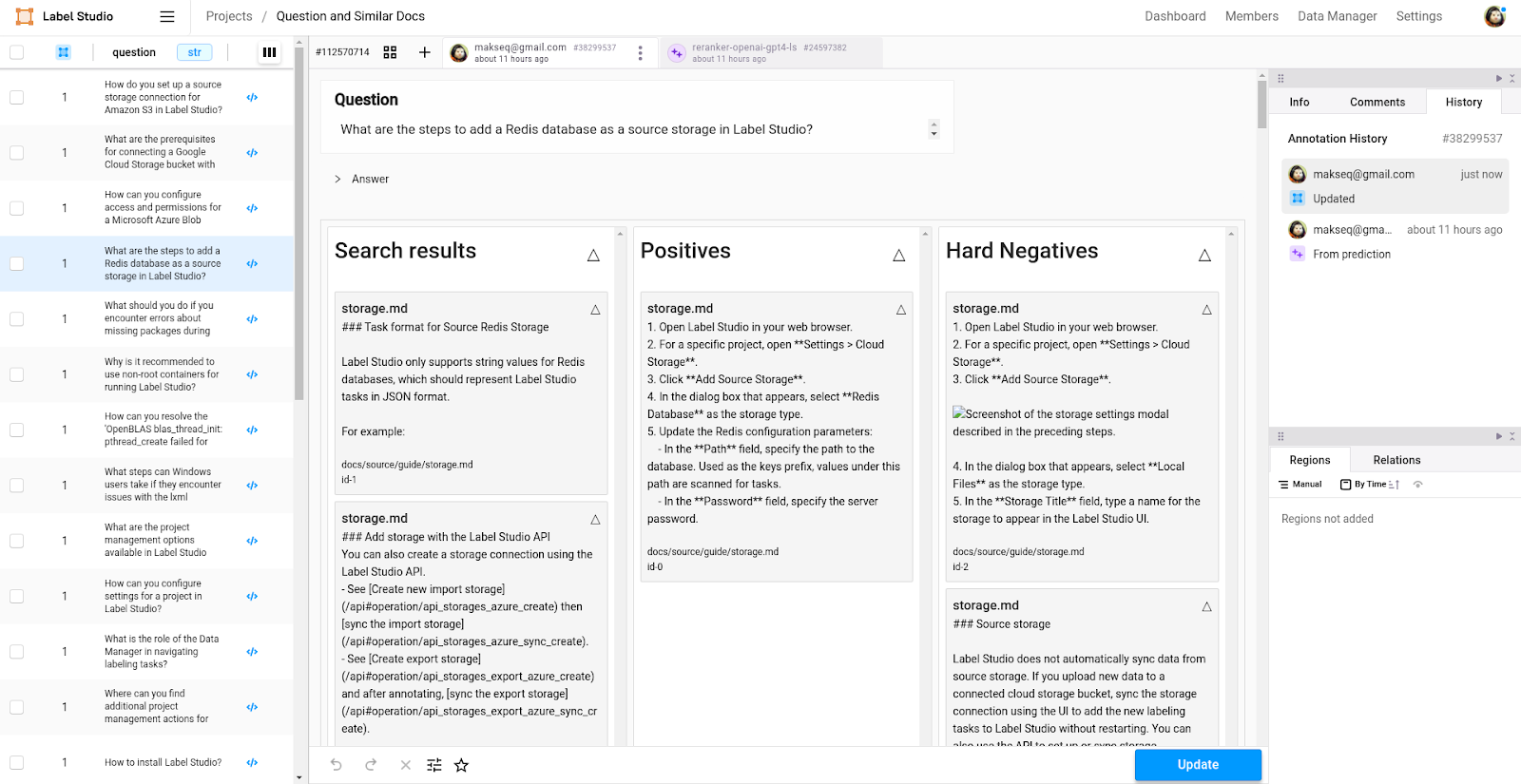
3. Annotate with Label Studio
Check and Fix Pre-labeling: Look over the tasks in the Data Manager, checking how positives and hard negatives are distributed across buckets. Fix the errors and update annotations.
4. Train Cohere Re-ranker Based on Label Studio Annotations
4.1. Switch to Cohere ML Backend: After generating the initial set of annotations with the OpenAI ML backend, disconnect it and connect the Cohere ML Backend. This change is necessary to prepare for training the re-ranking model.
The steps are very similar to (2.1), but you have to use the cohere_reranker folder and provide CO_API_KEY in docker-compose.yml.
4.2. Train the Cohere re-ranking Model: Navigate to Project Settings > Model. Click on the overflow menu next to the connected model and select Start Training. The Cohere ML backend will automatically fetch all tasks with annotations, convert them to the format required for Cohere, and upload them as a new dataset for model training on the Cohere platform. Training typically lasts 30-40 minutes under the free plan.
4.3. Test the Cohere re-ranking Model: Once training is complete, test the re-ranking model's effectiveness by selecting all tasks and choosing Batch Predictions (Retrieve Predictions) from the actions dropdown. You will get Cohere predictions, and you can inspect them in the Quickview. This step allows you to assess how well the Cohere model is improving the relevancy of search results.Note that this process can also be made continuous by constantly re-annotating, retraining, and monitoring the Cohere models, giving you a clear understanding of what is happening with your QA system.
5. Results: Enable the Cohere Reranker Model Trained on Your Documents
Once training is complete, the last step is to enable the newly trained Cohere model using the following code. It selects the Cohere model name automatically.
import cohere
CUSTOM_MODEL_VERSION = "reranker-cohere-"
co = cohere.Client(api_key=os.getenv('CO_API_KEY', 'cohere-api-key')) # replace with your Cohere API key
def get_cohere_model():
# load the last trained Cohere model
response = co.finetuning.list_finetuned_models()
models = [
model for model in response.finetuned_models
if model.name.startswith(CUSTOM_MODEL_VERSION) and model.status in ["STATUS_READY", "STATUS_PAUSED"]
]
# return the last model by created_at
models = sorted(models, key=lambda x: x.created_at, reverse=True)
if not models:
raise Exception(f'No reranker-cohere- models found: {response.finetuned_models}')
return models[0]
def rerank(query, docs, top_n=5, model="rerank-english-v3.0"):
""" Rerank the documents using Cohere model.
query: str - The query to rerank the documents.
docs: List[Document] - The documents to rerank.
top_n: int - The number of documents to return.
model: str - id of your custom model, you can know it at the Cohere platform.
return List[Document] - the reranked documents
"""
texts = [doc.page_content for doc in docs]
response = co.rerank(query=query, documents=texts, top_n=top_n, model=model)
new_docs, scores = [], []
for result in response.results:
new_docs.append(docs[result.index])
scores.append(result.relevance_score)
return new_docs, scores
def generate_answer_with_reranker(question):
template = """Use the following pieces of context to answer the question at the end.\n
Context:\n{context}\n\n
Question:\n{question}\n\n
Your answer:
"""
prompt = PromptTemplate.from_template(template)
llm = ChatOpenAI(model="gpt-4o")
retrieved_docs = vectorstore.similarity_search(question, k=50)
# Rerank the docs using Cohere model
model_name = get_cohere_model().id + '-ft'
print('Cohere model is in use:', model_name, '\n')
retrieved_docs, scores = rerank(question, retrieved_docs, model=model_name)
# Format for passing context to the LLM
context = "\n\n".join(doc.page_content for doc in retrieved_docs)
formatted_input = prompt.format(context=context, question=question)
response = llm.invoke(formatted_input)
parsed_response = StrOutputParser().parse(response)
return parsed_response.content, retrieved_docs
answer = generate_answer_with_reranker("How to save tasks in storage?")
print(answer[0])
print('\nDocuments used:\n', "\n".join([str(doc) for doc in answer[1]]))
Cohere model is in use: 1a2f46f8-b125-4acb-9590-092b814958bb-ft
To save tasks in target storage in Label Studio, follow these steps:
1. **Set Up Target Storage Connection:**
- In the Label Studio UI, create a connection to your desired target storage (e.g., an S3 bucket).
2. **Sync Completed Annotations:**
- After setting up the connection, click **Sync** to collect tasks from the bucket or make an API call to sync import storage.
- Ensure you have the correct permissions and roles (e.g., IAM roles for S3).
3. **Submit or Update Tasks:**
- When annotators click **Submit** or **Update** while labeling tasks, Label Studio saves the annotations in the database.
4. **Export Annotations:**
- At any point, you can export annotations from Label Studio.
- Configured target storage will receive a JSON-formatted export of each annotation.
5. **Sync to Target Storage:**
- Once you have configured the target storage and clicked **Sync**, the target storage will receive the JSON exports of each labeled task.
- You can find more details about the format in the Label Studio documentation, specifically the section on [Label Studio JSON format of annotated tasks](export.html#Label-Studio-JSON-format-of-annotated-tasks).
By following these steps, tasks will be saved in your configured target storage.
Documents used:
page_content='After adding the storage, click **Sync** to collect tasks from the bucket, or make an API call to [sync import storage](https://app.heartex.com/docs/api#operation/api_storages_s3s_sync_create).\n\n#### Create a target storage connection to S3 in the Label Studio UI\nIn the Label Studio UI, do the following to set up a target storage connection to save annotations in an S3 bucket with IAM role access set up:' metadata={'file_name': 'storage.md', 'file_path': 'docs/source/guide/storage.md', 'file_type': '.md', 'source': 'docs/source/guide/storage.md'}
page_content='```\n\n{% enddetails %}\n\n\n### Target storage\n\nWhen annotators click **Submit** or **Update** while labeling tasks, Label Studio saves annotations in the Label Studio database.' metadata={'file_name': 'storage.md', 'file_path': 'docs/source/guide/storage.md', 'file_type': '.md', 'source': 'docs/source/guide/storage.md'}
page_content='---\n\nAt any point in your labeling project, you can export the annotations from Label Studio. \n\nLabel Studio stores your annotations in a raw JSON format in the SQLite database backend, PostgreSQL database backend, or whichever cloud or database storage you specify as target storage. Cloud storage buckets contain one file per labeled task named `task_id.json`. For more information about syncing target storage, see [Cloud storage setup](storage.html).' metadata={'file_name': 'export.md', 'file_path': 'docs/source/guide/export.md', 'file_type': '.md', 'source': 'docs/source/guide/export.md'}
page_content='```\n9. Click **Add Storage**.\n10. Repeat these steps for **Target Storage** to sync completed data annotations to a bucket.\n\nAfter adding the storage, click **Sync** to collect tasks from the bucket, or make an API call to [sync import storage](/api#operation/api_storages_gcs_sync_create).' metadata={'file_name': 'storage.md', 'file_path': 'docs/source/guide/storage.md', 'file_type': '.md', 'source': 'docs/source/guide/storage.md'}
page_content='If you configure target storage, annotations are sent to target storage after you click **Sync** for the configured target storage connection. The target storage receives a JSON-formatted export of each annotation. See [Label Studio JSON format of annotated tasks](export.html#Label-Studio-JSON-format-of-annotated-tasks) for details about how exported tasks appear in target storage.' metadata={'file_name': 'storage.md', 'file_path': 'docs/source/guide/storage.md', 'file_type': '.md', 'source': 'docs/source/guide/storage.md'}
Compare the answer above with the answer we received earlier under Build a RAG QA System - Connect an LLM Generator. As you can see, the answer produced on the reranked documents is more relevant and more correct when compared to the answer based on documents without re-ranking
For example, the earlier answer suggests using source storage instead of target storage (“**Add Source Storage**“) and only mentions adding target storage as an optional step (“**Add Target Storage (Optional)**:”). However, there should only be one step: add a target storage.
Note the following:
- The training process usually takes about 30-40 minutes. You can check the readiness of the model in the Cohere admin area.
- Check more details about Improving the Rerank Fine-tuning Results in Cohere docs.
If you don’t use Cohere models, the service pauses and you will need to wait for the model to load.
Conclusion
That’s it! You’ve now built a RAG pipeline for your QA system and integrated and trained a Cohere re-ranking model to improve the quality of the RAG system’s document retrieval step. As you work through the tutorial, feel free to stop by our community Slack to chat with other Label Studio users about your experience. And stay tuned because we have two more tutorials coming!
Related Content
-
Introducing Ranker for Fine-Tuning LLMs, Generative AI Templates, UI Improvements
We're excited to showcase some new features we've added to Label Studio Enterprise specifically designed to help create datasets for fine-tuning Large Language Models (LLMs) like ChatGPT or LLaMA.

Nate Kartchner
June 26, 2023
-
Optimizing RAG Pipelines with Label Studio
In this introduction to our tutorial series on optimizing RAG pipelines, we'll introduce an example question answering (QA) system leveraging a Retrieval-Augmented Generation (RAG) architecture and outline three methods for optimizing your RAG pipeline utilizing Label Studio.

Max Tkachenko
May 23, 2024
-

An Introduction to Retrieval-Augmented Generation (RAG)
Get a brief overview of RAG and how it relates to LLMs, learn when you might consider using RAG, and get a summary of some challenges based on current research you should be aware of should you choose to travel down this path.
Nate Kartchner
January 11, 2024