LLM Evaluation: Comparing Four Methods to Automatically Detect Errors
An ongoing challenge for Large Language Models (LLMs) is their tendency to hallucinate. They can create content that doesn't exist in the input, they can fabricate data, and they can make a variety of other errors that are difficult to evaluate.
Human supervision is, by far, the most effective way to address these issues, starting with a robust ground truth dataset and cycling through a feedback loop for iterative LLM training. However, this process - while effective - requires a significant effort that may not always be feasible, especially for large datasets.
In this article, we will look at four techniques for automated LLM error detection. We will use an example dataset to test and analyze each technique, sharing the results and tradeoffs, so that you can choose the best path for your own projects.
What are LLM errors?
LLM errors (or hallucinations) are unintended outputs that don't align with the given input or the context. These errors can range from minor inaccuracies to large-scale factual distortions, often making the output unreliable, misleading, or even harmful.
Example scenario: Analyzing product review helpfulness
If you have shopped online, you are familiar with product reviews.
A company might want to categorize these reviews by how helpful they are. They likely have their own unique criteria for what qualifies a review as “helpful.” However, manually evaluating each and every review against these criteria would be overly labor-intensive and costly.
Instead, let’s look at how they can use an LLM to automate the evaluation process.
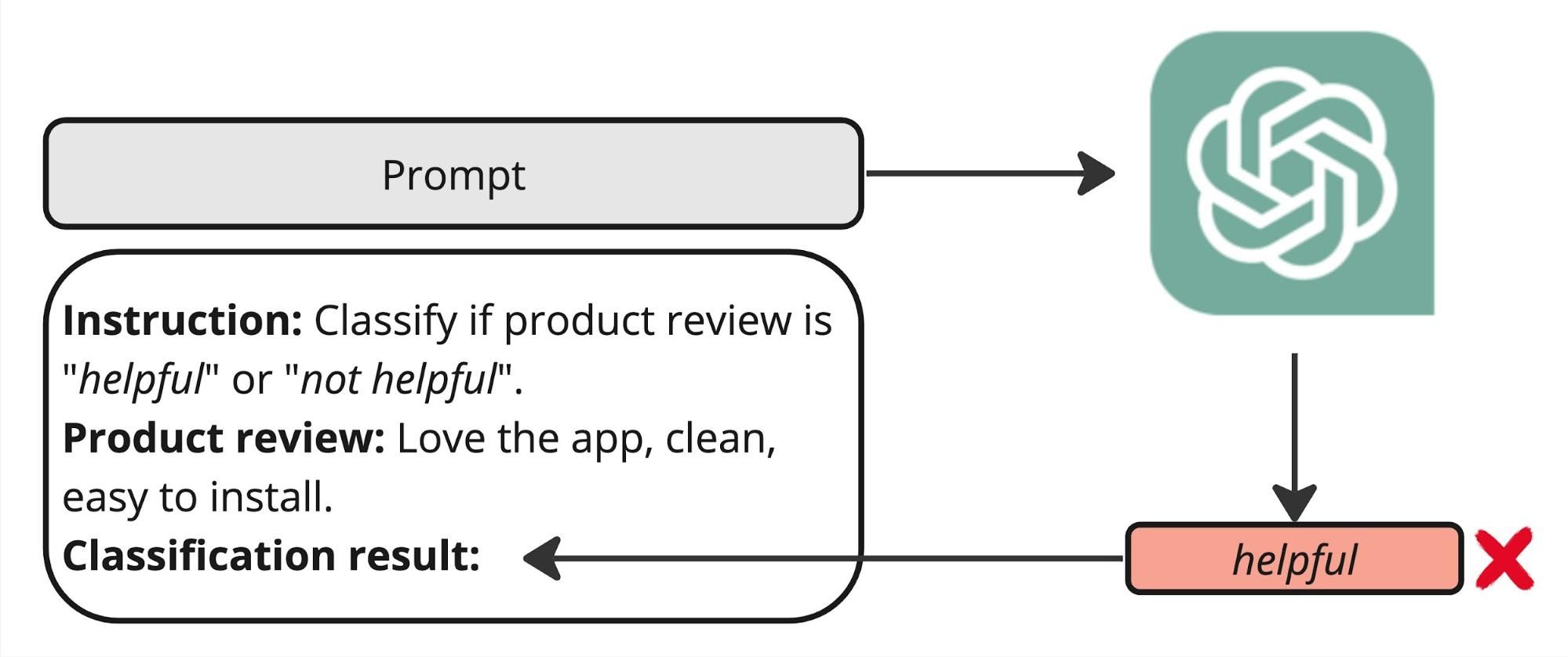
To give a concrete example, let's look at the Shopify appstore reviews dataset:
!pip install opendatasets --upgrade --quietimport opendatasets as od
dataset_url = 'https://www.kaggle.com/datasets/usernam3/shopify-app-store'
od.download(dataset_url)Please provide your Kaggle credentials to download this dataset. Learn more: http://bit.ly/kaggle-creds
Your Kaggle username:import pandas as pd
df = pd.read_csv('./shopify-app-store/reviews.csv') \
.groupby('rating') \
.apply(lambda x: x.sample(n=2000, replace=True)) \
.reset_index(drop=True)[['body', 'rating']] \
.sample(frac=1)
df.head()Getting started: Automating initial analysis with Llama 3
Our goal in this example is to ensure LLMs can automate product review analysis.
To begin, an ML or Prompt Engineer might use a simple prompt and text and run it against a model like Llama 3. However, without mechanisms to guide the generation process, the model's responses may not consistently align with predefined categories such as helpful and not_helpful class labels.
instruction = '''\
Classify the review as "helpful" or "not helpful". \
A "helpful" review should provide specific details about the user's experience, \
include clear suggestions or useful feedback, seem genuine and reflect a real user experience, \
be well-written and easy to understand, and directly pertain to the app's functionality.'''
labels = sorted(["helpful", "not helpful"])To achieve precise control over LLM outputs, we use a technique known as "constrained generation.”.This means limiting or guiding the output of the LLM according to specific rules, criteria, or constraints. To help you accomplish this, you can use tools such as the sglang library, which not only facilitates constrained generation but also offers optimized throughput.
Setting up the sglang server is straightforward. Just follow their installation steps and use a GPU-powered machine. Once installed, initiate the server with the following command:
!python -m sglang.launch_server --model-path meta-llama/Meta-Llama-3-8B-Instruct --port 30000This command launches the server that listens on port 30000, allowing inference clients to connect and begin processing.
!pip install "sglang[openai]"from sglang import RuntimeEndpoint, function, gen, set_default_backend
HOST_URL = 'http://35.184.60.123:30000'
set_default_backend(RuntimeEndpoint(HOST_URL))We need to define the inference function that gives constrained LLM responses based on a predefined set of choices:
from transformers import AutoTokenizer
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
@function
def run_sglang_gen(s, instruction, input_text, choices, temperature):
messages = [{
'role': 'user',
'content': f'Instruction:\n\n{instruction}\n\nInput text:\n"""\n{input_text}\n"""\n'
}]
prompt = tokenizer.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
s += prompt + gen(
"answer",
temperature=temperature,
choices=choices,
)tokenizer_config.json:100%|██████████|51.0k/51.0k [00:00<00:00, 1.12MB/s]
tokenizer.json:100%|██████████|9.09M/9.09M [00:00<00:00, 43.6MB/s]
special_tokens_map.json:100%|██████████|73.0/73.0 [00:00<00:00, 2.09kB/s]
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.With the sglang server now operational, we can use the Llama 3 model to automate our product review labeling task. By defining specific input instructions and a target label set, the LLM can be run across the entire dataset.
But first, to manage the memory consumption on the GPU during this process, we will adjust the batch_size parameter accordingly.
As part of our analysis, we will also collect the token probability scores, which are something that each LLM produces and are discussed more in depth below.
import numpy as np
from tqdm import tqdm
batch_size = 10
def run_on_dataset(instruction, choices, texts):
predictions = []
for i in tqdm(range(0, len(texts), batch_size), total=len(texts) // batch_size):
states = run_sglang_gen.run_batch([{
'instruction': instruction,
'input_text': t,
'choices': choices,
'temperature': 0.0
} for t in texts[i:i+batch_size]])
# collect outputs
for state in states:
meta_info = state.get_meta_info("answer")
# convert log likelihoods to probabilities
prob = np.exp(meta_info['normalized_prompt_logprob']) / np.sum(np.exp(meta_info['normalized_prompt_logprob']))
predictions.append({
'label': state['answer'],
'prob': prob
})
return pd.DataFrame(predictions)Running Llama 3 on A100 40GB GPU machine, labeling 10000 examples takes about 3.5 minutes:
df[['label', 'prob']] = run_on_dataset(
instruction=instruction,
choices=labels,
texts=df.body.tolist()
)100%|██████████| 1000/1000 [03:30<00:00, 4.75it/s]For a quick sanity check, let's display the distribution of labels created by LLM:
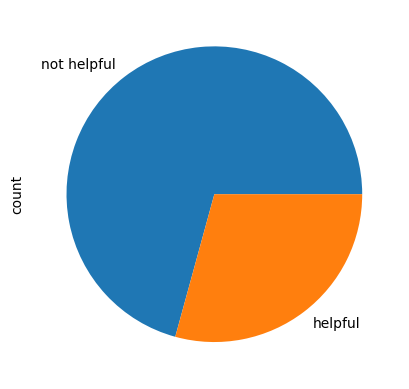
Upon reviewing the distribution of labels generated by Llama 3, we observe that the distribution appears uneven. This unevenness could potentially indicate a general bias in the model, which could affect the reliability of its outputs.
Let’s take a closer look to identify what might be causing this.
Exploring Four Techniques for Error Detection
Detecting errors is crucial for evaluating the quality of a model and guiding improvements. The simplest and most accurate method involves manually reviewing each prediction to determine its correctness.
However, this method is not scalable; manually checking thousands of examples would require significant time and resources from human annotators.
To streamline this process, we can implement automated techniques to prioritize the most likely errors for manual review. By establishing a measure of "error-likeness" or a binary indicator of error presence, we can effectively sort and prioritize cases that require human attention first.
Below are four different strategies for error detection, each with its own trade-offs in terms of cost and quality.
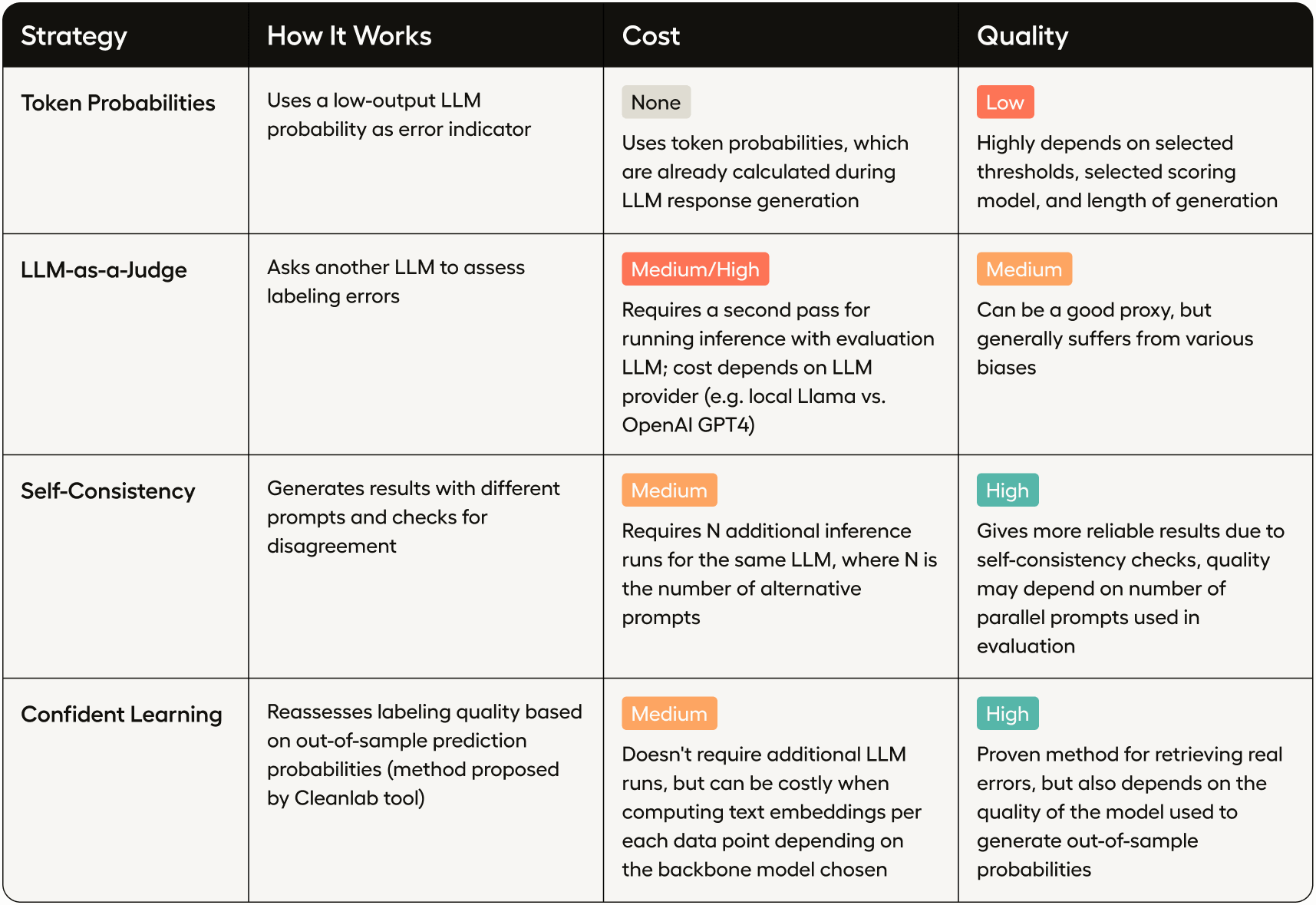
Technique #1: Analyzing Token Probabilities for Error Detection

A relatively straightforward and effective method for detecting potential errors in LLM responses is to analyze the token probability scores. These scores are assigned to each token the model generates and indicate how confident the model is that the token is correct, providing valuable insights into potential inaccuracies.
We have already collected probability scores for each rating classification. To synthesize these into a single measure of confidence, several approaches can be implemented:
- Maximum Probability: The highest probability assigned to any token in the prediction, indicating overall confidence.
- Highest Score Probability Margin: The difference between the highest and second-highest probability scores, which can reflect confidence in the context of competing classifications.
- Prediction Entropy: A measure of uncertainty across all token probabilities, with higher entropy suggesting less confidence.
Each of these techniques allows us to prioritize which responses to review based on the likelihood of error, enhancing the efficiency of manual error checking. While the probability margin and prediction entropy can provide a more nuanced picture of model confidence, for the sake of simplicity we are going to use maximum probability in our example.
df['prob'] = df.prob.apply(max)In order to identify which scores can indicate potential errors, let's first look at the score distribution:
df['prob'].plot(kind='hist', bins=50)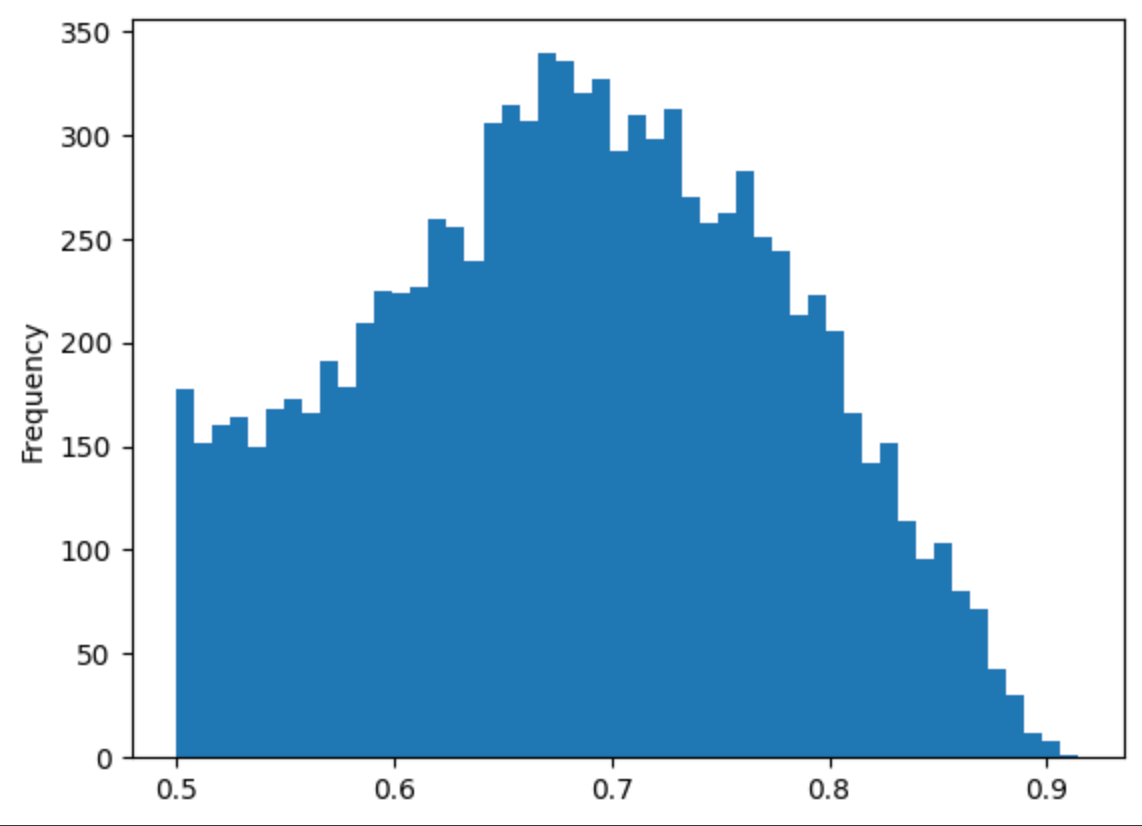
There is a suspicious peak around 0.5, which is a good candidate to explore potential errors.
df['issue_tp'] = df['prob'] < 0.51
print(f'Potential issues based on low token probability: {df["issue_tp"].sum()}')
Potential issues based on low token probability: 211Note that in more complex scenarios, it may be necessary to set individual thresholds for each predicted label, since the classification accuracy can vary between labels.
Technique #2: LLM-as-Judge
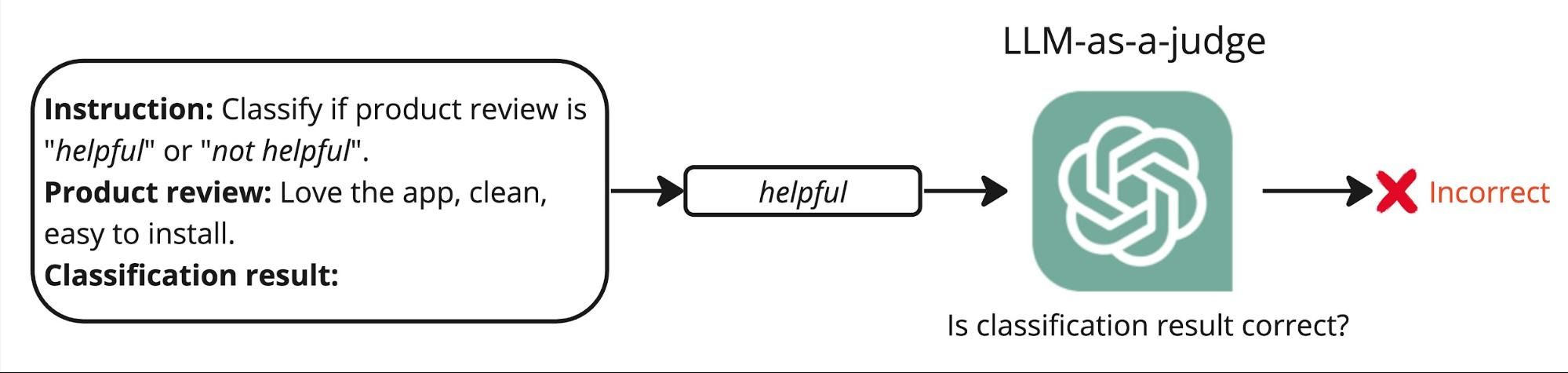
This is an innovative approach that involves using a secondary Large Language Model (LLM) to assess the labeling accuracy of the primary LLM. This method capitalizes on the capabilities of LLMs to provide meta-evaluations—essentially using one LLM to judge the performance of another. For an in-depth discussion of the foundational principles and experimental results, see the original research paper.
The process starts by crafting a specific prompt designed for the judging LLM. This prompt instructs the secondary model to assign a "Correct" or "Incorrect" label based on its evaluation of the initial label provided by the first LLM and the input text. Here's an example of how this prompt might look:
- Labeling Prompt: "Review this product description and determine if the label applied by the first LLM is accurate."
- Input Text and Response: [The actual product review text and the label assigned by the first LLM, e.g., "helpful" or "not helpful"]
- Judging Prompt Response: [The secondary LLM assesses the appropriateness of the label based on the content and context provided in the input text.]
This method provides a layer of quality control by leveraging the analytical capabilities of LLMs, enabling a more robust and scalable approach to error detection in automated labeling systems.
eval_instruction = '''Please act as an impartial judge and evaluate the response of the first language model. \
Assess if the model correctly classifies a product review based on the initial instruction as "helpful" or "not helpful". \
Check if the classification meets these criteria: specificity of user experience details, clarity and usefulness of feedback, \
authenticity and relevance to the app's functionality, and overall clarity and comprehension of the text. \
Label the response "Correct" if it fully meets all criteria, and "Incorrect" if it does not meet one or more of these criteria.'''@function
def run_llm_eval(s, input_text, predicted_label):
messages = [{
'role': 'user',
'content': (
f'{eval_instruction}\n\n'
f'Initial instruction:\n"""\n{instruction}\n"""\n\n'
f'Product review:\n"""\n{input_text}\n"""\n\n'
f'Classification result: {predicted_label}\n\n'
'Evaluation result: '
)
}]
prompt = tokenizer.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
s += prompt + gen(
"answer",
temperature=0,
choices=['Correct', 'Incorrect'],
)
def run_eval_on_dataset(texts, labels):
predictions = []
texts_and_labels = list(zip(texts, labels))
for i in tqdm(range(0, len(texts_and_labels), batch_size), total=len(texts) // batch_size):
states = run_llm_eval.run_batch([{
'input_text': t,
'predicted_label': l,
} for t, l in texts_and_labels[i:i+batch_size]])
for state in states:
# Identify errors
predictions.append(True if state['answer'] == 'Incorrect' else False)
return pd.DataFrame(predictions)
df['issue_lj'] = run_eval_on_dataset(df.body.tolist(), df.label.tolist())
print(f'Potential issues identified by cleanlab: {df["issue_lj"].sum()}')100%|██████████| 1000/1000 [04:02<00:00, 4.12it/s]
It's worth noting that using an enterprise-grade LLM, such as OpenAI GPT-4, can lead to better quality evaluation results compared to using the same Llama 3 model, which may be suboptimal.
Technique #3: Self-Consistency
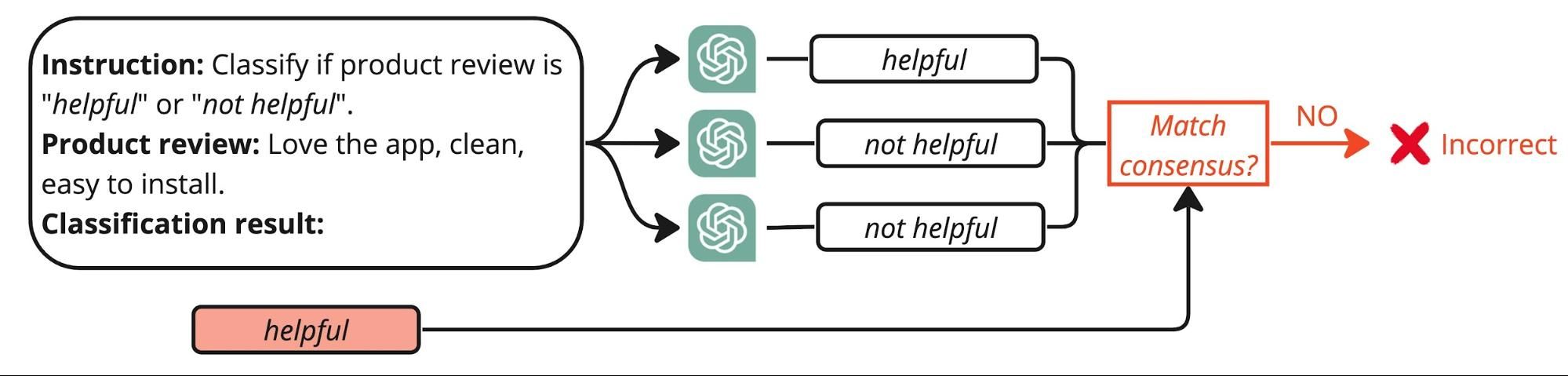
The self-consistency technique executes multiple runs of the same LLM using subtly different, paraphrased versions of the original prompt. The goal is to observe how consistently the model produces the same label across these variations, which can indicate the reliability of its predictions.
The process looks like this:
- Paraphrase the Prompt: Begin by creating several paraphrased versions of the original labeling prompt. These variations should maintain the core intent of the original but alter the phrasing or structure to test the model's robustness.
- Run Multiple Inferences: Input each paraphrased prompt into the LLM and collect the labels it assigns. This step is crucial as it tests the model's consistency under slightly varied input conditions.
- Compute Consensus: Analyze the range of labels generated from the different prompts. A high level of agreement among the outcomes suggests a high confidence in the model’s accuracy. Conversely, significant variation may indicate areas where the model struggles to make consistent judgments, signaling potential inaccuracies.
Advantages of Self-Consistency:
- Increased Reliability: By confirming that the model produces consistent results under varied inputs, we can increase our trust in its predictive capabilities.
- Error Detection: Areas where the model shows inconsistency are flagged for further review, helping to pinpoint where errors are more likely to occur.
- Model Tuning: Insights from self-consistency checks can guide further refinement of the model, improving its overall performance and reliability.
# prepare the list of alternative instructions
instructions = [
"Classify the review as \"helpful\" or \"not helpful\". A \"helpful\" review should offer specific details about the user's experience, contain clear suggestions or valuable feedback, appear genuine and reflect an authentic user experience, be well-composed and easy to comprehend, and directly relate to the app's functionality.",
"Classify the review as \"helpful\" or \"not helpful\". A \"helpful\" review should present specific details about the user's experience, provide clear suggestions or beneficial feedback, seem authentic and mirror a real user experience, be well-crafted and straightforward to understand, and directly connect to the app's functionality.",
"Classify the review as \"helpful\" or \"not helpful\". A \"helpful\" review should deliver specific details about the user's experience, include precise suggestions or advantageous feedback, appear genuine and reflect a true user experience, be well-written and simple to comprehend, and directly relate to the app's features."
]
# run each instruction through the same LLM
for i, instruction in enumerate(instructions):
print(f'Running on instruction: "{instruction}"')
df[[f'label_{i}', f'prob_{i}']] = run_on_dataset(
instruction=instruction,
choices=labels,
texts=df.body.tolist()
)Running on instruction: "Classify the review as "helpful" or "not helpful". A "helpful" review should offer specific details about the user's experience, contain clear suggestions or valuable feedback, appear genuine and reflect an authentic user experience, be well-composed and easy to comprehend, and directly relate to the app's functionality."
100%|██████████| 1000/1000 [03:17<00:00, 5.07it/s]
Running on instruction: "Classify the review as "helpful" or "not helpful". A "helpful" review should present specific details about the user's experience, provide clear suggestions or beneficial feedback, seem authentic and mirror a real user experience, be well-crafted and straightforward to understand, and directly connect to the app's functionality."
100%|██████████| 1000/1000 [03:19<00:00, 5.02it/s]
Running on instruction: "Classify the review as "helpful" or "not helpful". A "helpful" review should deliver specific details about the user's experience, include precise suggestions or advantageous feedback, appear genuine and reflect a true user experience, be well-written and simple to comprehend, and directly relate to the app's features."
100%|██████████| 1000/1000 [03:22<00:00, 4.94it/s]We can infer various helpful statistics to reveal potential mislabelings. For example, the correlation matrix gives a sense of how frequently different labels co-occur within the dataset.
import seaborn as sns
import matplotlib.pyplot as plt
from collections import Counter
label_cols = [col for col in df.columns if col.startswith('label')]
label_to_num = {label: i for i, label in enumerate(sorted(labels))}
df['agreement'] = df[label_cols].apply(lambda x: max(Counter(x).values()) / len(x), axis=1)
corr = df[label_cols].replace(label_to_num).corr()
sns.heatmap(corr, annot=True, fmt=".2f", cmap='coolwarm')
plt.title('Label Correlation Heatmap')
plt.show()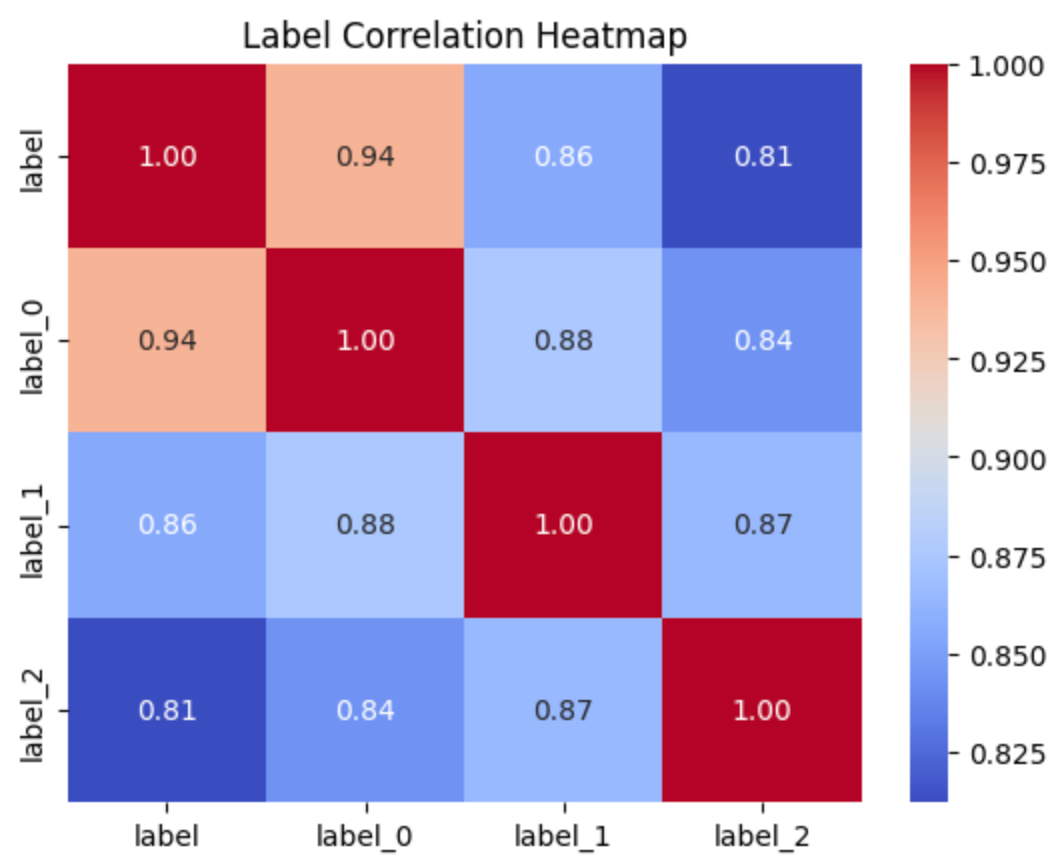
It is not surprising that when instructions deviate significantly from each other, there is less correlation in the final results, indicating that the model is not self-consistent. We can conclude that the errors are more likely to occur when initial labels do not match the majority vote:
from collections import Counter
df['issue_sc'] = df[label_cols].apply(lambda x: Counter(x).most_common(1)[0][0] != x['label'], axis=1)
print(f'Potential issues based on self consistency: {df["issue_sc"].sum()}')Potential issues based on self consistency: 157You can play around with this approach to suit your needs. For example, you can increase the number of alternative prompts to test and check for examples where labeling LLM disagrees with 100% majority votes of alternative LLM responses.
Technique #4: Confident Learning with Cleanlab
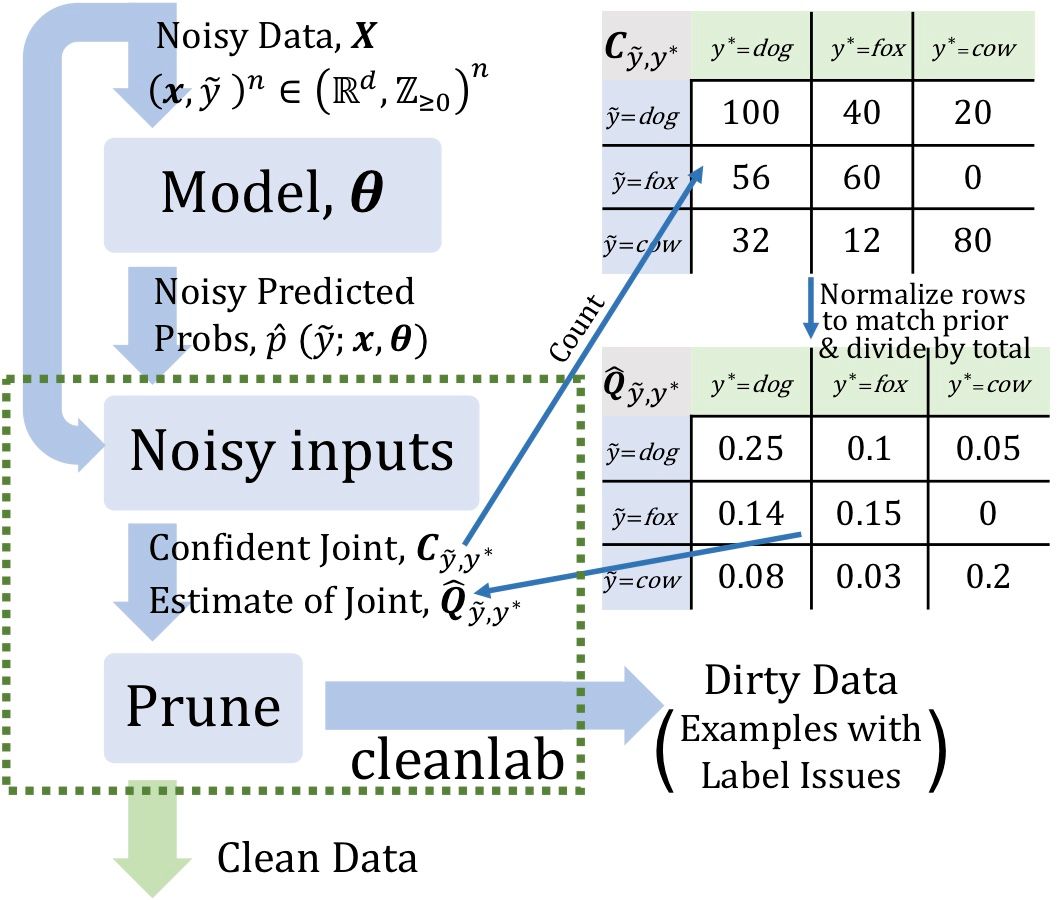
Image by Confident learning post
Another way to detect errors in LLM-based labelings is to use the Confident Learning technique provided by the open-source Cleanlab tool. The idea is to build an auxiliary classification model that provides out-of-sample probabilities for each data point. These probabilities are then used to find inconsistencies in LLM responses that suggest possible labeling errors. For more details, see Northcutt C., Jiang L., Chuang I., 2022
First we’ll collect embeddings per each product review:
import os
from openai import OpenAI
from google.colab import userdata
os.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')
client = OpenAI()
def get_embeddings(texts, model="text-embedding-3-small"):
inputs = [str(text).replace("\n", " ") for text in texts]
return [i.embedding for i in client.embeddings.create(input=inputs, model=model).data]
embs = []
for i in tqdm(range(0, len(df), 100)):
embs.extend(get_embeddings(df.body.iloc[i:i + 100]))
embs = np.array(embs)
embs.shape100%|██████████| 100/100 [01:15<00:00, 1.32it/s]
(10000, 1536)Then using these embeddings, fit a logistic regression model on the embeddings and labels in the original data using 10-fold cross-validation
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_predict
model = LogisticRegression(max_iter=1000)
labels_num = np.array([label_to_num[label] for label in df.label])
pred_probs = cross_val_predict(estimator=model, X=embs, y=labels_num, cv=10, method="predict_proba")Obtaining out-of-sample probabilities per each example in pred_probs allows us to find potential label issues with Cleanlab:
!pip install cleanlabfrom cleanlab.filter import find_label_issues
issue_idx = find_label_issues(labels_num, pred_probs, return_indices_ranked_by='self_confidence')
df['issue_cl'] = False
df.loc[issue_idx, 'issue_cl'] = True
print(f'Potential issues identified by cleanlab: {df["issue_cl"].sum()}')Potential issues identified by cleanlab: 1556Error analysis and LLM evaluation
Now that we’ve tried each error detection technique, let's save our dataframe for further analysis:
cols_to_save = label_cols + ['body', 'issue_tp', 'issue_sc', 'issue_cl', 'issue_lj', 'prob', 'agreement']
df[cols_to_save].to_csv('finding_errors_in_llm_responses.csv', index=False) The finding_errors_in_llm_responses.csv file is now ready to be integrated into a more interactive error analysis tool. For this purpose, we’ll use Label Studio, a flexible tool for data labeling tasks:
1. Install Label Studio: First, install Label Studio on your machine and then launch it using the following commands:
# Install the package
$ pip install -U label-studio
# Launch Label Studio
$ label-studio 2. Import Data: Once Label Studio is running, open it in your browser (default at http://localhost:8080). Create a new project and import the finding_errors_in_llm_responses.csv file using the drag-and-drop interface in the import dialog.
3. Explore the Data: Label Studio provides a data viewer that includes search and filtering capabilities, which facilitate the review of the dataset and the errors detected.
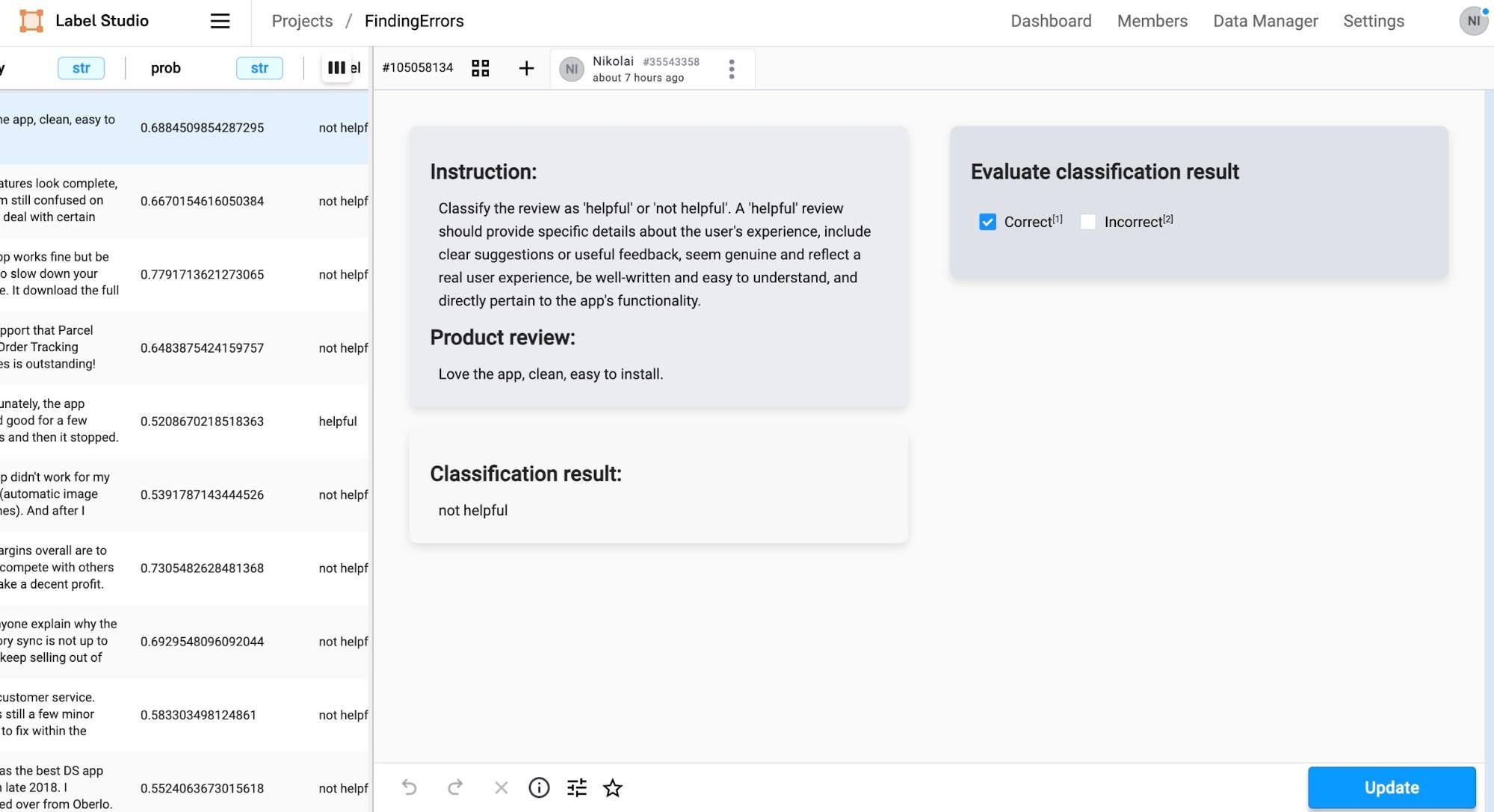
The next phase in our evaluation involves the critical human supervision component. The primary goal here is not to construct an exhaustive benchmark, but rather to efficiently sample and scrutinize potential errors identified by our methods. This targeted approach allows us to directly address areas of ambiguity or concern in the model's performance, enhancing the overall efficiency of the review process:
- Evaluating false positives refers to evaluating how often the method suggests a labeling error when it was not actually made. Reducing such errors makes the human review process more efficient
- Evaluating false negatives refers to the frequency in which a labeling error is missed by the method. Improving this increases the reliability of the chosen method.
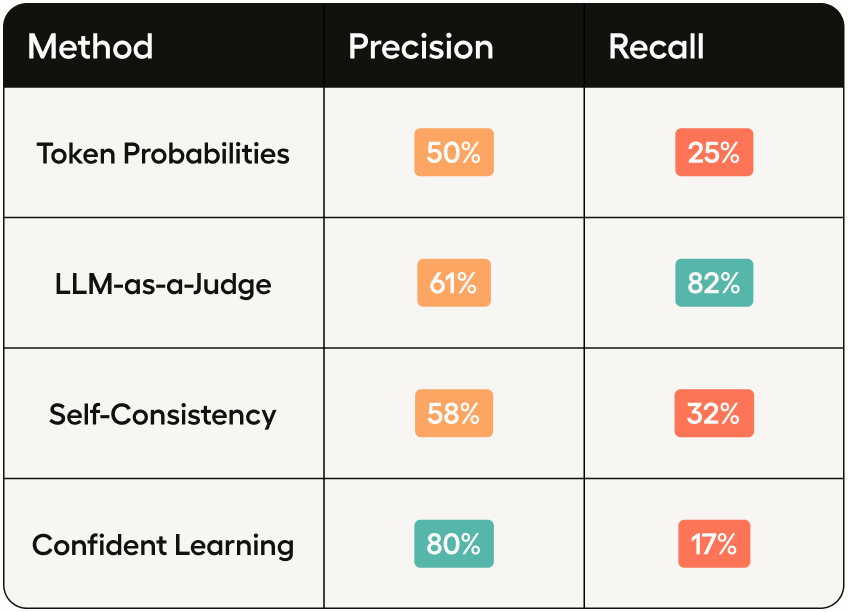
After manually checking 80 examples of each type of possible errors, we can produce comparison results across different metrics using precision and recall numbers.
Conclusion
The effectiveness of various error identification methods can be evaluated using the scores derived from our analyses. However, it's important to note that these scores, particularly the first three, are influenced by the underlying model used, in this case, Llama 3 7B. While this model is robust, it is not the most powerful LLM available, which can affect the overall performance of the error detection methods.
Among the techniques we examined, the confident learning approach, facilitated by cleanlab, showed the most promising results when precision should be maximized. This method excels by providing out-of-sample probability estimates, which are crucial for identifying mislabelings more accurately. Despite its reliance on the underlying model's capabilities, which can sometimes be suboptimal as demonstrated in this tutorial, it still marks a significant improvement by reducing the manual labor typically required in evaluating each LLM response and prompt. LLM-as-a-judge, an automated evaluator, performs better when handling high recall requirements. This can be attributed to its capability to accurately understand evaluation instructions, which are also utilized to gather ground truth data. However, it's important to note that this evaluation experiment only provides a superficial qualitative analysis due to the absence of testing data and an artificially designed task without subject matter expertise. Further experiments are needed to validate these findings.
Related Content
-

The 5 Metrics That Actually Move AI Into Production
A practical framework for turning AI metrics into clearer decisions about what to fix, ship, and scale.

Sheree Zhang
April 15, 2026
-

Scaling AI Data Quality: Best Practices for Onboarding and Evaluating Annotators
A practical workflow for onboarding and evaluating annotators with clear instructions, calibration, quality gates, reviewer feedback, and dashboards that keep labeling consistent as volume grows.

Alec Harris
March 12, 2026
-

How to Create a Prompt Generator with Label Studio and RLVR
In this article, you'll learn how to apply an RLVR-based score verifier and use an LLM as a prompt optimizer to enhance your prompts.

Label Studio Team
March 2, 2026