What are Benchmarks
What Are Benchmarks?
In machine learning and applied AI, a benchmark is a standard dataset, task, or metric used to evaluate how well a model performs. Think of it as a shared ruler: if every researcher measures their model against the same test, it becomes easier to compare results.
For example, the GLUE benchmark became a widely adopted standard for testing language models on tasks like sentiment classification or textual entailment. ImageNet has played a similar role in computer vision. These datasets, combined with defined scoring metrics, allow models to be ranked and compared fairly—at least on paper.
The appeal of benchmarks is clear: they make performance visible, reproducible, and competitive. But the story doesn’t end there.
Why Benchmarks Matter
Benchmarks have shaped the trajectory of AI development in several important ways:
- Standardization. Without them, comparing a model trained on tweets with one trained on Wikipedia would be nearly impossible.
- Progress tracking. They show when a new architecture meaningfully improves on the status quo.
- Incentives. Benchmarks drive innovation by providing goals for model builders to surpass.
But benchmarks also create a tension. Beating a benchmark doesn’t always mean a model is useful. For instance, a language model might outperform others on a reading comprehension test but still fail when asked to answer domain-specific customer questions.
Real-World Use Cases
- Language Models in Production. Companies often start with standard benchmarks like MMLU or GLUE when evaluating large language models. These are good for initial screening but rarely capture domain-specific needs, like handling legal documents or customer support transcripts.
- Autonomous Vehicles. Driving benchmarks can measure performance on standardized obstacle recognition tasks, but no dataset can capture the infinite variety of real-world roads. Teams supplement benchmarks with proprietary testing scenarios.
- Healthcare AI. Benchmarks may track diagnostic accuracy on a labeled dataset, but regulators and clinicians care about how well the model performs across hospitals, patient groups, and imaging equipment.
When to Rely on Benchmarks and When Not To
Benchmarks are most useful when:
- You need a quick, reproducible way to compare models.
- You’re evaluating model families at the research or prototyping stage.
- You want to track performance improvements over time.
Benchmarks are less reliable when:
- Your use case involves unique data distributions (e.g., financial documents, medical notes).
- The metric doesn’t align with business or safety goals. A higher F1 score doesn’t always mean happier customers.
- They encourage overfitting to a leaderboard rather than generalization.
That’s why many teams move beyond static benchmarks and build custom evaluation pipelines. These pipelines combine standard tests with domain-specific checks, human-in-the-loop reviews, and evolving datasets.
The Future of Benchmarks
As models grow more capable, benchmarks need to evolve too. Static datasets eventually saturate, when every model achieves near-perfect scores, the benchmark no longer distinguishes meaningful differences.
We’re already seeing this in NLP, where leaderboards for GLUE and SQuAD have maxed out. In response, newer benchmarks (like BIG-Bench for LLMs) aim to capture more diverse tasks. Enterprises, meanwhile, are increasingly building their own benchmarks tailored to their data and KPIs.
The trend is moving away from one-size-fits-all leaderboards and toward domain-specific, evolving benchmarks that reflect real-world complexity.
Frequently Asked Questions
Frequently Asked Questions
Why do we need benchmarks in machine learning?
They provide a common ground for comparing models and tracking progress, which helps researchers and engineers understand what’s working.
Are benchmarks enough to decide which model to use?
Not always. Benchmarks are a starting point, but production models must also be tested against your domain-specific data and success criteria.
What’s the problem with relying only on benchmarks?
They can create misleading confidence if the benchmark doesn’t reflect your real-world conditions. Models that ace benchmarks can still fail in production.
How can I build my own benchmark?
By curating representative data from your domain, defining evaluation criteria that map to business goals, and updating it over time as your data and tasks evolve.
Related Content
-
Do you need a custom benchmark?
Learn why public AI leaderboards constantly fail enterprise deployments and how to scale a continuous evaluation maturity framework from proof-of-concept to production without wasting endless engineering hours.
-
Domain-specific vs. general benchmarks: What's the difference?
Learn the difference between domain-specific and general benchmarks. Understand how to measure artificial intelligence model performance effectively for your specific use case.
-

Where can I find AI benchmark scores for natural language processing models?
You can find NLP benchmark scores quickly on public leaderboards, but the comparisons only hold up when you verify versions, evaluation settings, and the exact model variant being scored.
-
Getting started with benchmark creation
A guide to creating effective benchmarks for evaluating machine learning models, covering data selection, annotation, and iteration.
-
How do benchmarks use ground truth data?
Learn how ground truth data serves as the foundation for evaluating machine learning models and tracking AI benchmark performance.
-

What are the most reliable AI benchmarks used in industry?
The core language, vision, speech, and system benchmarks that teams still rely on to compare models.
-

What services offer AI benchmark reports for enterprise decision-making?
A practical guide to the main sources of AI benchmark reports enterprises use to compare vendors, platforms, and model performance.
-

Which AI benchmark datasets are best for speech recognition tasks?
The best ASR benchmarks depend on your target audio conditions, so the most reliable approach is to pair a standard baseline with a dataset that reflects how people actually speak in your product.
-

What Benchmarks are Used to Evaluate AI fairness and Bias?
AI fairness and bias benchmarks help teams measure whether model performance or behavior changes across groups, identities, or contexts
-
Benchmarks are the measuring sticks of machine learning. They provide a way to evaluate models consistently, compare progress, and understand whether performance holds up in real-world conditions.
-
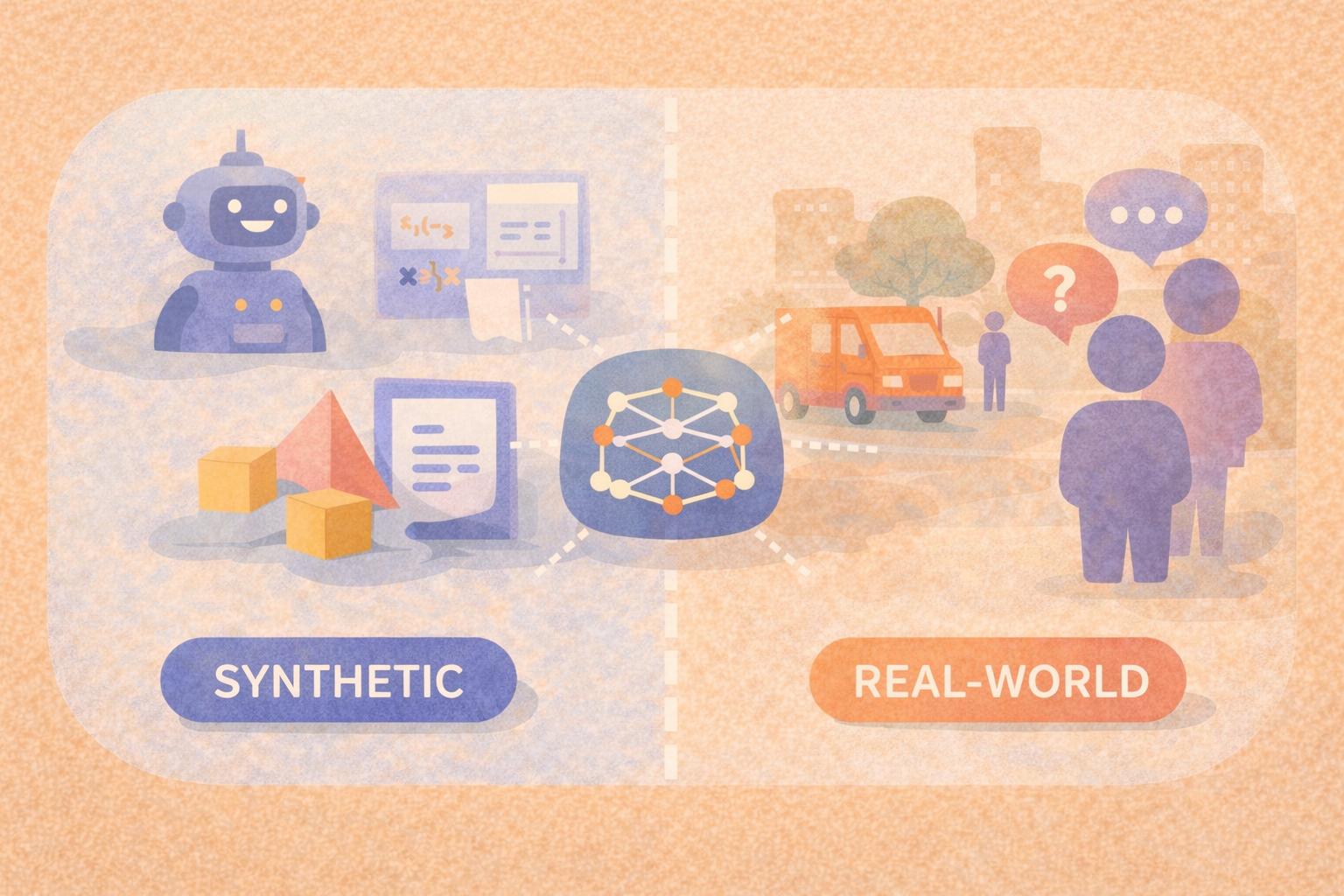
What are the differences between synthetic and real-world AI benchmarks?
Synthetic benchmarks offer control and scalability, while real-world benchmarks expose how AI systems behave under real conditions—and strong evaluation strategies rely on both.
-
Static vs. dynamic benchmarks: What's the difference?
Learn the structural differences between static and dynamic AI evaluations, why purely dynamic tests ruin version control, and how to build a hybrid pipeline.
-

How often are AI benchmarks updated by major testing organizations
Benchmark results are time-bound, so the most reliable comparisons always include the benchmark version, evaluation method, and date.
-

What is the process for submitting AI models to benchmarking challenges?
Submitting an AI model to a benchmarking challenge is less about “upload the model” and more about proving your system can be evaluated fairly.
-

How to interpret AI benchmark results from third-party testing services?
Benchmark scores can be helpful signals, but only if you understand the dataset, scoring method, evaluation setup, and version behind the number.
-
How to choose an LLM benchmark
Public leaderboards are helpful for shortlisting models, but production demands custom evaluation. Learn how to choose an LLM benchmark for your team.
-

What are the differences between synthetic and real-world AI benchmarks?
This article breaks down how synthetic and real-world AI benchmarks differ and why teams need both to understand true model performance.