Model Training: How Machines Learn from Data
Training is the heartbeat of modern artificial intelligence. It’s the process by which a machine learning model goes from being an unshaped algorithm to a system capable of recognizing patterns, generating language, or making decisions. For teams working on AI applications, whether deploying a recommendation engine, fine-tuning a large language model, or developing computer vision pipelines, understanding how training works is essential.
What Model Training Really Means
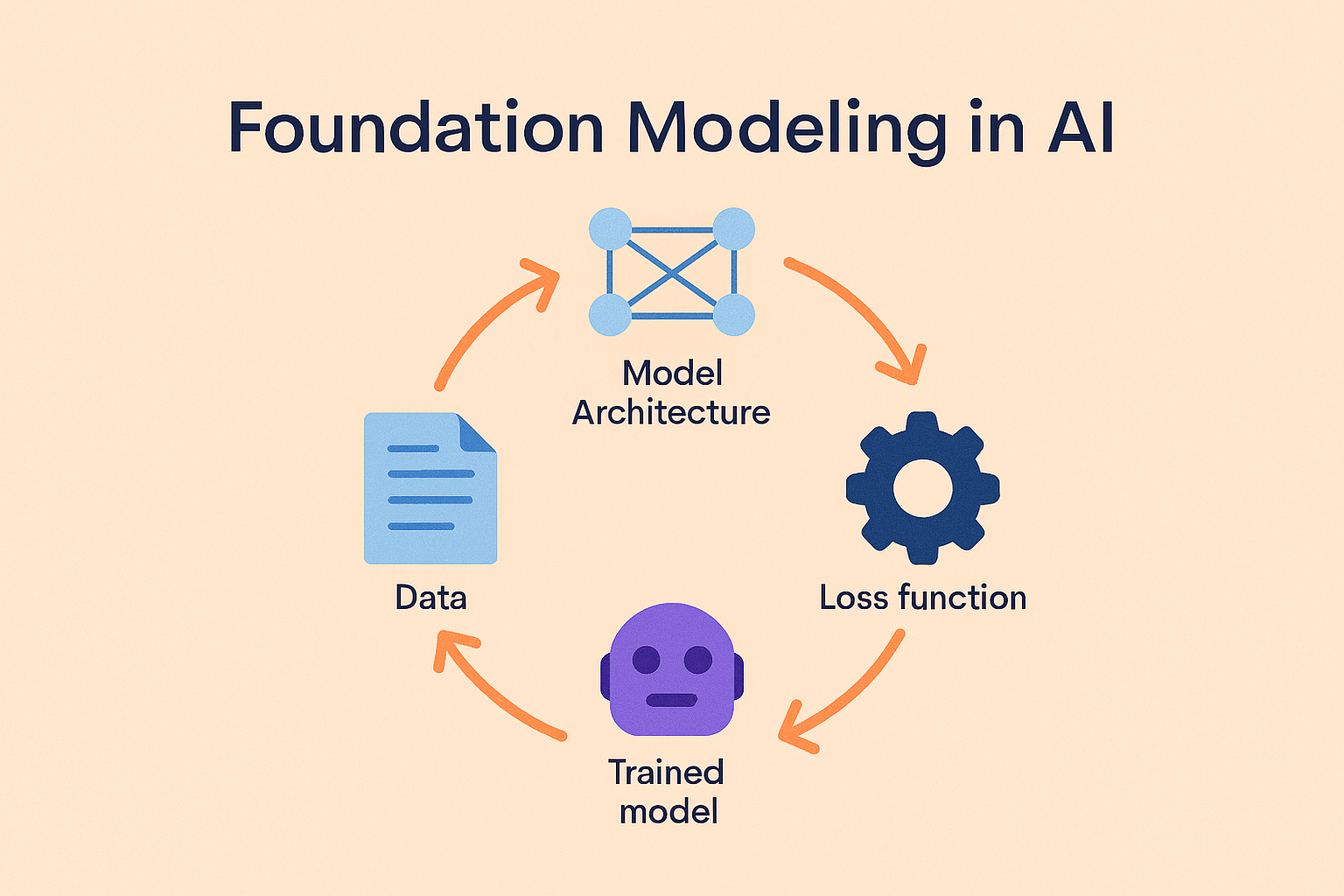
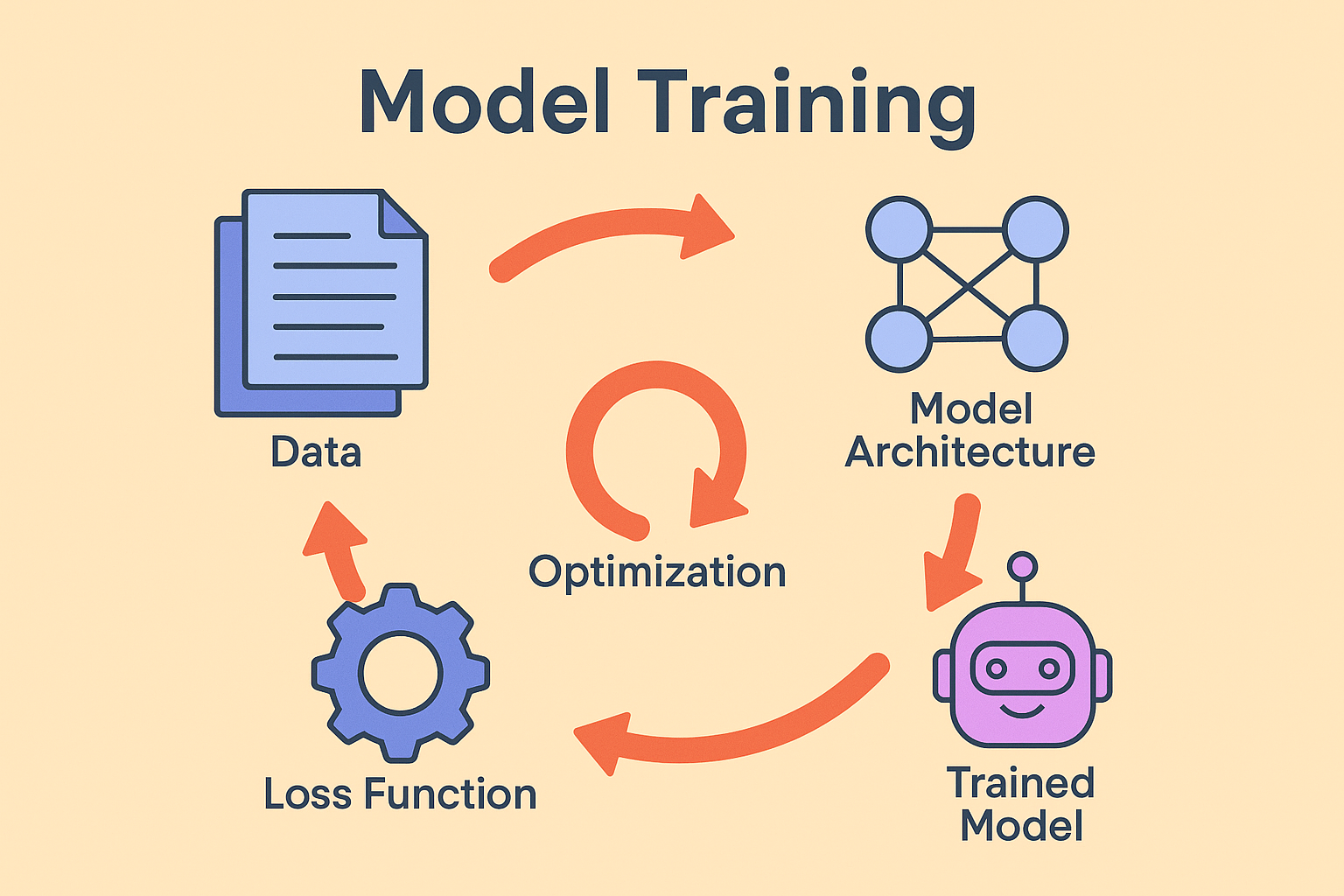
At its core, training a model is about learning from data. You begin with a model architecture, perhaps a convolutional network for image classification or a transformer for natural language processing. This model takes in input data, produces an output, and then compares that output to the correct answer. A loss function measures how far off the model’s prediction was, and optimization algorithms such as stochastic gradient descent adjust internal parameters to reduce that error.
This cycle repeats thousands or even millions of times, gradually refining the model. Over time, the system becomes better at mapping inputs to outputs, whether that means labeling images, predicting the next word in a sentence, or identifying anomalies in financial transactions.
Training, Fine-Tuning, and Inference
It’s important to separate training from related processes. Training from scratch means building a model entirely from raw data, something that only major labs typically do because it requires enormous datasets and compute power. Fine-tuning, on the other hand, takes an existing pre-trained model and adapts it to a specialized task—for instance, taking a general-purpose language model and tailoring it for customer support ticket classification. Finally, inference is the act of running the trained model to generate predictions or outputs in production.
Most applied teams today focus on fine-tuning rather than full training. It’s more efficient and allows you to leverage the strengths of open source foundation models while tailoring them to your own needs. For context, see our resource on open source AI models.
Why Training Matters
The way you train a model has wide-reaching consequences. Accuracy is the most obvious: did the model actually learn to generalize beyond its training data? But training decisions also affect fairness and bias, since models reflect the assumptions and patterns present in the data they learn from. Efficiency is another factor—teams often overtrain models and burn through unnecessary compute cycles. Finally, reproducibility matters. Being able to retrain a model and reproduce its behavior is critical for auditability and compliance, especially under frameworks like the EU AI Act.
Training in Practice
Consider healthcare imaging. Hospitals train diagnostic models to spot anomalies in X-rays or MRIs. Here, training requires special handling of imbalanced data—rare conditions are much less common in the dataset than normal cases, so the model must be carefully trained not to ignore them.
In e-commerce, recommendation engines are continuously retrained on purchase histories and browsing patterns. Training isn’t a one-time event; it’s a cycle that adapts as user behavior shifts.
Language-based systems provide another example. A customer support chatbot may be fine-tuned on an organization’s ticket history, giving it knowledge of domain-specific terminology and workflows. With the right safeguards, training can even be conducted in-house to preserve sensitive data privacy.
Should You Train Your Own Model?
Training isn’t always the right choice. If your use case is common and speed matters, pre-trained APIs or off-the-shelf models may suffice. But if you operate in a regulated industry, need domain-specific knowledge, or require full control over how the model uses your data, training or fine-tuning your own system can be a strategic advantage.
A helpful rule of thumb: use pre-trained APIs for quick, generic solutions; invest in training when control, compliance, or domain expertise is essential. Many teams adopt a hybrid approach, relying on APIs for less sensitive workloads and training for critical tasks.
Best Practices to Keep in Mind
The quality of your data is often more important than the sheer quantity. Carefully curated datasets reduce the risk of overfitting and bias. Validation is key—testing the model against separate data helps ensure it’s learning to generalize rather than memorize. Documentation also matters. Tracking hyperparameters, model versions, and results ensures reproducibility, which is vital for both compliance and long-term maintainability.
Exploring strategies like active learning and data labeling can also improve efficiency by focusing human oversight on the most valuable examples.
Frequently Asked Questions
Frequently Asked Questions
What’s the difference between training and fine-tuning?
Training builds a model from scratch, while fine-tuning adapts an existing model to your dataset or task.
How much data is required for training?
It depends on the complexity. Small classifiers might use thousands of samples, while large models need billions.
Do I need GPUs to train?
Smaller models can run on CPUs, but most deep learning workloads require GPUs or TPUs for efficiency.
Why do models overfit during training?
Overfitting occurs when a model memorizes training data rather than learning generalizable patterns. Techniques like dropout and regularization help mitigate it.
When should I avoid training?
If your use case is generic, off-the-shelf APIs are often faster and cheaper. Training is most valuable when domain-specific accuracy and control are critical.
Related Content
-
Should you run RLHF in-house or bring in a partner?
The cost-vs-control framing leads RLHF teams astray. Learn the three criteria that actually predict whether in-house or partner annotation will work.
-
Training a Model: How AI Systems Learn
Model training is how AI systems learn from data. This guide explains the process, its importance, and when to train versus fine-tune for your use case.
-
What data do you need to train a VLA model?
Training a VLA model isn't a volume problem. Learn why data composition, diversity, and annotation quality matter more than how many episodes you collect.
-
Where robot training data comes from in 2026
Robot training data can't be scraped. Learn where it actually comes from, what makes an episode worth keeping, and how teams decide what to label.
-
How to write a brief that gets you the training data you need
Learn how to write a training data brief that controls annotation quality: task scope, legal provenance, IAA thresholds, and workflow configuration.