Training a Model: How AI Systems Learn
Every modern AI system, from a chatbot to a fraud detector, rests on one fundamental process: training a model. Model training is how an algorithm transforms from a set of mathematical equations into a tool that can recognize images, understand text, or make predictions. Without training, a model is a blank slate; with it, the model becomes capable of applying learned patterns to real-world data.
Understanding how training works is essential not just for machine learning engineers, but also for product teams and decision-makers who need to evaluate trade-offs in cost, accuracy, and scalability.
What Model Training Means
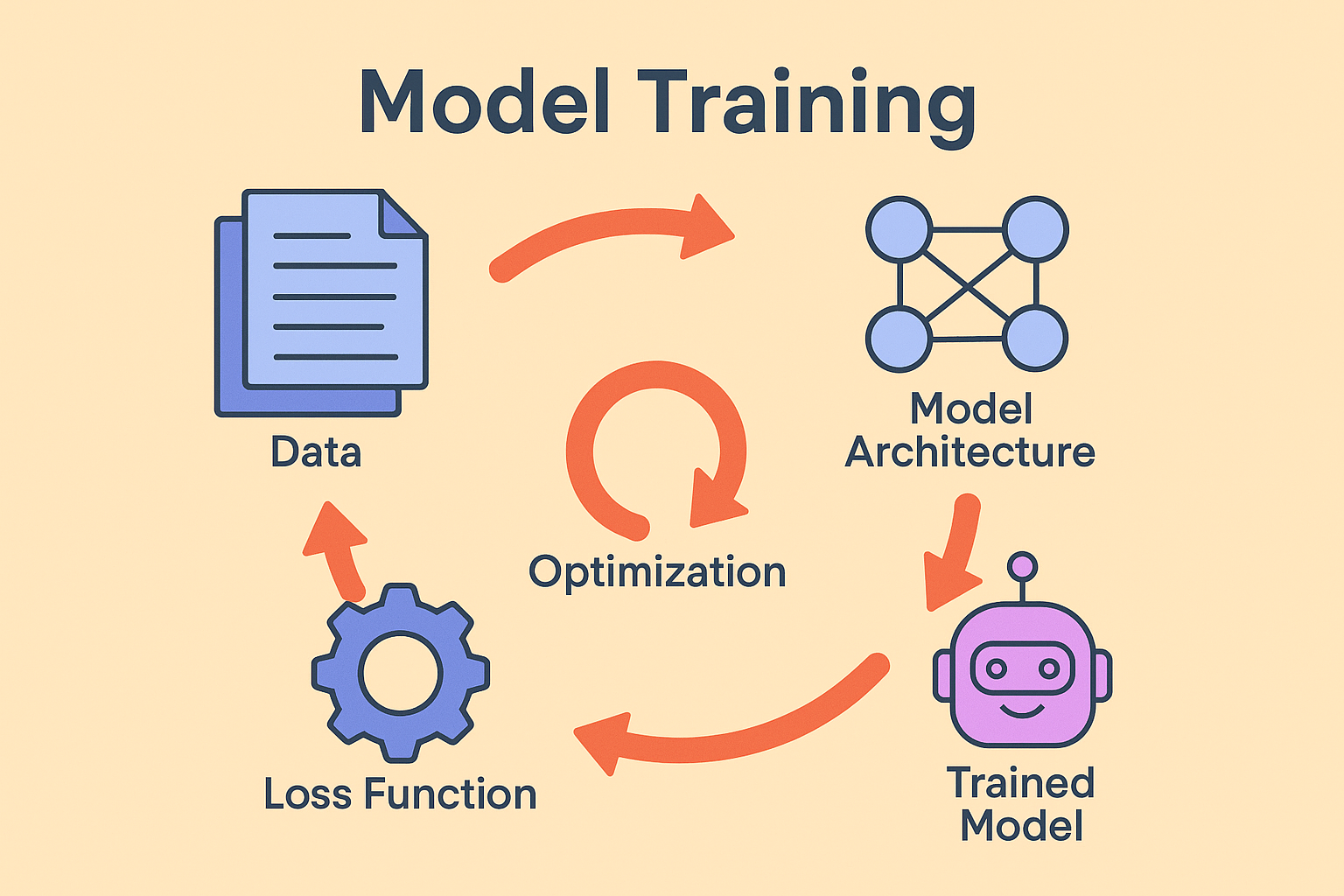
Training a model involves feeding it data and iteratively adjusting its internal parameters until it produces useful outputs. The steps follow a familiar rhythm:
- Start with a model architecture. A convolutional neural network might be used for vision tasks, while a transformer is suited for natural language.
- Expose the model to data. Each input produces an output, such as a classification label or a predicted sequence.
- Measure error with a loss function. This function calculates how far the prediction is from the ground truth.
- Update the parameters. Optimization algorithms like stochastic gradient descent adjust weights to minimize loss.
- Repeat. With enough iterations, the model generalizes patterns from training data and can apply them to new situations.
This cycle, predict, compare, correct, drives progress in machine learning.
Training, Fine-Tuning, and Inference
It’s helpful to separate training from related activities. Training from scratch means building a model entirely from raw data. This is resource-intensive and usually done by research labs or companies building large foundation models.
Most applied teams focus on fine-tuning—taking a pre-trained model and adapting it to a specific domain or dataset. For example, a legal tech company might fine-tune a language model on legal documents so it handles citations and terminology correctly.
Finally, inference is when you use a trained model to generate predictions in production. While training and fine-tuning shape a model’s behavior, inference is where that training creates value for users.
Why Training Matters
How a model is trained has lasting consequences. Accuracy depends not just on the architecture but on whether the training data reflects the real-world environment where the model will be used. Biases can creep in if training data overrepresents certain groups or scenarios, leading to unfair or unsafe outcomes.
Training also affects cost and efficiency. Overtraining can waste compute resources, while undertraining leaves the model brittle. Reproducibility—being able to retrain the same model and achieve the same results—matters for compliance and long-term governance, especially as regulations like the EU AI Act emphasize accountability.
Real-World Applications
- Healthcare diagnostics: Models trained on medical images can flag anomalies in X-rays or CT scans. Training must account for class imbalance, rare conditions are underrepresented but critical to detect.
- E-commerce personalization: Recommendation engines are trained on purchase histories, browsing behavior, and product data. Retraining ensures recommendations adapt as inventory and preferences shift.
- Customer service automation: Teams fine-tune language models on support tickets and FAQs. Training makes assistants domain-specific, improving response quality while keeping sensitive data secure.
These examples show that training isn’t just a technical exercise, it shapes how AI interacts with people and decisions in practice.
When to Train Your Own Model
Not every team needs to train a model. If your use case is generic—like basic text classification or sentiment analysis—using a pre-trained API can get you to production faster. But training or fine-tuning is worth the investment if:
- You require domain expertise (e.g., medical, legal, or financial language).
- Your data must stay private for compliance reasons.
- Off-the-shelf APIs underperform for your specific tasks.
Many organizations adopt a hybrid approach: training models where accuracy and control are critical, and relying on APIs for simpler, low-stakes workloads.
Best Practices in Training
Data quality is more important than raw volume. A smaller, carefully curated dataset often outperforms a massive noisy one. Monitoring validation metrics during training helps prevent overfitting. Documenting experiments, hyperparameters, and model versions ensures reproducibility.
Techniques like active learning, where models suggest the most uncertain samples for human review, can also make training more efficient. For more details, see our resource on data labeling.
Frequently Asked Questions
Frequently Asked Questions
What’s the difference between training and fine-tuning?
Training builds a model from scratch, while fine-tuning adapts an existing model to a specific dataset or domain.
How much data is needed to train a model?
It depends on complexity. Small classifiers may need thousands of samples; foundation models require billions.
Do I need GPUs for training?
Smaller models can be trained on CPUs, but deep learning workloads typically require GPUs or TPUs for efficiency.
Why do models overfit?
Overfitting happens when a model memorizes the training data instead of generalizing. Regularization and validation testing help prevent it.
Is training always necessary?
No. Many use cases are solved with pre-trained APIs. Training makes the most sense when accuracy, compliance, or domain specialization are critical.
Related Content
-
Should you run RLHF in-house or bring in a partner?
The cost-vs-control framing leads RLHF teams astray. Learn the three criteria that actually predict whether in-house or partner annotation will work.
-
What data do you need to train a VLA model?
Training a VLA model isn't a volume problem. Learn why data composition, diversity, and annotation quality matter more than how many episodes you collect.
-
Where robot training data comes from in 2026
Robot training data can't be scraped. Learn where it actually comes from, what makes an episode worth keeping, and how teams decide what to label.
-
How to write a brief that gets you the training data you need
Learn how to write a training data brief that controls annotation quality: task scope, legal provenance, IAA thresholds, and workflow configuration.
-
Model Training: How Machines Learn from Data
Model training is how AI systems learn from data. This guide explains the process, why it matters, and when to train your own models versus using pre-trained ones.