The Future of Data Labeling: Embracing Agents

Introduction
Almost every day, I marvel at the advancements we’ve seen in AI in such a short time. Yet, as monumental as these achievements have been, we are on the cusp of another transformative shift: the rise of agents. These dynamic entities, powered by large language models (LLMs), promise to redefine how we interact with technology, making AI not just a tool but a collaborator and partner in problem-solving.
The Dawn of Agents
“Agents” aren't just the latest trend. Reinforcement Learning (RL) has relied on agents interacting with uncertain environments to achieve goals for years. And from Deep Blue’s defeat of Kasparov to AlphaStar dominating in Starcraft II, agent-based RL techniques have only grown more and more capable. But recently, techniques incorporating generative AI into an agent framework are ushering in a paradigm shift in problem-solving and automation to levels we’ve only seen in sci-fi.
But what are these agents, and why are they pivotal? Put simply, agents are dynamic problem solvers.
Let’s look at an example to understand what this means. Say you want to know the weather for tomorrow. If I ask the free version of ChatGPT to show me the weather in London, it won’t be able to provide me with a reliable answer. It doesn’t have access to real-time weather data. Instead, it may suggest websites that can provide a weather forecast. Now, this isn’t a critique of the capabilities of ChatGPT. The ability to query complex ideas in natural language and have a machine interpret and dialogue with us at this quality is unprecedented. But without tools to aid the LLM, we cannot reliably accomplish even a seemingly simple task. And this is where agents come in.
Instead, what if our system, understanding our request for the weather, could call a weather API for one of the web results it suggested, fetch the data, and present it back to us in the same chat stream? This is precisely the type of interaction agents enable - dynamically solving problems in unknown environments.
The Components Behind Agents
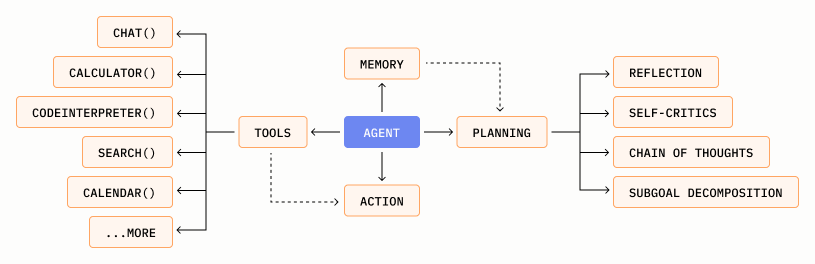
LLMs are the heart of agents. These sophisticated models, tailored for language processing, are the agent's brain, enabling them to return comprehensible responses to intricate requests.
But comprehension is just the beginning. We also need our agent to act on the information; this is where tools come in. We can equip the LLM with tools and APIs that provide supplemental, current information to the agent, allowing it to book flights, perform web searches, or even run code. The horizon is vast.
Overview of an LLM-powered autonomous agent system. (Source)
Hopefully, you can already start to see the puzzle pieces coming together. We have an LLM to interact with to understand what we are trying to accomplish. It has access to some tools that may help to complete our request. We can also include other components to aid the agent, like memory, planning, or subgoals. All of these will further enable our agent to accomplish our task. Let’s go a little deeper into how they work.
The Agent Workflow
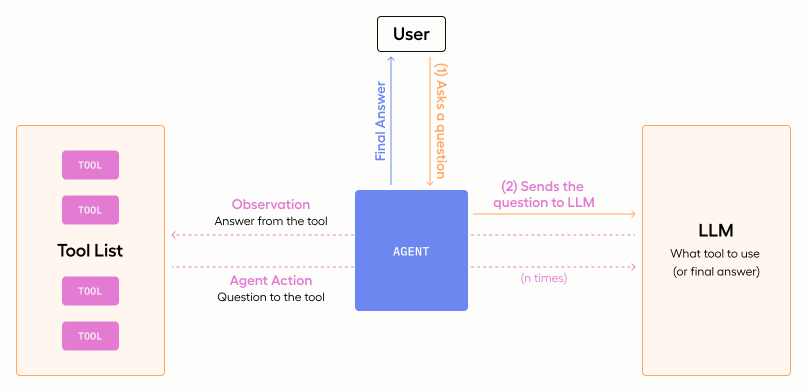
We’ve talked about the components behind agents. Now, let's break down their operational mechanics. Conceptually, an agent's workflow can be represented with the following pseudocode:
while not stopping_condition:
observation = receive_input()
tool = choose_tool() # e.g., an LLM
output = tool.process(observation)
evaluate(output)The first thing we notice here is that we are looping until our stopping condition is met. This tells us that (a) there is a condition our agent is trying to satisfy, and (b) the agent will repeatedly attempt to satisfy that condition until it’s met.
Next, we notice three things.
- We have observations that tell us about our task.
- We can choose a tool to use.
- We can process our observations with this tool.
- We can evaluate and transform our output. This can tell us if our stopping condition is met or if we can use the output as a new observation in the next iteration.
LLM interaction flow for an agent. (Source)
Let's revisit our weather inquiry example. Here, the stopping condition could be phrased as, “Have I obtained a trustworthy forecast for tomorrow's weather in London?” The tools available might include a calendar tool to pinpoint the date "tomorrow" and a weather API to retrieve the forecast.
However, potential hurdles exist. What if the agent initially opts for an unsuitable tool or uses the tool incorrectly? This is where the agent's iterative design combines with the LLM in a truly unique way. When a tool is used, it produces an output. The output might be the desired answer, but it also might be an error message from an API. Either way, the results are returned to the LLM, feeding more information about solving the problem back into the system. This allows the agent to refine its approach, rectify mistakes, and advance its problem-solving process.
While this is a basic illustration, such foundational logic can be expanded to address highly intricate tasks by integrating more sophisticated tools and reasoning capabilities into the agent. A contemporary example is the ReAct method, where, among other things, the LLM provides detailed reasoning in natural language, explaining the agent's reactions to the feedback it receives.

ReAct, one of the more recent agent approaches, incorporates reasoning into actions. (Source)
Overall, agent frameworks and methodologies are rapidly developing to tackle intricate challenges. Now, we circle back to a foundational concern: enhancing the system.
Elevating Data Labeling with Agents
Data labeling is the intricate blend of art and science to enhance AI systems with human expertise. Take a straightforward example: an image of a cat. To us, it's unmistakably a feline. But for a machine, it's a mosaic of pixels. Data labeling decodes this mosaic. It instructs the machine that this specific pixel arrangement signifies a cat. However, we've moved far beyond the rudimentary cat vs. dog classifiers today. Creating the datasets that propelled us to this stage has been instrumental.
At first glance, data labeling might seem like a tangential thought when considering the advanced capabilities of agents. However, in the big picture of AI, data labeling is still a cornerstone. Every sophisticated AI model, from voice assistants to self-driving cars, relies on meticulously curated and labeled data to learn, adapt, and make accurate predictions. This is why we want to infuse this foundational process with the agility of agents.
Improving Efficiency and Accuracy: The Active Learning Workflow
Despite being a foundation element of AI, data labeling has never been particularly efficient. Various techniques to improve efficiency have been employed over time, and one of the most impactful among them is active learning.
The Active Learning Process
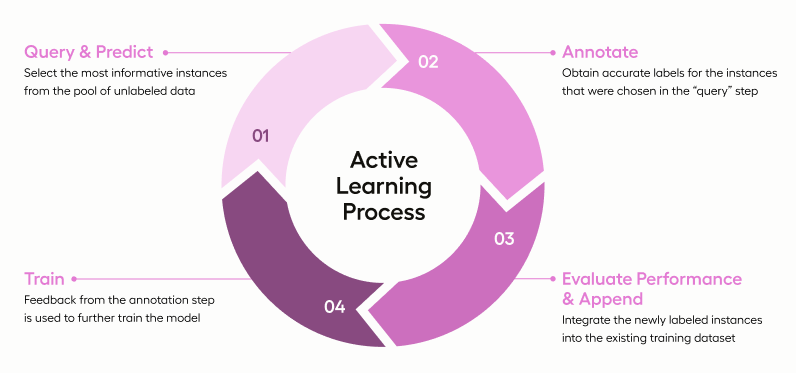
Active Learning is a process that incorporates the human review process with model predictions, using ML models to improve efficiency. The process can be described in four distinct steps:
- Query & Predict: The model or algorithm assesses the unlabeled data, identifies instances it deems most uncertain or ambiguous based on its current knowledge and applies predictions.
- Annotate: Here, the human touch comes into play. Experts review the AI's predictions, verifying the correct ones and rectifying any mistakes.
- Evaluate Performance & Append: This step is about reflection and assessment. The model's performance is gauged, especially on ambiguous or uncertain examples. We then integrate the newly labeled instances into the existing training dataset.
- Train: Feedback from the annotation step is used to train the model further, refining its understanding and improving its accuracy.
We continue this cycle, with each iteration enhancing the model's performance until it reaches a satisfactory level.
Enter Agents: Revolutionizing the Annotation Process
Now, imagine introducing agents into this already streamlined workflow. Similar to active learning, their role is to make the annotation step even more efficient and accurate. In the prediction stage, given the right tools, agents have the potential to assist human annotators by providing predictions to almost any task by pre-processing data, highlighting areas that need attention, and even suggesting possible labels based on patterns they've recognized from previous data.
Adding human-agent collaboration is still crucial when working with agents. The "ground truth" labels provided by human experts serve as the gold standard against which AI models are evaluated. But we can also use agents to aid in improving the model. Using the ground truth data as observations for our agent, we can task the agent to evaluate the model and improve the original prediction stage, suggesting new techniques, creating alternative plans, or creating better prompts for our LLM and tools.
With their dynamic capabilities, agents can potentially adapt to the nuances of different datasets and environments, ensuring that the labeling process remains efficient regardless of the data's nature. Whether it's images, text, or audio, agents with the appropriate tools can tailor their approach to best assist human annotators in creating high-quality datasets.
Looking forward, we can envision a world where data labeling transcends mere technicality to become a collaborative endeavor. In this envisioned future, every label, data point, and piece of human feedback contributes to the development of AI models that are not only intelligent but also context-aware.
As agents take on more responsibilities, we must ensure they don't inadvertently introduce biases or errors into the system. At Label Studio, we're dedicated to mastering this delicate balance. We are actively working to weave human insights into the agent framework, aiming for a future where human expertise and machine efficiency blend effortlessly.
Related Content
-

Adala 0.0.3 Release: More ways to capture feedback, parallel skills execution, and more!
The latest release of Adala, an agent framework to automate data processing tasks, including data labeling and data generation, features more ways to capture feedback and parallel skills execution contributed by a community member.

Nikolai Liubimov
November 16, 2023
-

Our Vision for the Future of Reliable Labeling Agents
Introducing a new open source agent framework that can dramatically increase the efficiency of data labeling (and broader application across data processing tasks), with the unique ability to be guided by human signal: Adala.

Michael Malyuk
October 25, 2023
