Announcing Label Studio v1.0

Hooray! The day is finally here. After almost a year and a half of development, 1000+ commits, 40 releases, and 50+ developers contributing minor and major parts, we’re happy to announce a big milestone – Label Studio v1.0!
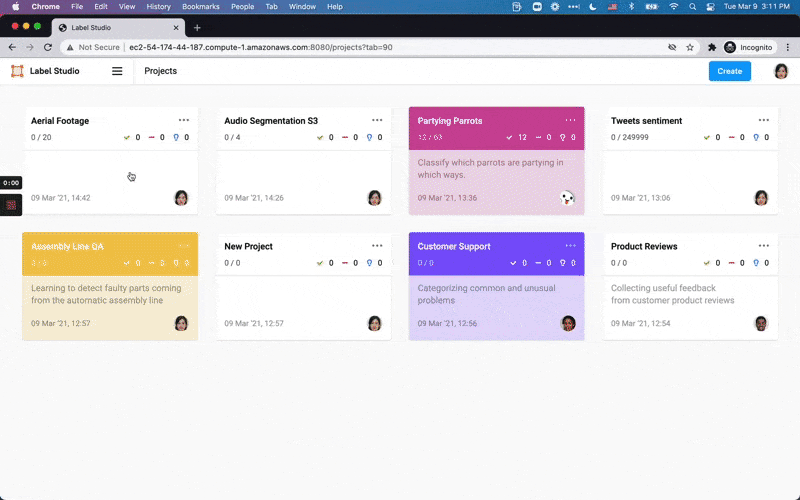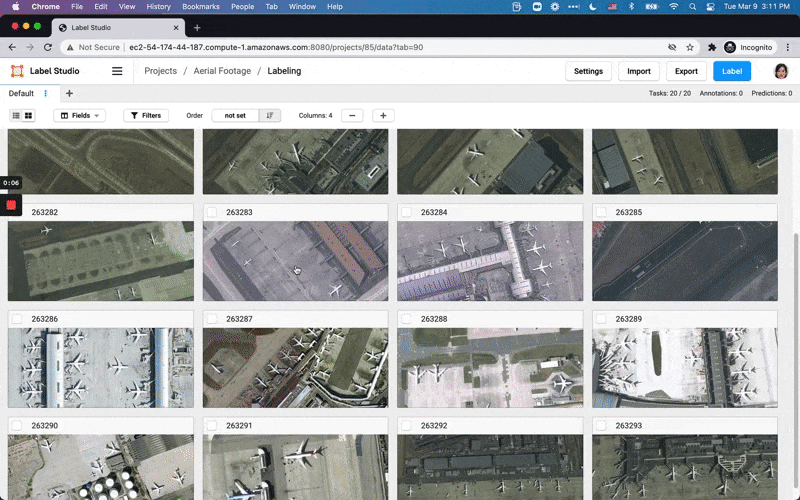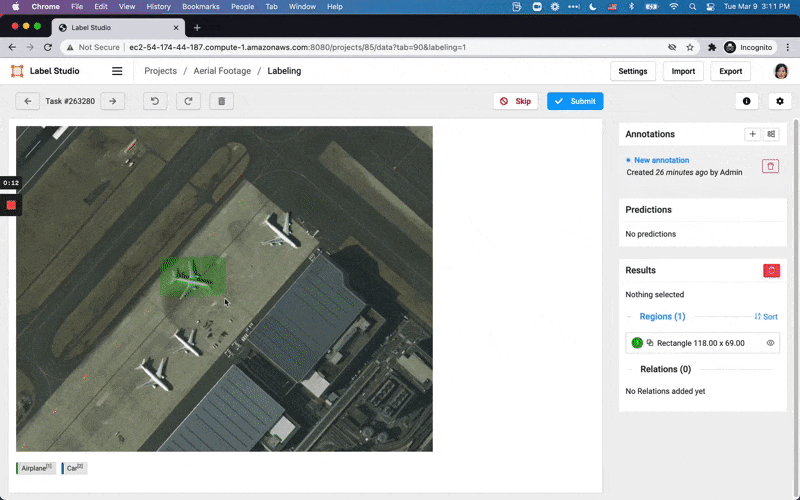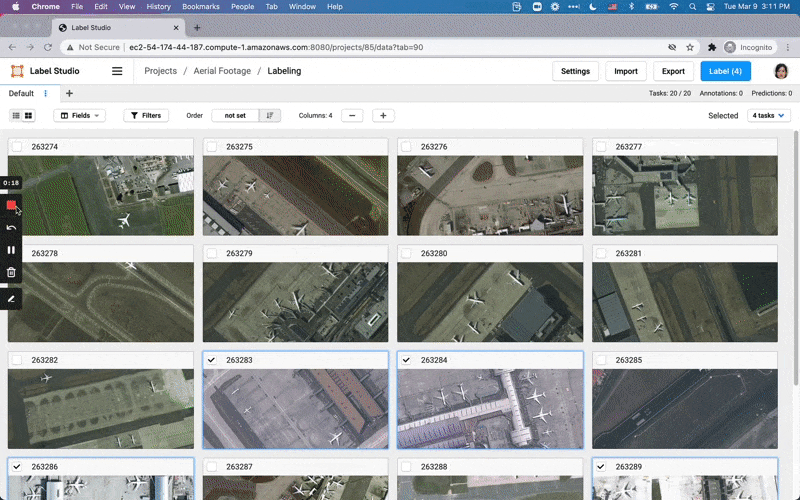
We’ve rebuilt Label Studio from the ground up, thanks to a lot of feedback over the last year. Say hello to a multi-user, multi-project system. Plus it’s scalable!
Why use Label Studio?
Label Studio is an open source data labeling tool. It’s the most robust and easiest to use solution for labeling a raw dataset or a previously labeled dataset that you want to improve. If you work on computer vision, NLP, conversational AI, audio/speech processing, and time-series projects, you can get up and running in minutes. Improving training data with Label Studio becomes a more transparent and easily-managed process.

Various data types you can label using Label Studio
Label Studio also natively integrates with ML models. You can connect your models and keep updating them with new labeled data, as well as perform quality assurance on model predictions.
What’s new with 1.0
For the last four months, the Label Studio team has been on a nonstop journey of rethinking interfaces, the annotation flow, and the robustness of the overall system.

Here is how this effort looks in terms of development time
As a result, we’ve re-engineered almost everything! Data labeling is heavily dependent on the simplicity and ease-of-use of the user interface, so we streamlined and updated the entire Label Studio UI. In addition to the UI improvements, we have also improved the speed and performance of working with large datasets. Now you can work efficiently with datasets containing millions of items. Let’s dive into the details!
Data labeling by multiple users
One of the biggest changes we’ve introduced in this version is the addition of user accounts. Now, multiple users can create accounts in the same Label Studio instance. User's can work off of the same datasets and each user's annotations are tied to their account.
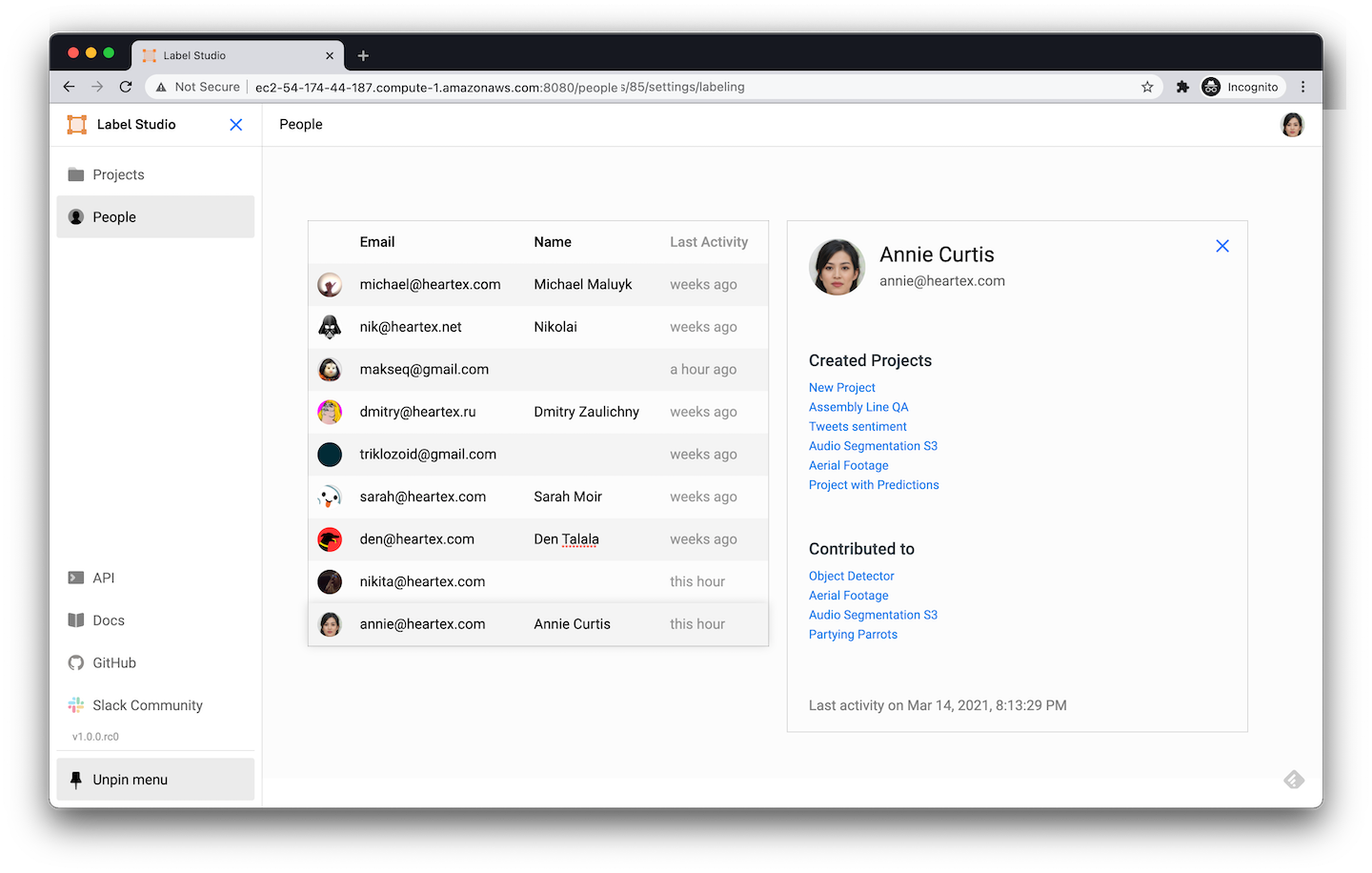
People page is showing the list of users
Multiple projects to handle all your datasets in one place
Label Studio Projects enable you to create and save labeling configurations for different datasets or projects. Label Studio Projects streamline managing and working on different datasets, can be shared with other users, and can be reused for similar projects in the future.
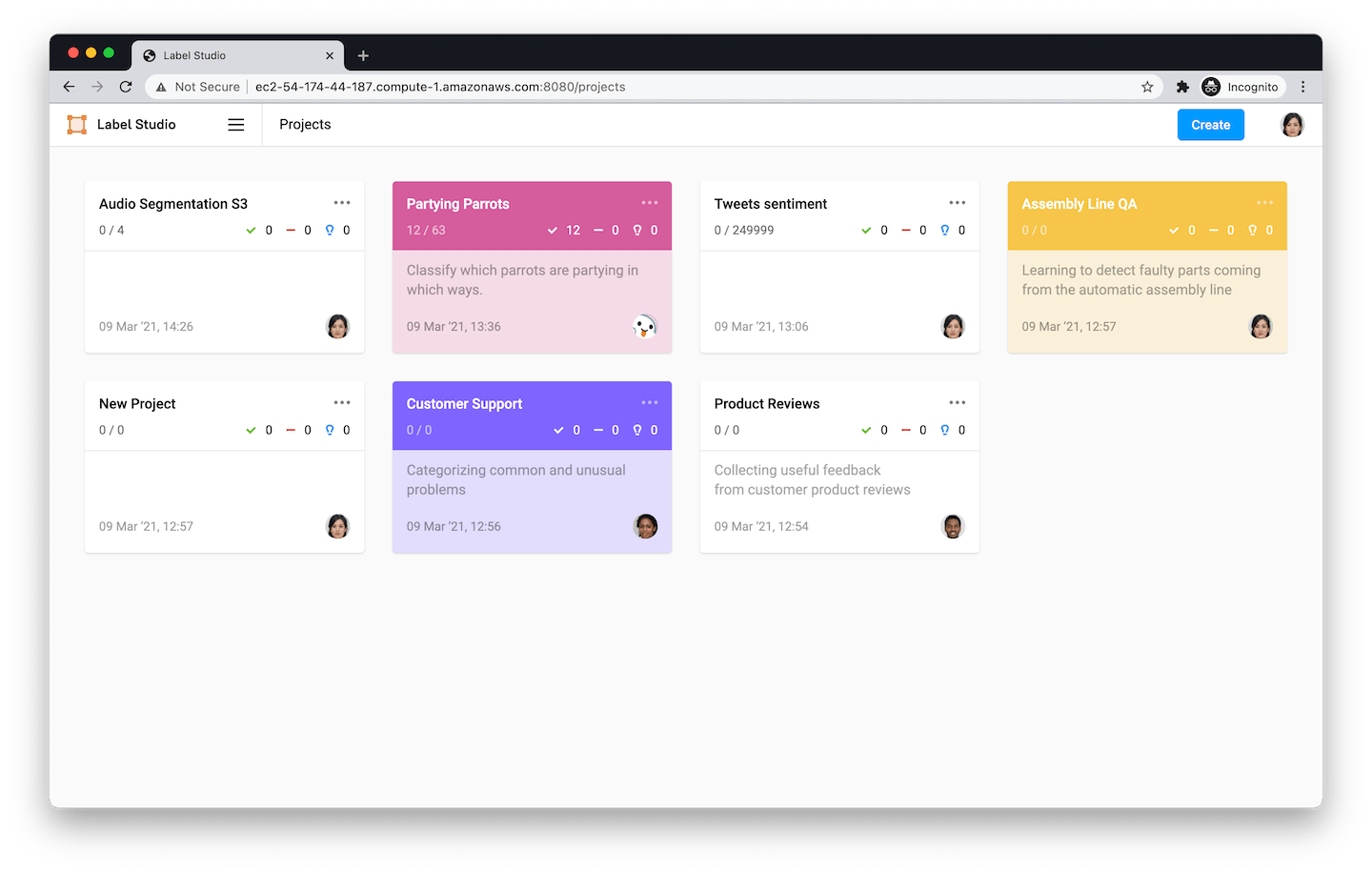
We also restructured the project settings and made it easier to configure the labeling interface for each project. A few updates worth mentioning:
Model Assisted Labeling
ML models can help pre-label data and optimize the data labeling process. For example, connect a segmentation model like Mask RCNN to give its prediction, then you can adjust the prediction to make it perfect. Another example is if you connect an ASR model to provide speech transcription for further labeling.
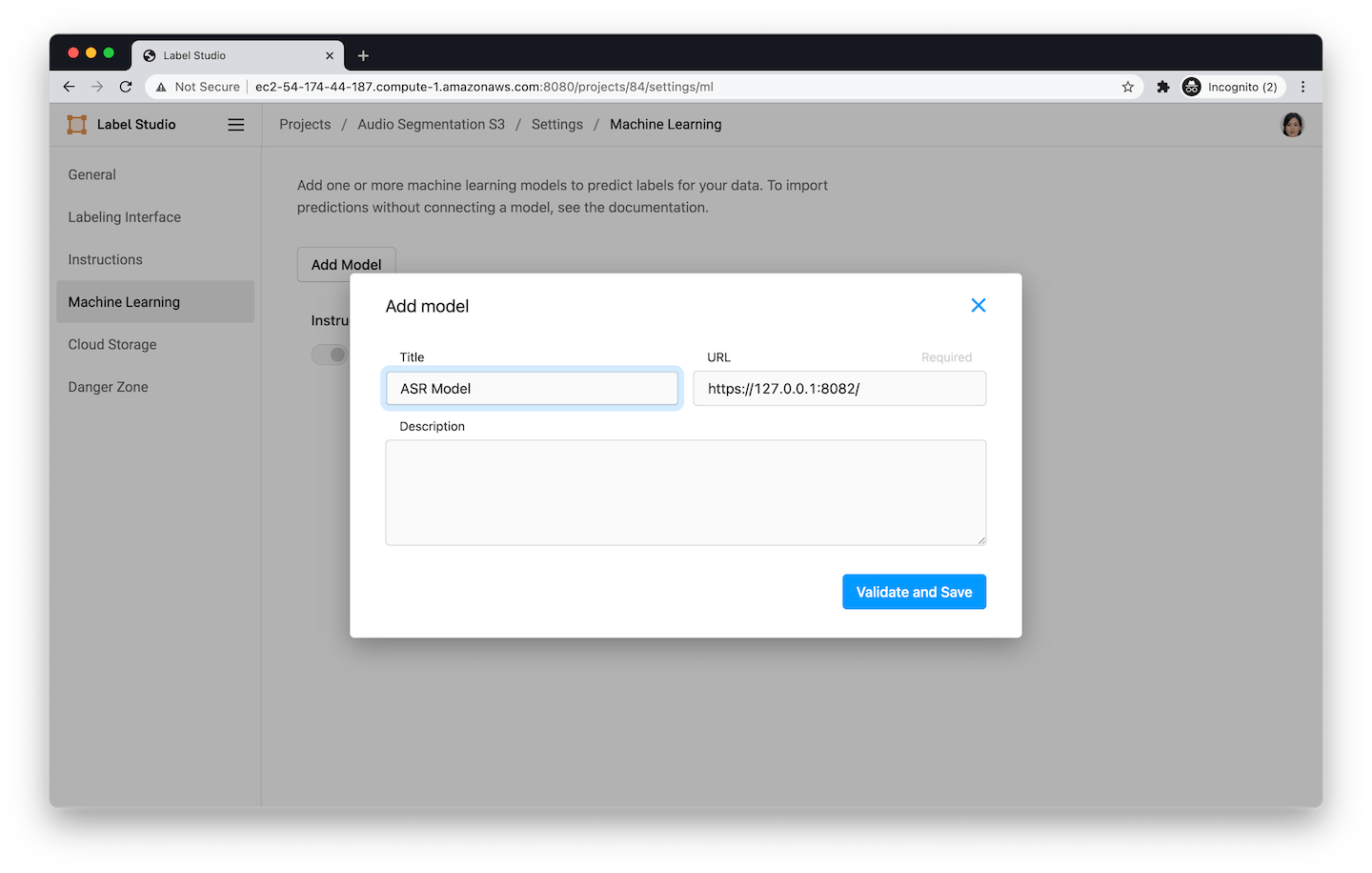
Adding machine learning model for assisted labeling
Read data from cloud storage
If you store your data in the cloud, Label Studio can natively sync with it. Out of the box you can configure Label Studio to read data from AWS S3, GCP, or Microsoft Azure. You can sync from multiple cloud providers or buckets at the same time, and each project can connect to a different cloud storage location.
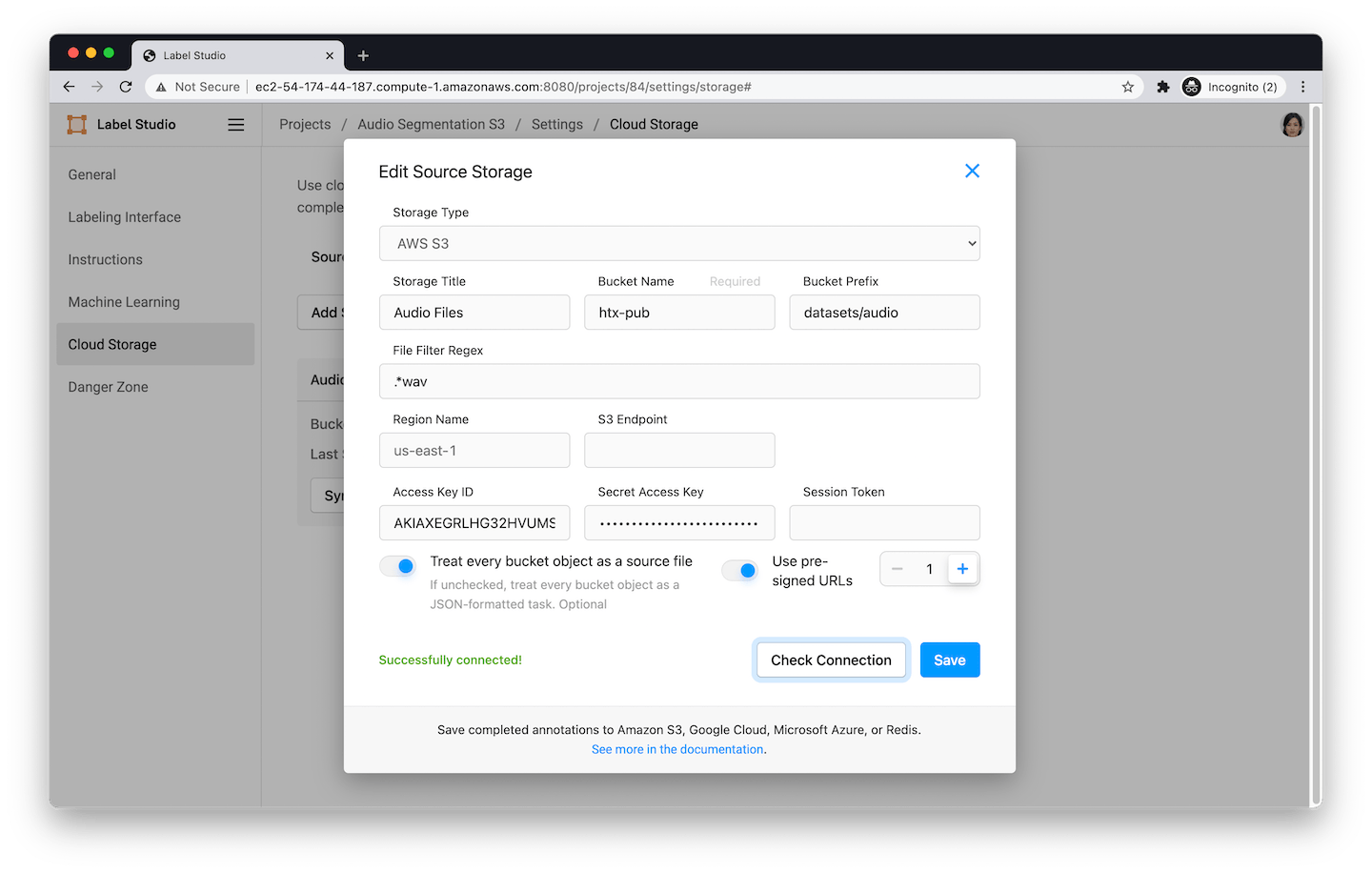
Configuration to read audio files stored in an S3 bucket
Interface configuration wizard
You can start labeling quickly by using a template to configure the labeling interface for your project, or enjoy a greater level of flexibility with custom tags.
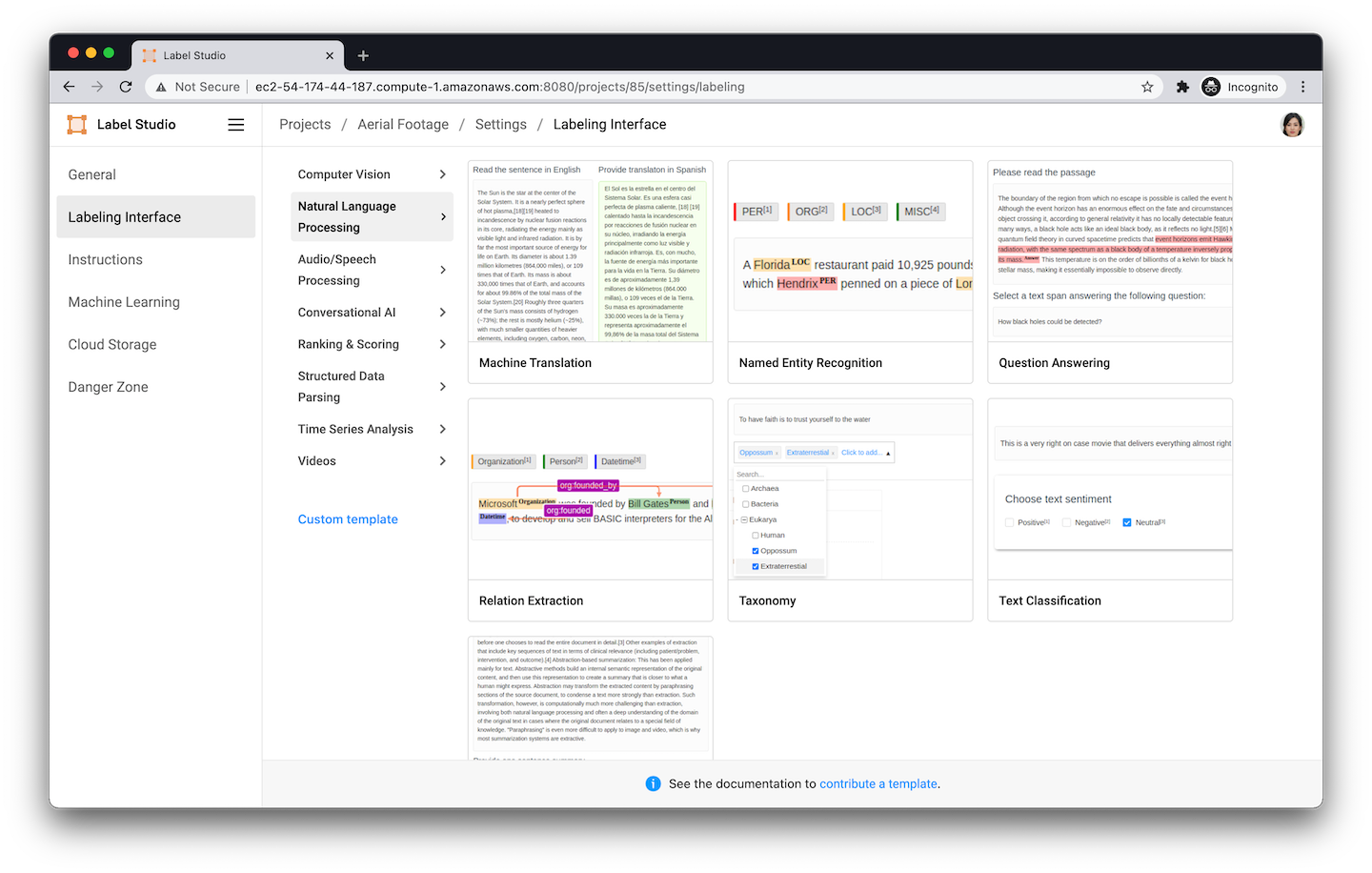
Dozens of the most common data labeling scenarios have templates
Label large datasets with new scalable data labeling backend
We migrated to a more robust backend from our enterprise version based on Django. We also transitioned from a filesystem-based to SQL-based data storage for tasks and annotations. While a filesystem is probably the simplest approach for storage, it doesn’t scale well when you work on datasets with more than 10,000 items. With SQLite as a storage backend, we can now easily upload datasets of hundreds of thousands of items.
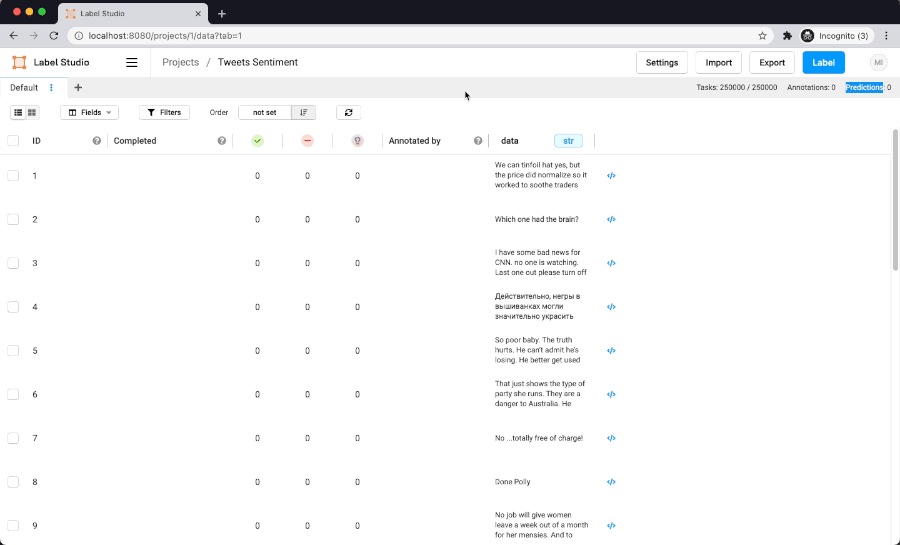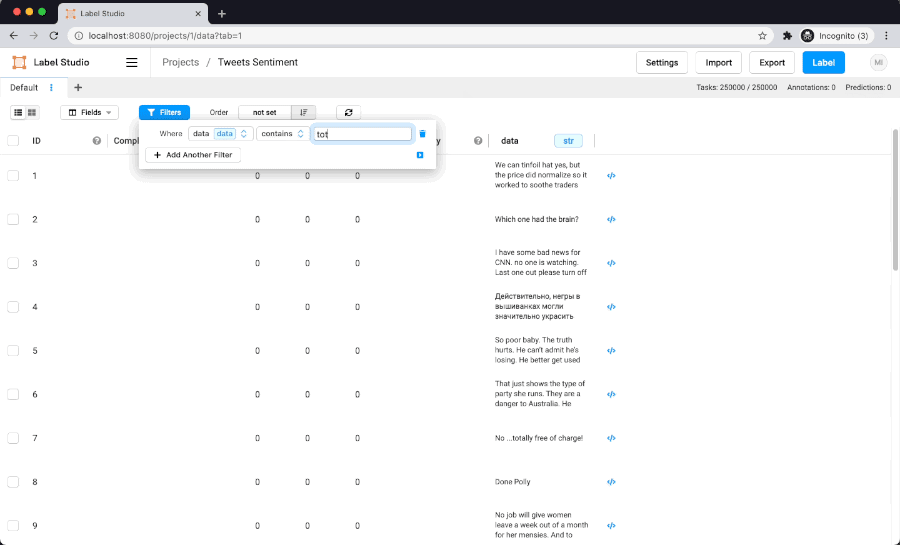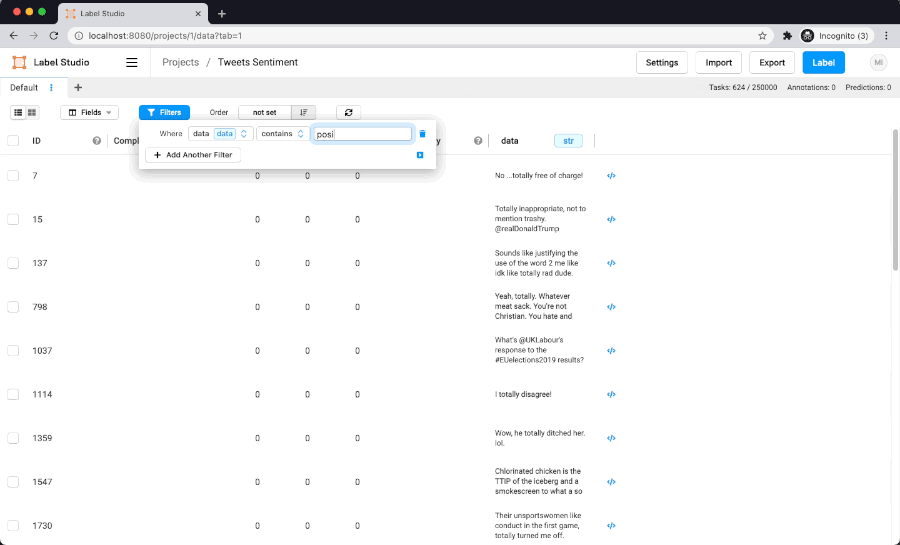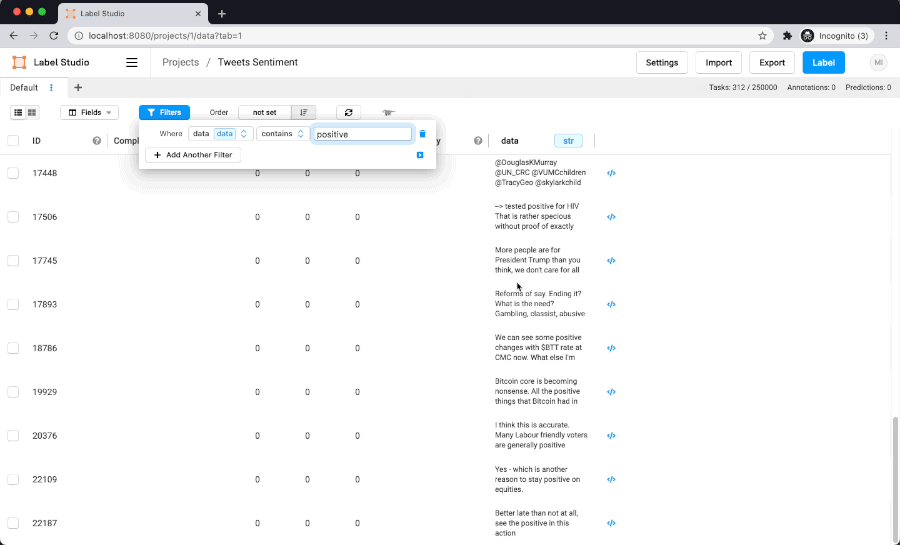
Here is filtering performance on dataset with 250K items
For production deployments, we recommend using PostgreSQL instead of SQLite, especially if you expect to create a large number of users or projects in parallel, because SQLite doesn’t support parallel writes.
What’s next
We hope you’re excited to try out this new version of Label Studio!
For the next month we will be focusing on fixing bugs and issues based on your feedback, so we’d like to ask you to join our Slack channel. The community is very active and no questions go unanswered and no feedback goes unnoticed.
Next, we'll be releasing an update of our Label Studio Enterprise and then working on a new version of Label Studio. The focus for that version is more performance improvements and seamless integration into various ML pipelines. See you in Slack!
Related Content
-
Label Studio 1.20.0: Spectrograms, Time Series Sync, Playground 2.0, and JSONL Support
Label Studio 1.20.0 introduces major upgrades for audio, video, and time series labeling, including spectrogram support, stream synchronization, and easier data imports.

Label Studio Team
July 1, 2025
-
Label Studio 1.19: MajorCloud Storage Updates and More Community-Driven Fixes
Label Studio 1.19 tackles key open source pain points with easier cloud imports, CORS proxy support, and new features like multi-task JSON and KeyPointLabel export.
Label Studio Team
June 10, 2025
-
Dark Mode is Here in Label Studio 1.18
The 1.18.0 release includes the much anticipated Dark Mode setting, the ability to export polygons in COCO format, and a bunch of usability improvements for annotators.
Label Studio Team
May 14, 2025