Optimizing RAG Pipelines with Label Studio

Optimizing RAG Pipelines with Label Studio
Retrieval-Augmented Generation (RAG) pipelines have surged in popularity by enabling Large Language Models (LLMs) to retrieve contextual data in real-time and generate more relevant responses for end users. A RAG pipeline is particularly advantageous in scenarios where the knowledge base is extremely large and dynamic, such as customer support, content generation, and real-time data analysis.
While RAG pipelines offer significant advantages, they are not without limitations, especially when it comes to precision, conflicting data sources, complex queries, and adapting to dynamic data environments. Optimizing RAG systems for reliability and efficiency has become central focus for data science teams.
To demonstrate three methods to optimize RAG pipelines with Label Studio, we’re introducing a series of tutorials built around an example question answering (QA) system and RAG pipeline. We’ll provide detailed steps and code examples to build the system and implement each of the three methods. But first in this article, we’ll walk through the basic RAG pipeline structure and an overview of the three methods:
Overview of the RAG Pipeline Structure
To get started, let’s first look at a quick overview of how our RAG system will be structured and where labeling is needed.
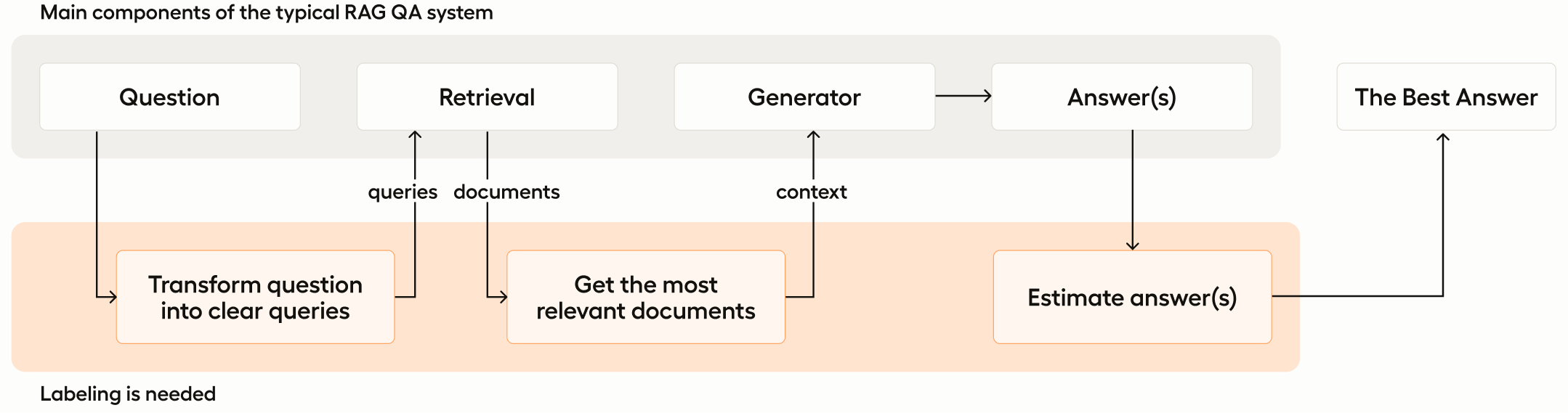
As mentioned above, there are two main components of the simple RAG system we’ll be building - the retriever and the generator. The system is designed to take input in the form of a question and convert that question into a query that is then handed to the retrieval component. The retrieval system then uses the query to identify and pull relevant documents to the query and return them to the generator component, which then generates an answer to the question.
Within this RAG pipeline structure, there are several ways for human supervision and labeling to improve the quality of your model’s results:
- You can refine user queries to better align with your domain, including decomposing complex questions into simpler, actionable queries for multi-step reasoning and categorizing questions to focus the search or tailor preprocessing approaches
- You can enhance the quality of embedding searches by re-ranking documents post-search to prioritize the most relevant documents, thereby streamlining the context
- You can craft responses based on the curated context from your knowledge database
Methods For Improving Your RAG Pipeline
Before diving in further, it’s important to note that RAG QA applications and chatbots can be fairly complex and often require tricky pipelines. Label Studio’s flexible labeling configurations make it well-suited for evaluating these models and pipelines. So based on the typical RAG architecture discussed above, let’s look at three ways that Label Studio can be used to optimize your RAG pipelines.
| Refining User Queries | Improving Document Search Quality | Controlling Generated Answers | |
| Purpose | Enhance the clarity and relevance of user queries through clarification, rephrasing, and decomposition | Improve the accuracy and relevance of retrieved documents by fine-tuning embeddings and re-ranking | Ensure the quality and appropriateness of generated answers |
| Training Examples Needed | Cleaned/rephrased questions using text query annotations | Positive and hard-negative document pairs from relevance-scored documents | Labeled responses for classification and ranking using text classification, rating scales, and text summarization |
| Human Supervision Role | Annotators clean, refine and validate user queries | Annotators judge and rank document relevance for domain-specific datasets | Annotators evaluate and rate LLM-generated responses |
| Label Studio Configurations Used | Cleaned and rephrased queries | Positive and hard-negative examples | Classification, rating, answer ranking, text summarization |
| Labeling Complexity | Moderate: Requires understanding of domain terminology | High: Involves deep understanding of domain and products | Variable: Depends on the methods used |
1. Refining User Queries
Refining user queries involves analyzing and improving the initial questions or prompts provided by users to ensure they are clear, specific, and aligned with the information needs. Clear and precise queries help the RAG system to understand the user's intent better, thereby improving the overall performance and user satisfaction. This may include rewriting ambiguous queries, breaking down complex questions into simpler components, or providing examples to guide users in formulating their queries.
There are three typical ways to optimize user questions.
- Clarification: You can clean up the original question to make it clearer and better aligned with the terminology of the knowledge base.
- Rephrasing: Modify the question into similar queries to achieve a better fit with the knowledge base.
- Decomposition: Split a complex question into several smaller queries to improve document retrieval.
To address these issues, you can demonstrate to a language model how to rephrase the original question or fine-tune the language model for this purpose, but achieving the best accuracy requires training examples. Label Studio supports this process with a specific labeling configuration and task example. The input is a user's question, and labeling is a cleaned-up version of the question, or possibly multiple rephrased text queries.
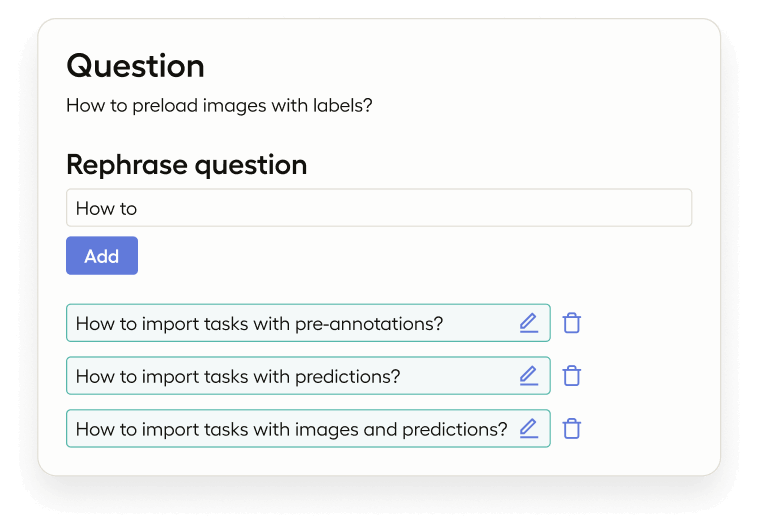
2. Improving document search quality
Improving document search quality focuses on enhancing the retrieval component of the RAG pipeline. This involves feedback mechanisms to ensure that the most relevant and high-quality documents are retrieved for each query.
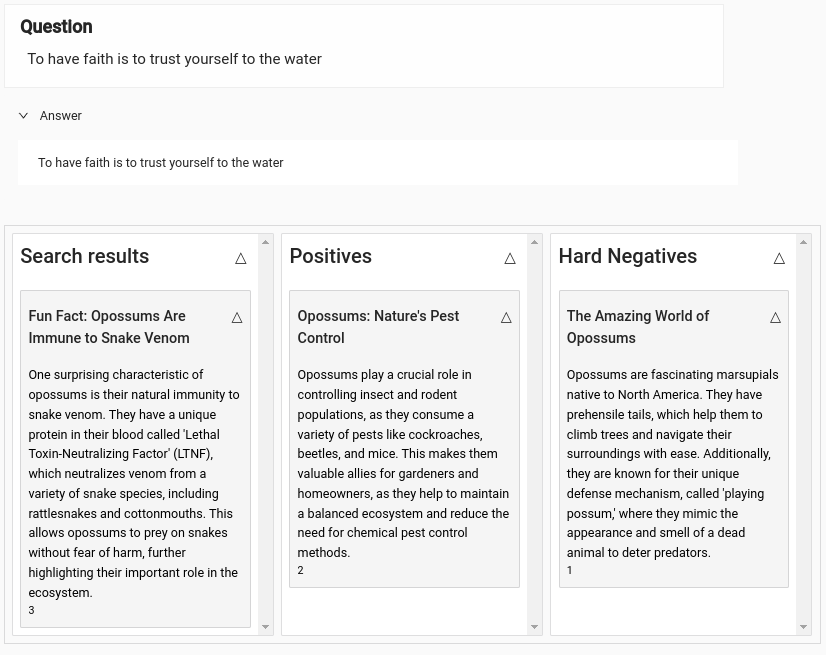
Embeddings, while powerful, are not flawless. To extract the most relevant documents from the RAG pipeline for user queries, you can fine-tune embeddings specific to your domain. Additionally, re-ranking the search results can ensure the most pertinent documents appear first. This process requires a robust training dataset composed of positive examples and hard-negative examples, which are essential for training with the triplet-loss function.
Please reference the step-by-step tutorial with code examples to improve RAG document search quality using a Cohere reranking model.
3. Controlling Generated Answers
Controlling generated answers involves implementing mechanisms to review and refine the responses produced by the generative model. Label Studio can play a critical role in this process, providing tools to manage and assess the quality of generated responses. including:
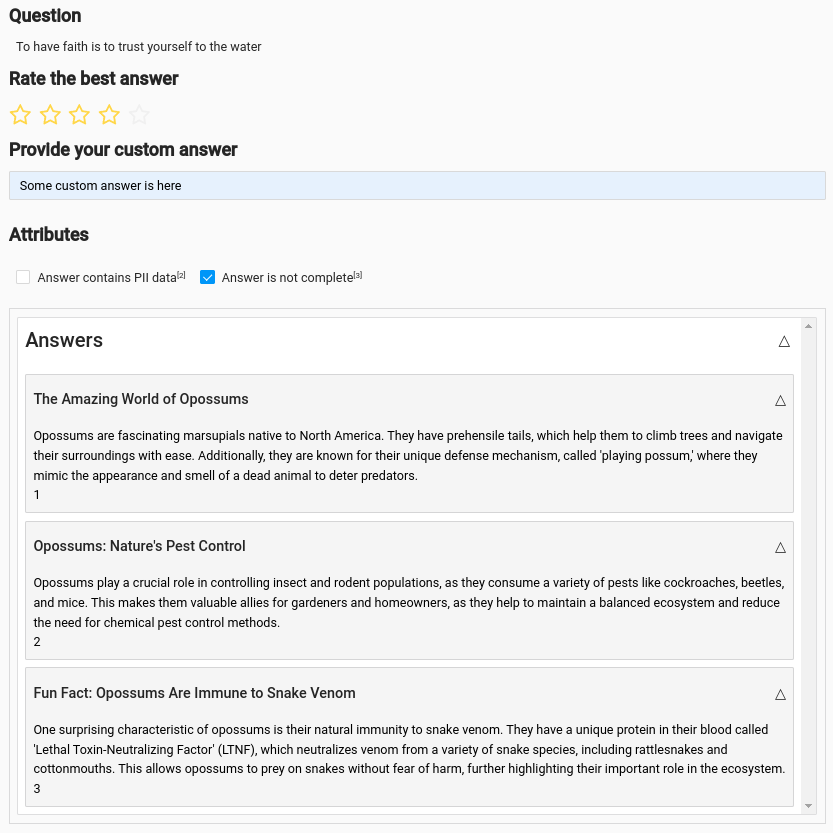
- Classify Answers: This helps to measure the system’s performance by categorizing the responses Label Studio Classification.
- Assign Ratings: Annotators can rate the answers on a scale (e.g., 1-5 stars), providing quantitative feedback on their quality Label Studio Rating.
- Rank Answers: In scenarios where multiple LLM models or approaches are used, answers can be ranked to determine which model performs best Label Studio Answer Ranking.
- Manual Answer Writing: For cases that require more precise or tailored responses, annotators can manually write answers Label Studio Text Summarization.
Label Studio serves as an effective approval tool for managing chatbot responses, particularly when urgent situations require human verification. For instance, responses to GitHub issues, which can afford a slower response time, might still benefit from human oversight. Label Studio webhooks can be configured to trigger a REVIEW_CREATED event when an answer is reviewed. If the review is accepted, the system can automatically publish the answer.
Conclusion
We’ve given you an overview of a simple RAG pipeline structure for a QA system, and the three areas where human labeling can help address errors and improve accuracy.
In the coming weeks, we will be posting hands-on tutorials to help you build your RAG pipeline, and then configure Label Studio to help you evaluate and improve your model and pipeline using each of these three methods.
And as you work through the tutorials, feel free to stop by our Discourse community to chat with other Label Studio users about your experience.
Related Content
-

Video Object Segmentation and Tracking with VideoVector tag for SAM 2 in Label Studio
Draw a box around any object and follow it as it moves instead of segmenting frame by frame.

Micaela Kaplan
July 15, 2026
-
Building A Labeling Config in Label Studio Enterprise
How do you build the right labeling interface in Label Studio? This video walks through a practical progression: start with templates, customize with XML tags, extend with React Code, and standardize workflows with plugins.
-

Learn how to connect YOLO26 to a Label Studio project using the YOLO ML Backend so annotators can start from model predictions and focus on review and correction instead of drawing boxes from scratch.
Micaela Kaplan
February 12, 2026