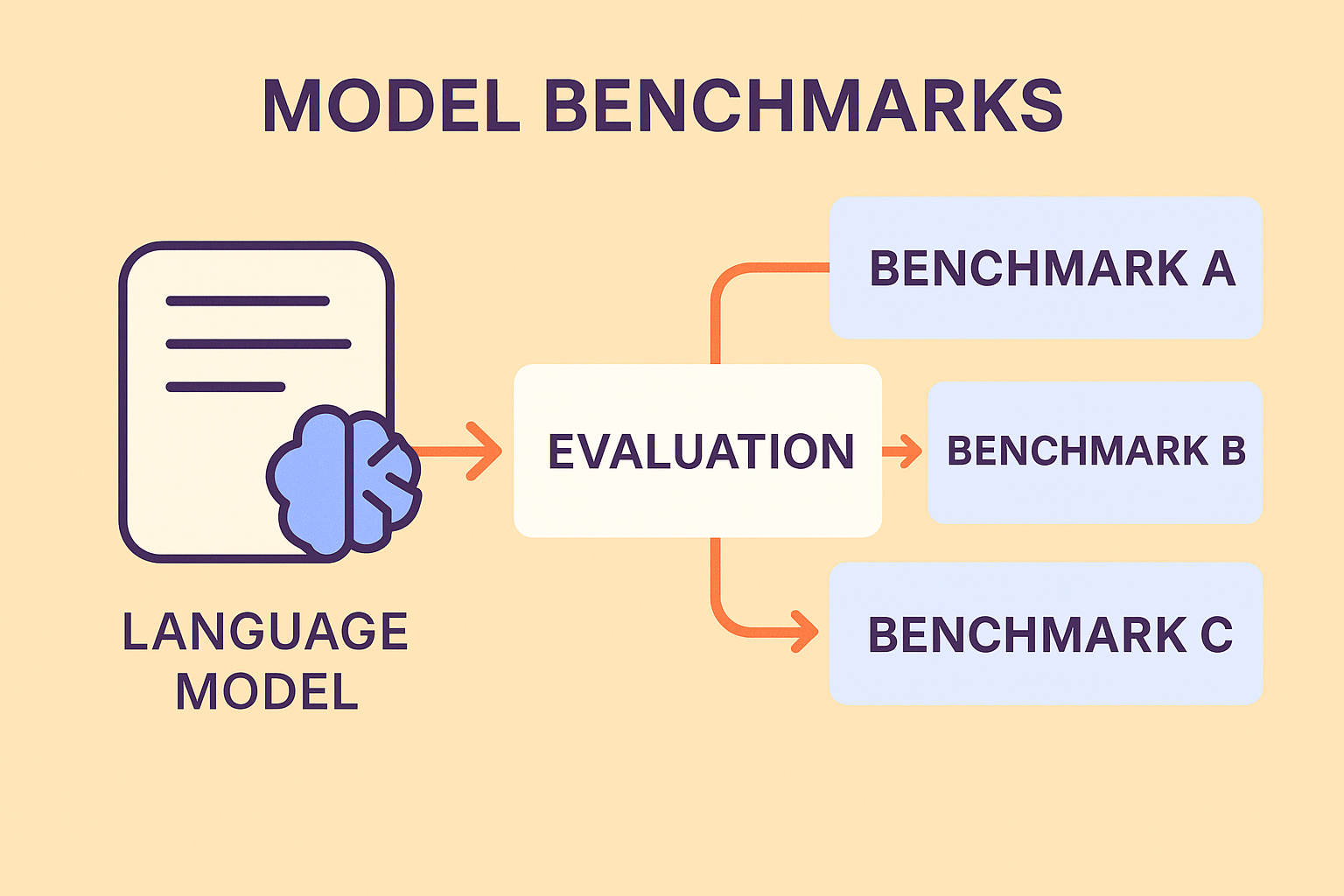
What Are Model Benchmarks
Every machine learning project eventually faces the same question: how do you know if your model is any good? Accuracy numbers alone rarely tell the full story. A model that performs well in training may stumble in production. To make meaningful claims about performance, the field relies on benchmarks, standardized tests designed to evaluate models in consistent, comparable ways.
Benchmarks have become central to how progress in AI is measured, especially in natural language processing (NLP) and large language models (LLMs). They offer a shared yardstick that helps teams see whether improvements are real or just artifacts of cherry-picked examples.
What Are Model Benchmarks?
A model benchmark is a structured dataset, task, or set of evaluation criteria against which models are tested. Benchmarks establish a baseline of difficulty and allow researchers and practitioners to compare models on the same footing.
For example, in computer vision, the ImageNet dataset served as a landmark benchmark for years. In NLP, benchmarks like GLUE and SuperGLUE emerged as reference points for language understanding. These resources aren’t just large datasets—they’re carefully designed tests intended to stress models in ways that reflect useful skills.
Why Benchmarks Matter
Benchmarks serve several critical roles in applied AI:
- Standardization: They provide a consistent framework so teams aren’t inventing new evaluation methods each time.
- Comparability: A common benchmark lets you directly compare model performance, whether you’re testing your own system or evaluating open-source releases.
- Progress Tracking: By publishing results over time, benchmarks show whether newer models genuinely advance the state of the art.
Without benchmarks, it would be nearly impossible to separate genuine breakthroughs from marketing claims.
Real-World Use Cases
Benchmarks aren’t just academic exercises—they guide real-world decision-making:
- Enterprise Model Selection: A product team deciding whether to use a proprietary LLM or an open-source model can look at benchmark results for reading comprehension, summarization, or reasoning.
- Regulatory or Safety Testing: In fields like healthcare or finance, custom benchmarks can test whether models behave reliably under domain-specific constraints.
- Continuous Evaluation: Benchmarks are useful not just once, but as part of ongoing monitoring to see if models degrade over time as they interact with new data.
At HumanSignal, we’ve written about how standard benchmarks can fail to reflect context-specific needs and why custom benchmarks are often necessary to align AI evaluation with your goals. (See also: [How to Build AI Benchmarks That Evolve with Your Models], [Why Benchmarks Matter for Evaluating LLMs]).
Limitations of Benchmarks
Despite their value, benchmarks are not perfect. Some common pitfalls include:
- Overfitting to the Test: If teams optimize specifically for benchmark scores, models may appear strong but generalize poorly.
- Vanity Leaderboards: Public benchmarks often turn into competitions where small gains are celebrated even if they have little practical impact.
- Context Blindness: A benchmark built for general NLP tasks might miss the nuances required for, say, legal reasoning or medical interpretation.
That’s why benchmarks should be viewed as tools, not absolute arbiters. They’re most powerful when combined with custom evaluation methods aligned with your domain and user needs.
When to Use Benchmarks
Benchmarks are especially helpful in:
- Early-Stage Exploration: If you’re deciding between multiple architectures, benchmark scores can narrow your choices quickly.
- Baseline Setting: Before creating a custom test, public benchmarks give you a sense of where your model stands relative to the field.
- Ongoing Monitoring: Benchmarks provide a way to see whether model updates improve or degrade performance over time.
They’re less useful when the stakes involve highly specialized knowledge or regulatory standards, where custom evaluation is essential.
Conclusion
Benchmarks are the foundation of model evaluation, but they should never be the ceiling. They offer consistency and comparability, but real-world AI systems often need more tailored evaluation strategies. Smart teams use public benchmarks to orient themselves, then move beyond them to build custom benchmarks that match their data, risks, and goals.
For deeper dives, see our other Learning Center Resource, "What are Benchmarks?"
Frequently Asked Questions
Frequently Asked Questions
What is the purpose of a model benchmark?
To provide a standardized way to evaluate model performance across tasks and enable fair comparisons.
Are benchmarks the same as accuracy metrics?
Not quite. Benchmarks are collections of tasks or datasets, while accuracy (or precision, recall, etc.) are metrics applied to them.
Do benchmarks guarantee real-world reliability?
No. Benchmarks are proxies. They’re valuable indicators but can miss domain-specific risks and edge cases.
Can I create my own benchmark?
Yes. Many teams design custom benchmarks to test models against their unique data and quality standards.
Related Content
-
Do you need a custom benchmark?
Learn why public AI leaderboards constantly fail enterprise deployments and how to scale a continuous evaluation maturity framework from proof-of-concept to production without wasting endless engineering hours.
-
Domain-specific vs. general benchmarks: What's the difference?
Learn the difference between domain-specific and general benchmarks. Understand how to measure artificial intelligence model performance effectively for your specific use case.
-

Where can I find AI benchmark scores for natural language processing models?
You can find NLP benchmark scores quickly on public leaderboards, but the comparisons only hold up when you verify versions, evaluation settings, and the exact model variant being scored.
-
Getting started with benchmark creation
A guide to creating effective benchmarks for evaluating machine learning models, covering data selection, annotation, and iteration.
-
How do benchmarks use ground truth data?
Learn how ground truth data serves as the foundation for evaluating machine learning models and tracking AI benchmark performance.
-

What are the most reliable AI benchmarks used in industry?
The core language, vision, speech, and system benchmarks that teams still rely on to compare models.
-

What services offer AI benchmark reports for enterprise decision-making?
A practical guide to the main sources of AI benchmark reports enterprises use to compare vendors, platforms, and model performance.
-

Which AI benchmark datasets are best for speech recognition tasks?
The best ASR benchmarks depend on your target audio conditions, so the most reliable approach is to pair a standard baseline with a dataset that reflects how people actually speak in your product.
-

What Benchmarks are Used to Evaluate AI fairness and Bias?
AI fairness and bias benchmarks help teams measure whether model performance or behavior changes across groups, identities, or contexts
-
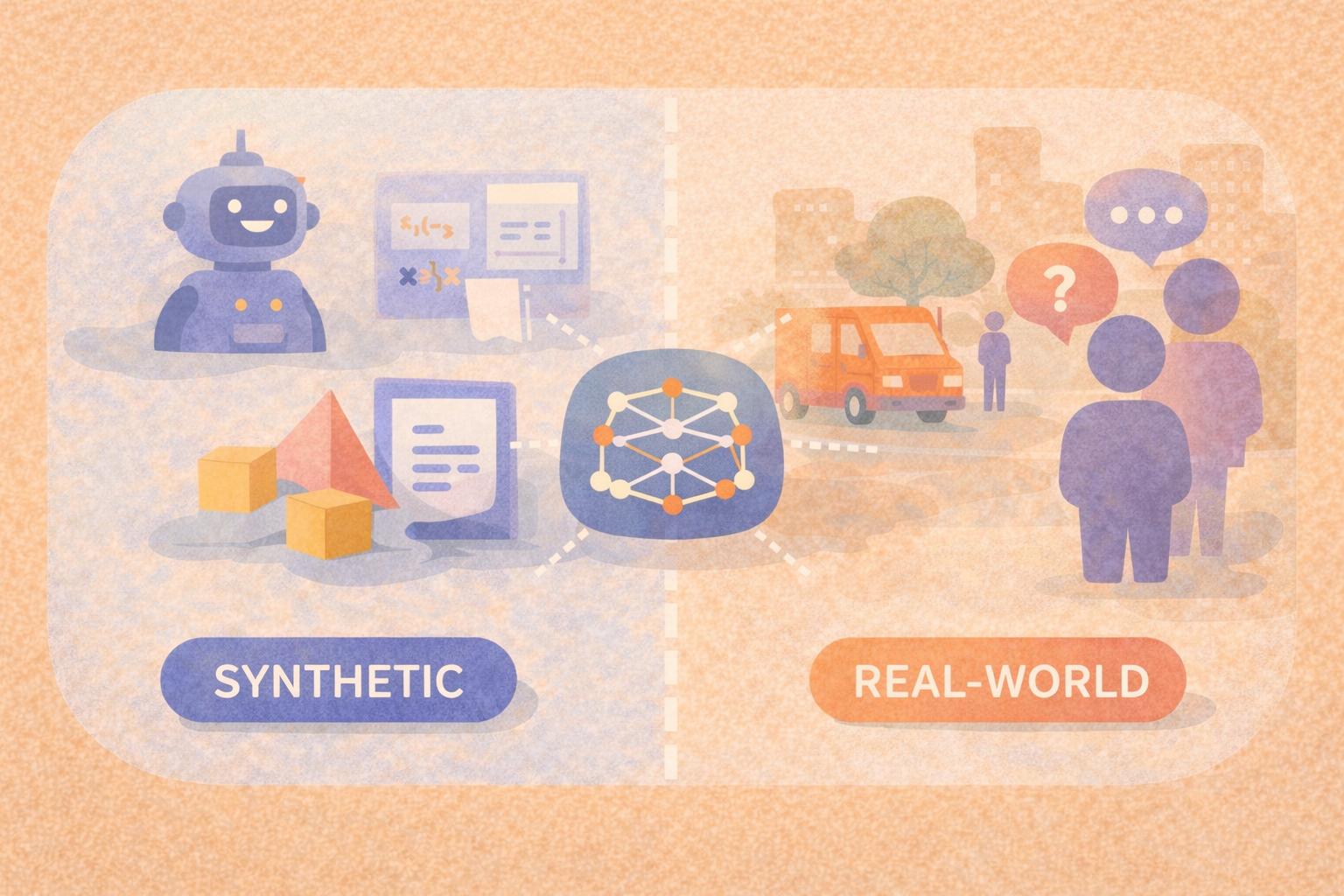
What are the differences between synthetic and real-world AI benchmarks?
Synthetic benchmarks offer control and scalability, while real-world benchmarks expose how AI systems behave under real conditions—and strong evaluation strategies rely on both.
-
Static vs. dynamic benchmarks: What's the difference?
Learn the structural differences between static and dynamic AI evaluations, why purely dynamic tests ruin version control, and how to build a hybrid pipeline.
-

How often are AI benchmarks updated by major testing organizations
Benchmark results are time-bound, so the most reliable comparisons always include the benchmark version, evaluation method, and date.
-

What is the process for submitting AI models to benchmarking challenges?
Submitting an AI model to a benchmarking challenge is less about “upload the model” and more about proving your system can be evaluated fairly.
-

How to interpret AI benchmark results from third-party testing services?
Benchmark scores can be helpful signals, but only if you understand the dataset, scoring method, evaluation setup, and version behind the number.
-
How to choose an LLM benchmark
Public leaderboards are helpful for shortlisting models, but production demands custom evaluation. Learn how to choose an LLM benchmark for your team.
-
Benchmarks provide a common ground for evaluating machine learning models, but their usefulness depends on how well they reflect real-world goals. This guide explains what benchmarks are, when to rely on them, and where they fall short.
-

What are the differences between synthetic and real-world AI benchmarks?
This article breaks down how synthetic and real-world AI benchmarks differ and why teams need both to understand true model performance.