Survey Report: How Data-Centric AI is Shaping Technology and Workflow Choices
Introduction
Data labeling is critical to data science and machine learning workflows. As new models and frameworks become freely available through academic research and public model repositories, it’s becoming increasingly clear that the quality of the data used to train these models will be a significant differentiating factor for successful ML and AI applications. For example, in the last few years, we’ve seen new language models that can craft long-form text from simple prompts, and new image models that can create stunning images in various genres. To support the development of these models, data labeling is becoming an iterative and continuous process rather than a one-off batch exercise.
As the data labeling landscape is changing, we’re faced with challenges of scale and accuracy. How do we strategically apply data labeling and preparation resources to achieve the most performant models for increasingly complex and specialized business use cases? How do we quickly address the need for high-quality data that is bias-free and accurately labeled?
In this survey, we will explore the current state of the data labeling ecosystem, with an eye toward how thoughtful dataset development will support this shift from model-centric to data-centric AI.
About the Survey
Label Studio is an open source data labeling platform launched in January 2020 to advance data-centric AI through open source software, community building, and knowledge sharing. It is supported by a global community of data scientists committed to building and deploying the most accurate and performant ML and AI models backed by accurately labeled data. Since its initial release, more than 150,000 people worldwide have used Label Studio to annotate nearly 100,000,000 data items, and the project has gathered more than 11,000 stars on GitHub.
In September 2022, the Label Studio community launched its first Community Survey, inviting users to share how they approach data labeling in their machine learning and data science workflows. The survey gathered feedback from users about the Label Studio project with questions about what’s working for them, what features they want to see in future releases, and how to better support the community.
We are grateful to everyone who helped to make this survey possible, especially the survey respondents and the Label Studio community. Your participation and collaboration help to grow this community and advance our shared knowledge of dataset development.
Strategic Perspectives
ML initiatives are strategic to organizations, with greater investment planned in 2023.
77% of survey respondents reported that they successfully have ML models in production, with an additional 15% saying that they will soon have models in production. As the collection of “standard” machine learning models grows, it’s becoming easier to adapt existing models for job-specific applications. Successful ML programs are becoming more of a norm rather than an outlier.
Do you currently have ML/AI models in production?
Response to this survey indicates that machine learning initiatives within organizations will only become more strategic in the coming year. 73% of respondents noted that they would be devoting a higher level of investment to their ML initiatives, and 25% would maintain their investment level. Only 3% indicated that their ML initiatives would receive less investment.
How strategic will machine learning and AI initiatives be to your organization in 2023 and beyond?
Data Labeling is a critical part of AI/ML workflows.
Given the current and future strategic importance of ML initiatives, it’s unsurprising that accurately labeled data is essential for the success of these initiatives. 89% of respondents indicated that accurately labeled data is “very important” to their success, with the remaining 11% stating that it was “somewhat important.” Everyone in the survey said that data labeling was important to the success of their initiatives in some way.
How important is accurately labeled data to the success of your data science initiatives?
When we dig deeper and ask what the most significant challenges organizations face when putting ML models into production are, the vast majority indicate that problems with data are their biggest obstacle. 80% state that accurately labeled data is a challenge. In addition, 46% state that lack of data is also a challenge (in this, and many other questions, respondents were able to indicate multiple answers, so percentages may not add up to 100%). Supporting the hypothesis that we see a shift from model-driven development to dataset development, model development was ranked fifth most cited problem at 20% after monitoring (31%) and team communications (27%).
What are the biggest challenges to getting accurate and performant machine learning & AI initiatives into production?
Data scientists now spend the majority of their time on data prep, iteration and management.
The time spent preparing data is a direct consequence of the importance of data labeling to AI/ML workflows. 72% of survey respondents reported spending 50% or more of their time in the ML/AI lifecycle on data preparation, iteration, and management. Of that group, more than one-third (34%) of respondents said they spend 75% or more of their time on data prep. This trend shows that model development and operation are consuming less time as data labeling becomes the more strategic and valuable component of the AI/ML lifecycle.
As a percentage of your ML/AI lifecycle, how much time do you spend on data preparation, iteration and management?
Data labeling responsibility falls chiefly to data scientists.
46% of respondents reported that data scientists are primarily responsible for data prep in their organizations. Another 18% said this responsibility falls to the annotation team manager, and 14% said MLops personnel or data engineers lead data preparation.
While most respondents have the traditional roles of Data Scientists and Data Engineers, the responsibility for data labeling is broad, requiring engagement across organizations from interns to executives and business leaders. Notably, 20% reported that a mix of roles held the data prep responsibility, including subject matter experts, who accounted for 5% of responses, and business analysts, who accounted for 3%.
These results indicate how organizations label is changing as they look for better ways to involve subject matter experts and iteratively label data to improve model performance.
Who is responsible for data preparation and labeling in your organization?
Survey Demographics
Roles
Survey participants covered a wide range of roles, with data scientists representing the most at 34% of respondents, followed by data engineers at 17%. Academic researchers came in at 11%. The representation of respondents within organizations, from business leaders to interns, indicates that data operations are becoming increasingly important at every level.
What is your role?
The primary data labeling use cases are “Text, NLP, and Documents” and “Computer Vision.”
Use cases for data labeling within organizations covered a variety of domains, with natural language processing rising to 61%, followed by vision at 57%. Audio and video followed at 23% and 19%, respectively.
What are your data labeling use cases?
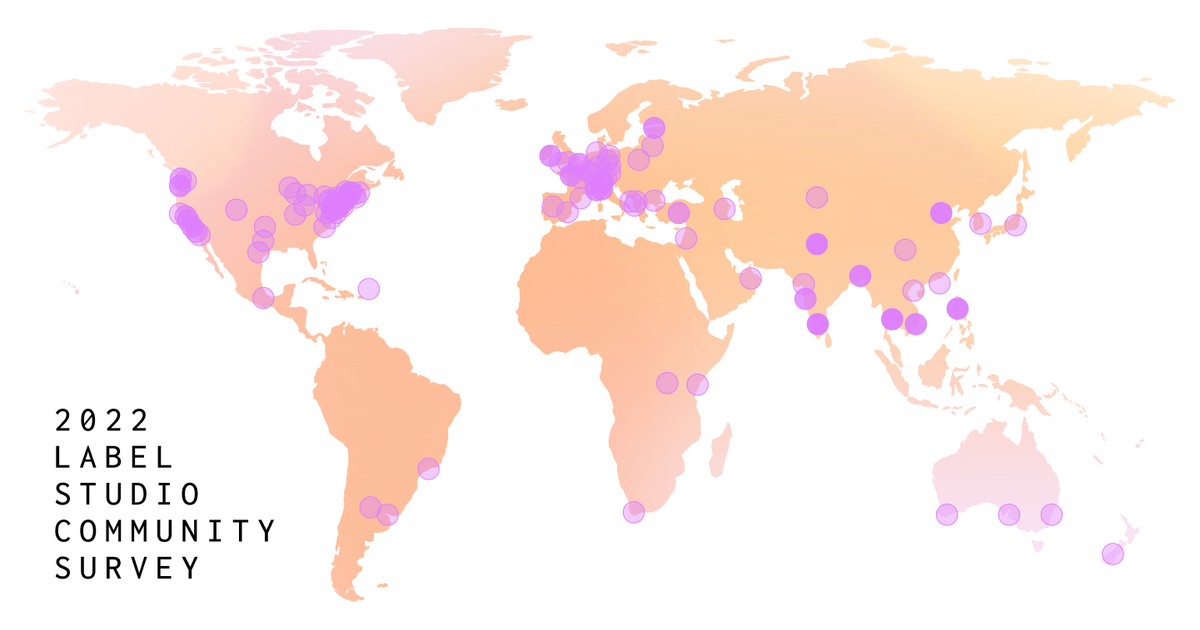
Location by Country
Users from the United States were the primary respondents, representing 31% of the participants. There was worldwide participation in the survey, with India, Germany, and the United Kingdom each representing 6% of respondents.
Technology Landscape
As organizations begin to achieve greater success in adopting ML into their business operations, and they often discover a diversity of options for implementing different parts of their ML pipelines. This effort has competing constraints, including utilizing existing infrastructure, adopting novel technologies to their workflows, and managing sensitive data. As a result of these competing pressures, they face a new challenge: building and maintaining truly differentiated models that outperform previous generations—and those of competitors.
When questioned about the technologies they use to meet these challenges, the responses indicate that organizations use a broad combination of proprietary cloud platforms, open source systems, and home-grown solutions.
Data storage is divided between cloud and on-prem.
When it comes to infrastructure, cloud platforms are a significant driver in the space. The largest cloud providers, combined with local storage, dominate in choices for how and where data are stored. 50% of respondents use AWS for their data storage, with another 20% using GCP and 17% using Azure. Cloud storage is one of many solutions respondents are using, with 38% reporting that they are also using private storage on-prem. Domain-specific solutions, such as Snowflake and Databricks, account for another 10% of storage solutions.
What data storage solutions are you currently using for your data labeling?
Workloads are primarily hosted on cloud offerings, with Hugging Face the most popular source for pre-trained models.
By a large margin of 50%, Hugging Face is where most respondents go to look for models. While Hugging Face is a proprietary platform, it facilitates sharing open models. In some respects, it’s helpful to think of Hugging Face as analogous to GitHub, but in machine learning. Other cloud services, such as SageMaker (at 15% usage), are also being used to host and run models.
What data science and pre-trained model platforms are you using?
The popularity of open source platforms is growing.
While cloud platforms are essential for hosting workloads, when it comes to conducting and orchestrating work, open source providers are adding a tremendous amount of value to the cloud platforms.
Label Studio is just one of the growing number of open source solutions respondents use for their ML workflows. Sixty percent (60%) of respondents reported using other open source platforms. Popular projects include MLFlow for orchestration at 25%, Airflow at 17%, DVC for data versioning at 17%, Great Expectations at 11%, and KubeFlow at 11% of respondents.
Open Source Platforms Respondents are Using
Additional Platform Details
What software do you use for data validation and versioning?
What platforms do you use for pre-trained models?
What platforms do you use for pipeline orchestration and workflow?
What platforms do you use for monitoring?
What platforms do you use for experiment tracking?
What platforms do you use as a feature store?
What platforms do you use for model deployment?
What platforms do you use?
Methodology
Over two weeks in September 2022, more than 110 users responded with insights into their successes and challenges in curating data for their ML operations. We’ve gathered their feedback into this report and are thrilled to share it with the larger data science community.
Chris Hoge, Head of Community for Label Studio, is the primary author of this report.
Related Content
-

Tales from Our Community: Stop the Traffik
When Stop the Traffik lost years of labeled data, they needed a faster, smarter way to rebuild. With Label Studio, they transformed their approach—bringing structure to messy reports, integrating AI for pre-labeling, and uncovering trafficking patterns hidden in plain sight.

HumanSignal Team
March 27, 2025
-

Tales from our Community: Empowering NLP in Low-Resource Languages
Shamsuddeen Hassan Muhammad and his team are advancing African NLP by building language resources for low-resource languages like Hausa. With Label Studio, they scale their efforts to create high-quality datasets for sentiment analysis, hate speech detection, and emotion recognition, making AI more inclusive.

Micaela Kaplan
February 27, 2025
-

Ameru: Labeling for a Greener World
Learn how Ameru is using Label Studio to power their smart garbage bins as they work to accelerate an economically sustainable zero-waste future.
Micaela Kaplan
October 8, 2024