Open Source AI Algorithms

Introduction
The rapid rise of artificial intelligence has been fueled not just by large companies but by the open source community. Open source AI algorithms form the foundation of many modern systems, from natural language processing models to computer vision frameworks. These algorithms are freely available, peer-reviewed, and continuously improved by contributors worldwide. For machine learning engineers, product teams, and data scientists, understanding how and when to use open source algorithms is essential for building practical, scalable systems.
What Do We Mean by “Open Source AI Algorithms”?
An AI algorithm defines how a system processes data to make predictions, classifications, or generate content. When an algorithm is open source, its implementation—often in the form of code libraries or model architectures—is made publicly available under a license that allows others to use, modify, and distribute it.
Classic examples include decision tree libraries, gradient boosting frameworks like XGBoost, and deep learning architectures such as convolutional neural networks (CNNs) or transformers. Open source repositories like scikit-learn, PyTorch, and Hugging Face’s Transformers have turned these concepts into accessible, production-ready tools.
The “algorithm” itself might be a mathematical method, but in practice what engineers rely on are optimized, tested, and shared open source implementations.
Why Open Source Matters in AI
The openness of these algorithms has accelerated AI research and development in three ways:
- Accessibility – Teams don’t need to reinvent the wheel. Instead of writing a transformer model from scratch, they can import a pre-tested implementation.
- Transparency – Open codebases allow researchers and practitioners to inspect how models are built, uncover biases, and propose improvements.
- Community-driven innovation – Open source fosters rapid iteration. Algorithms evolve quickly when thousands of contributors experiment and publish improvements.
For companies building real-world AI applications, this openness shortens development cycles and reduces costs.
Real-World Use Cases
Consider a product team building a document processing pipeline. Instead of starting from zero, they can combine several open source AI algorithms:
- Optical Character Recognition (OCR): Tools like Tesseract extract text from images or PDFs.
- Natural Language Processing (NLP): Transformer-based algorithms like BERT or RoBERTa, available through Hugging Face, enable entity extraction and semantic understanding.
- Clustering and Classification: Scikit-learn’s implementations of k-means or support vector machines allow efficient document categorization.
In computer vision, frameworks like YOLO and Detectron2 make it possible to deploy object detection systems for quality inspection in manufacturing or content moderation in social platforms. In large language models, open source implementations of architectures such as LLaMA have enabled fine-tuned assistants for healthcare, finance, and customer service domains.
When and Why to Use Open Source AI Algorithms
Choosing open source isn’t just about cost savings. It’s about flexibility and trust. Open source algorithms are especially useful when:
- You need full control over the pipeline. For regulated industries, inspecting the code ensures compliance.
- You want to customize. Many companies need domain-specific tweaks—fine-tuning NLP models or adapting vision systems for proprietary datasets.
- You need community support. Popular projects often have active forums, GitHub issues, and peer-reviewed research backing them.
That said, not all open source projects are production-ready. Teams should evaluate factors like documentation quality, update frequency, and license terms before relying on an algorithm for mission-critical systems.
Challenges and Considerations
Despite their benefits, open source AI algorithms aren’t a silver bullet. Teams must consider:
- Maintenance burden. Keeping libraries updated and compatible with infrastructure requires effort.
- Security risks. Open repositories can contain vulnerabilities if not carefully vetted.
- Performance tuning. Out-of-the-box models may not perform optimally on domain-specific tasks without additional training.
This is why many organizations combine open source with enterprise-grade tooling—gaining flexibility while ensuring scalability, monitoring, and governance.
Conclusion
Open source AI algorithms are the backbone of today’s AI ecosystem. They empower teams to innovate faster, leverage community knowledge, and retain control over their systems. For engineers and data scientists, fluency in these tools isn’t optional—it’s the foundation for building reliable and adaptable AI applications.
Frequently Asked Questions
Frequently Asked Questions
What is the difference between an AI algorithm and a model?
An algorithm is the method or process (like gradient descent), while a model is the trained instance of that algorithm applied to data.
Are open source AI algorithms production-ready?
Some are, especially mature projects like scikit-learn or PyTorch. Others may require adaptation, testing, and optimization before production use.
Why should companies choose open source algorithms over proprietary ones?
Open source offers transparency, customization, and community support, while proprietary solutions may trade flexibility for managed scalability.
How do I evaluate which open source algorithm to use?
Look at factors like documentation quality, license type, community activity, benchmark results, and compatibility with your existing infrastructure.
Can open source algorithms handle enterprise-scale workloads?
Yes—many enterprise AI systems run on open source libraries, though organizations often add proprietary layers for security, scaling, and governance.
Related Content
-
Open Source AI Projects: Where Innovation Starts
Open source AI projects are shaping the future of modeling, evaluation, and collaboration. From foundation models to lightweight tools, these efforts make AI more accessible and trustworthy.
-

Open source AI is transforming how teams build, evaluate, and deploy intelligent systems. This hub covers the key tools, models, and strategies shaping the ecosystem today.
-
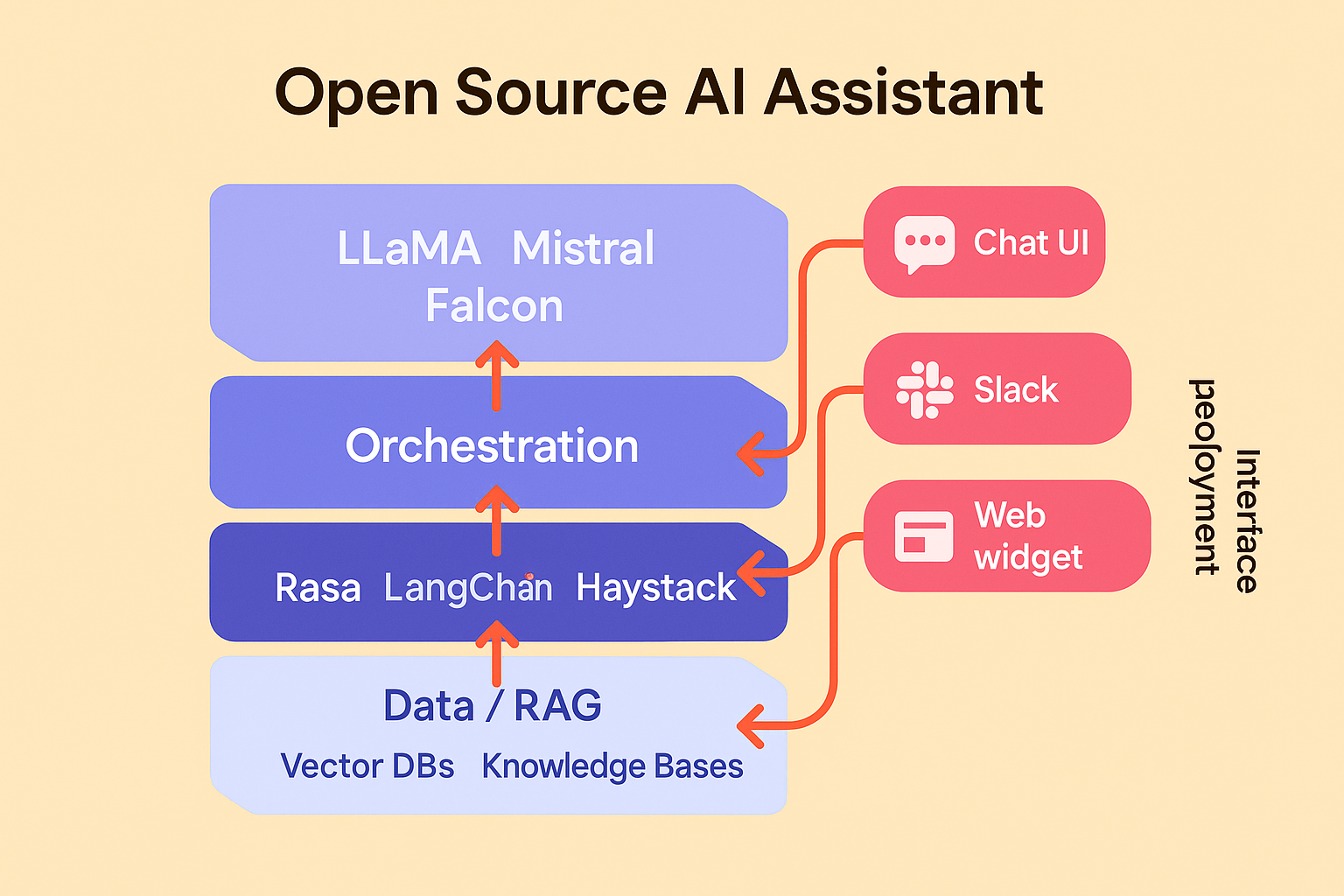
Open Source AI Chatbots and Assistants: Why They Matter
Open source AI chatbots and assistants give teams more control, flexibility, and data security than closed APIs. Here’s how they work and when to use them.