Label Studio Release Notes 0.7.0 - Cloud Storage Enablement

Just a couple of weeks after our 0.6.0 release, we’re happy to announce a new big release. We’ve started the discussion about the cloud months ago, and as the first step in simplifying the integration, we’re happy to introduce cloud storage connectors, like AWS S3.
We’re also very interested to learn more from you about your ML pipelines, if you’re interested in having a conversation, please ping us on Slack.

Connecting cloud storage
You can configure label studio to synchronize labeling tasks with your s3 or gcp bucket, potentially filtering by a specific prefix or a file extension. Label Studio will take that list and generate pre-signed URLs each time the task is shown to the annotator.
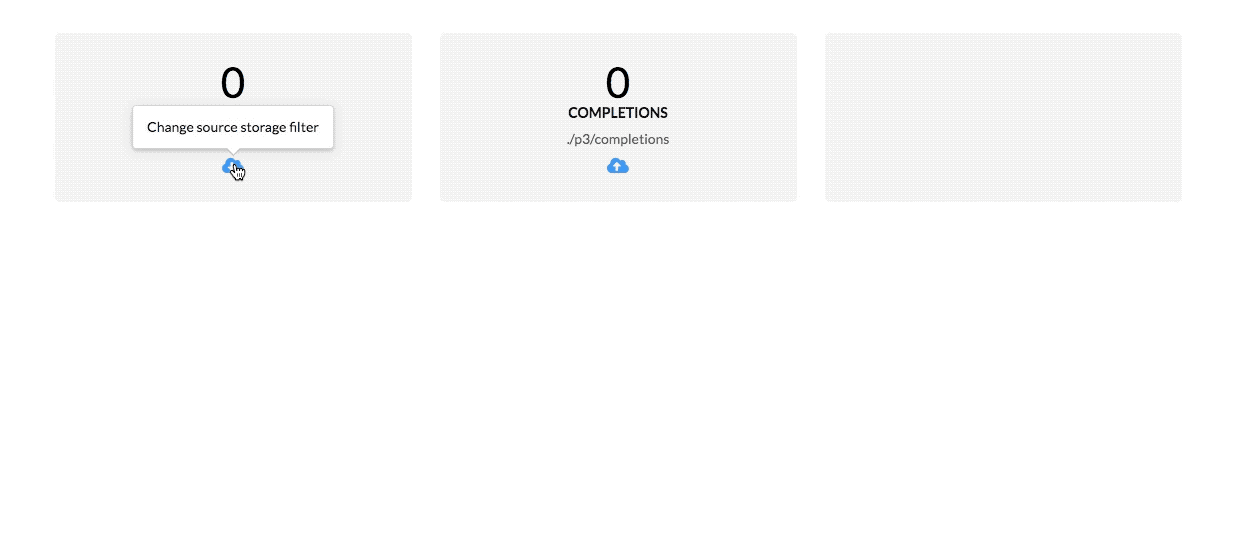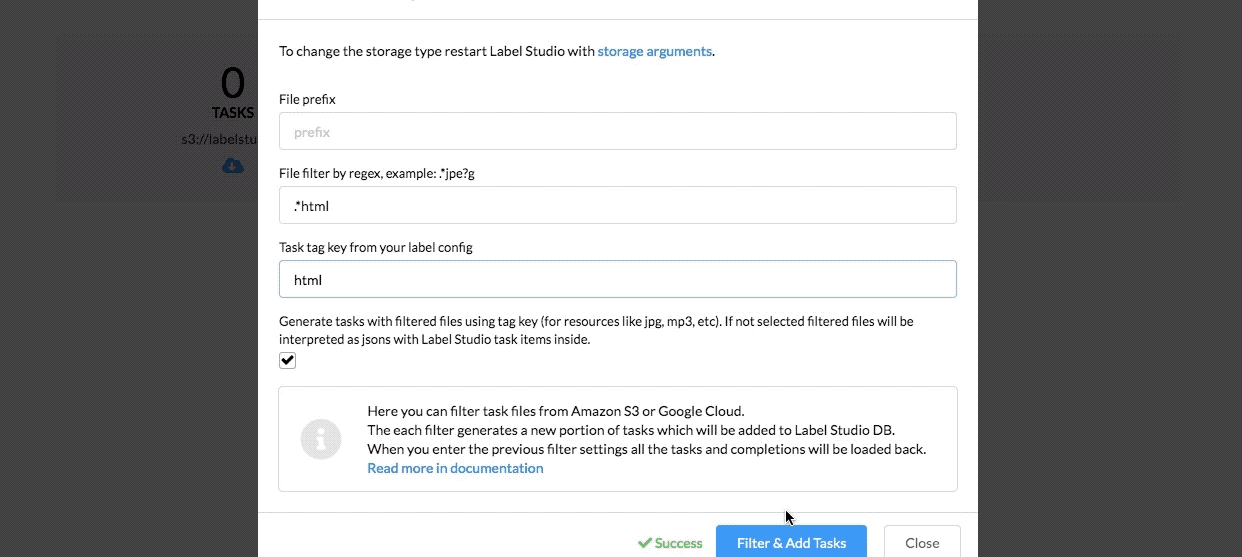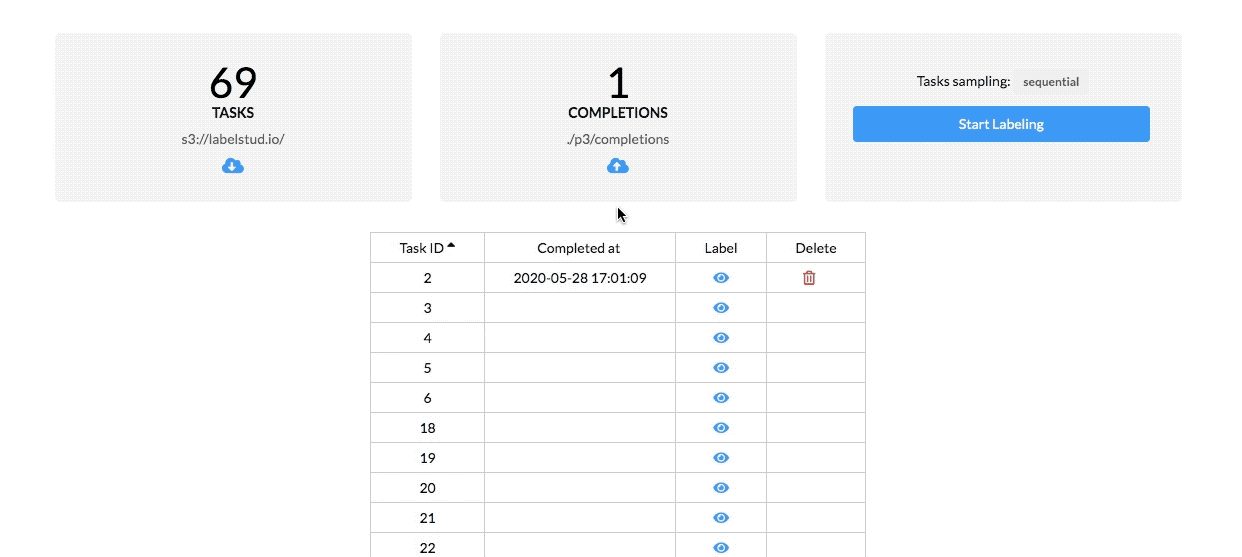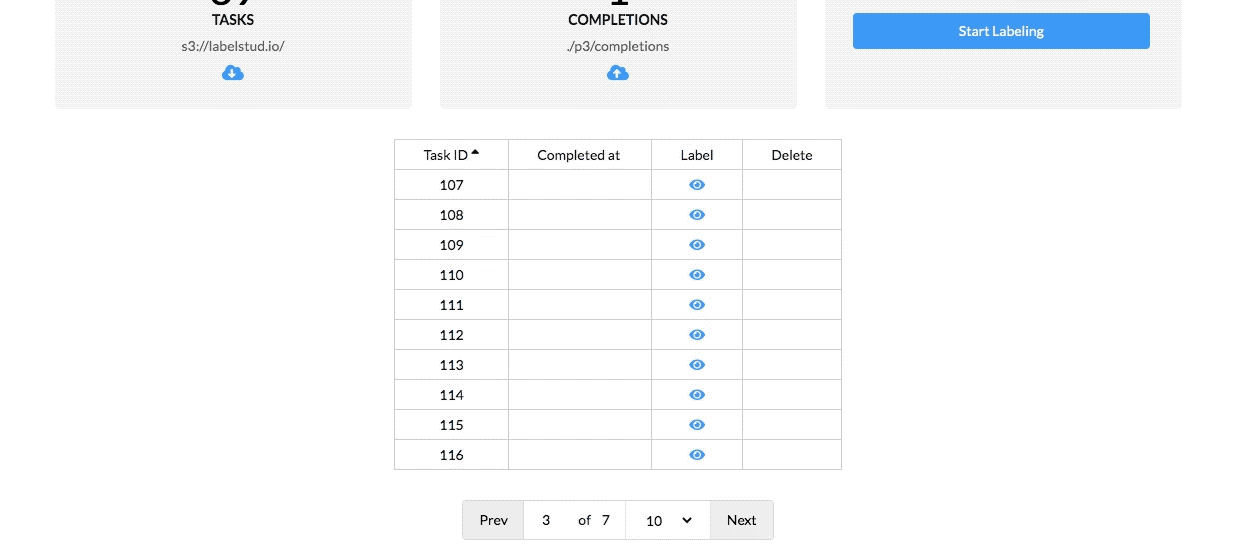
There are several ways how label studio can load the file, either as a URL or as a blob therefore, you can store the list of tasks or the assets themselves and load that.
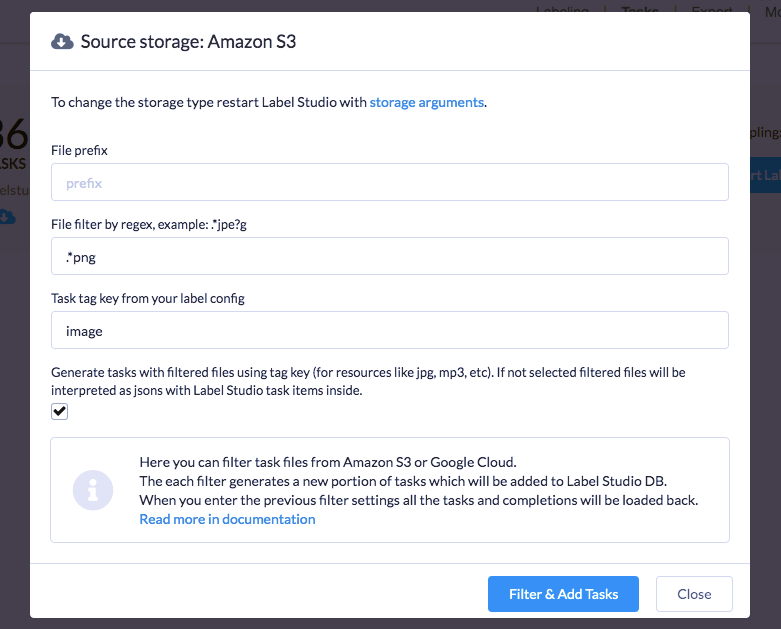
You can configure it to store the results back to s3/gcp, making Label Studio a part of your data processing pipeline. Read more about the configuration in the docs here.
Frontend package updates
Finally with a lot of work from Andrew there is an implementation of frontend testing. This will make sure that we don’t break things when we introduce new features. Along with that another Important part — improved building and publishing process, configured CI. Now the npm frontend package will be published along with the pip package.
Labeling Paragraphs and Dialogs
Introducing a new object tag called “Paragraphs”. A paragraph is a piece of text with potentially additional metadata like the author and the timestamp. With this tag we’re also experimenting now with an idea of providing predefined layouts. For example to label the dialogue you can use the following config: <Paragraphs name=“conversation” value=“$conv” layout=“dialogue” />
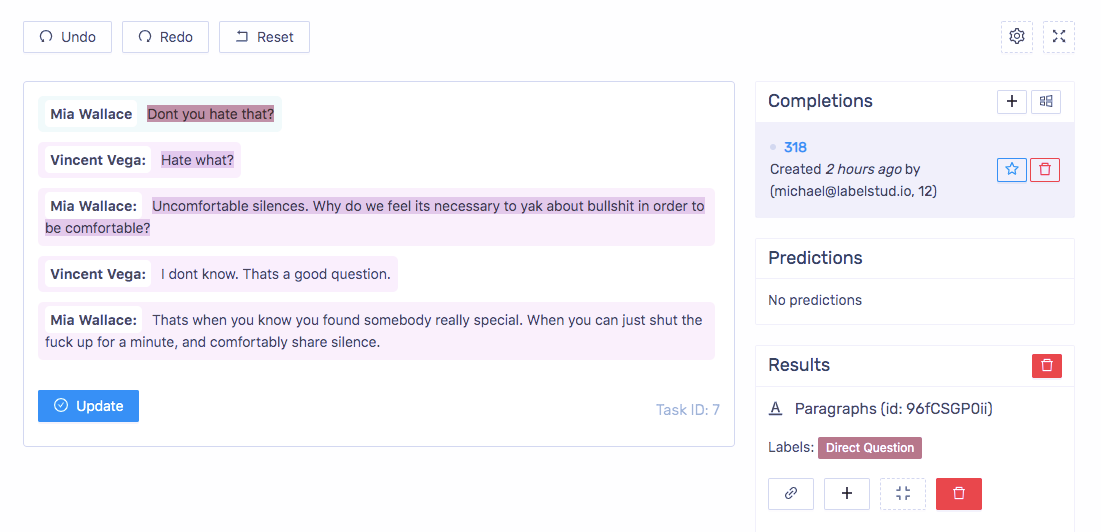
This feature is available in the enterprise version only
Different shapes on the same image
One limitation label studio had was the ability to use only one shape on the same image, for example, you were able to put either bounding boxes or polygons. Now this limitation is waived and you can define different label groups and connect those to the same image.
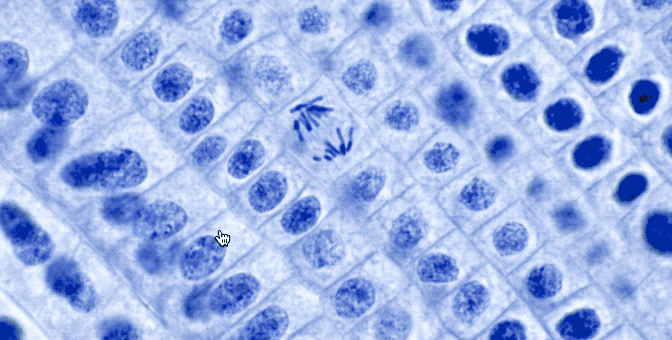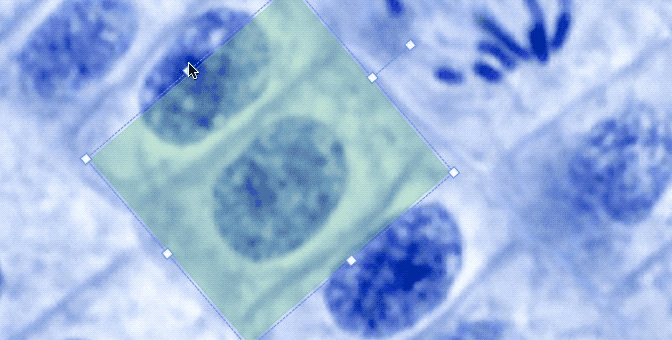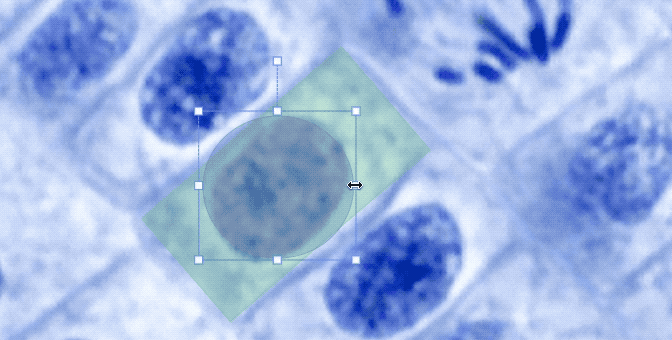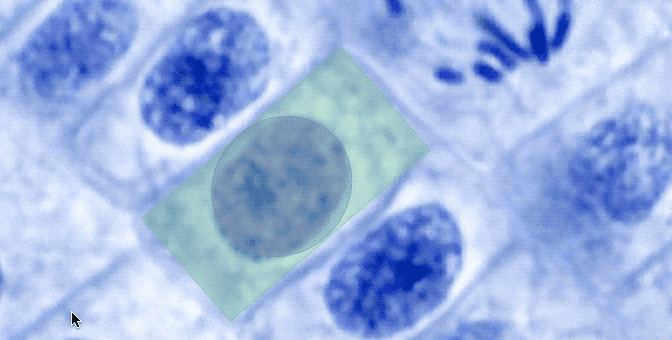
maxUsages
There are a couple of ways how you can make sure that the annotation is being performed in full. One of these concepts is a required flag, and we’ve created a new one called maxUsages. For some datasets you know how much objects of a particular type there is, therefore you can limit the usage of specific labels.
Bugfixes and Enhancements
- Allow different types of shapes to be used in the same image. For example you can label the same image using both rectangles and ellipses.
- Fixing double text deserialization https://github.com/heartexlabs/label-studio-frontend/pull/85
- Fix bug with groups of required choices https://github.com/heartexlabs/label-studio-frontend/pull/74
- Several fixes for NER labeling — empty captured text, double clicks, labels appearance
Related Content
-
Label Studio 1.23: Vector Annotation, Interactive Task Source, and Data Manager Improvements
Vector annotation, an interactive task source viewer, and workflow improvements across the Data Manager and Template Builder.

Label Studio Team
March 13, 2026
-

Label Studio 1.21.0: Pixel Perfect Annotation, Custom Hotkeys, and Smarter Audio/Video Tools
Label Studio 1.21 delivers pixel-perfect annotation, custom hotkeys, and smarter audio/video tools to help teams work faster and with greater accuracy.
Label Studio Team
September 30, 2025
-
Label Studio 1.20.0: Spectrograms, Time Series Sync, Playground 2.0, and JSONL Support
Label Studio 1.20.0 introduces major upgrades for audio, video, and time series labeling, including spectrogram support, stream synchronization, and easier data imports.
Label Studio Team
July 1, 2025