Evaluating Multi-Turn LLM Chat Conversations Using Label Studio
Virtual assistants have become indispensable in handling customer interactions, but their complexity presents a unique challenge. Multi-turn conversations often involve shifting topics, nuanced context, and unexpected user behavior, making it difficult to ensure consistent and effective performance. To improve these systems, we need a clear understanding of where they fall short—and that starts with structured evaluation and human feedback.
One of the most effective ways to evaluate virtual assistants is through turn-level labeling. By breaking down conversations into individual turns, we can analyze each interaction in detail, uncovering issues like missed intents, inadequate responses, or difficulties retaining context. This granular approach is particularly useful in multi-turn conversations, where topics often change, and challenges accumulate over time.
In this blog, we’ll demonstrate how turn-level labeling with Label Studio can help identify gaps and areas for improvement in a virtual assistant. Using a simple e-commerce chatbot as an example, we’ll explore how a focused and iterative evaluation process can make your virtual assistant smarter, more context-aware, and more user-friendly.
Also, you can watch a recording of a live workshop that walks you through this entire process here:
Setting Up Label Studio for Multi-Turn Labeling
Evaluating multi-turn conversations requires a structured setup in Label Studio. This includes creating a project, defining a flexible labeling template, and preparing your data for detailed evaluation. With a clear and well-organized approach, you can ensure that annotations are consistent, actionable, and focused on uncovering key insights to improve your virtual assistant. For a step-by-step walkthrough, check out the full example here.
Creating a Project in Label Studio
To set up our project, we’ll use the Label Studio SDK. The SDK offers greater flexibility for tasks like programmatically generating templates, transforming data, and extracting data for evaluations, making it ideal for handling multi-turn labeling efficiently. Once Label Studio is installed locally or on a server, use the SDK to connect to your instance with an API key from your account. Here’s how you can establish the connection:
from label_studio_sdk.client import LabelStudio
LABEL_STUDIO_URL = 'http://localhost:8080'
API_KEY = '<YOUR_API_KEY>'
client = LabelStudio(base_url=LABEL_STUDIO_URL, api_key=API_KEY)This connection enables you to set up, manage, and evaluate your labeling project programmatically.
Defining the Labeling Template
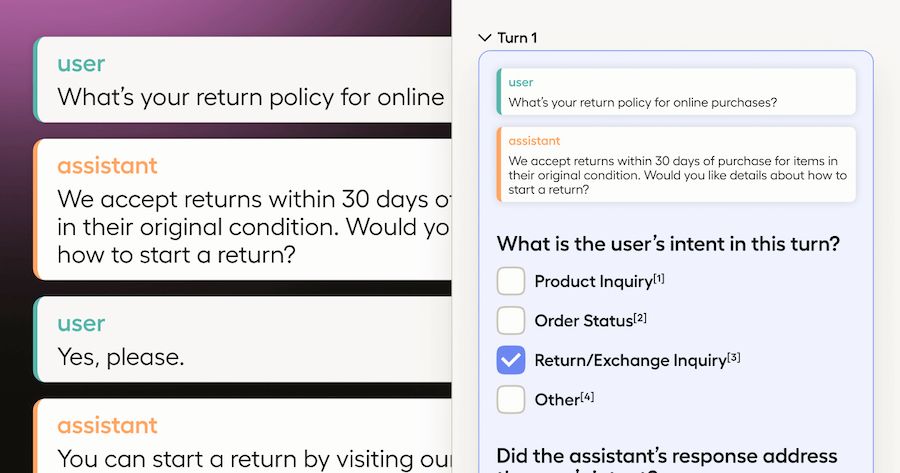
The labeling template is the foundation of your project. It structures how conversations are displayed and how annotators evaluate them. In our setup, we use a multi-panel interface. The left panel displays the entire conversation for context, while the right panel focuses on individual turns with specific evaluation questions. This design ensures annotators can balance the broader context with a detailed analysis of each interaction. Figure 1 shows an example of the multi-turn labeling interface in Label Studio.
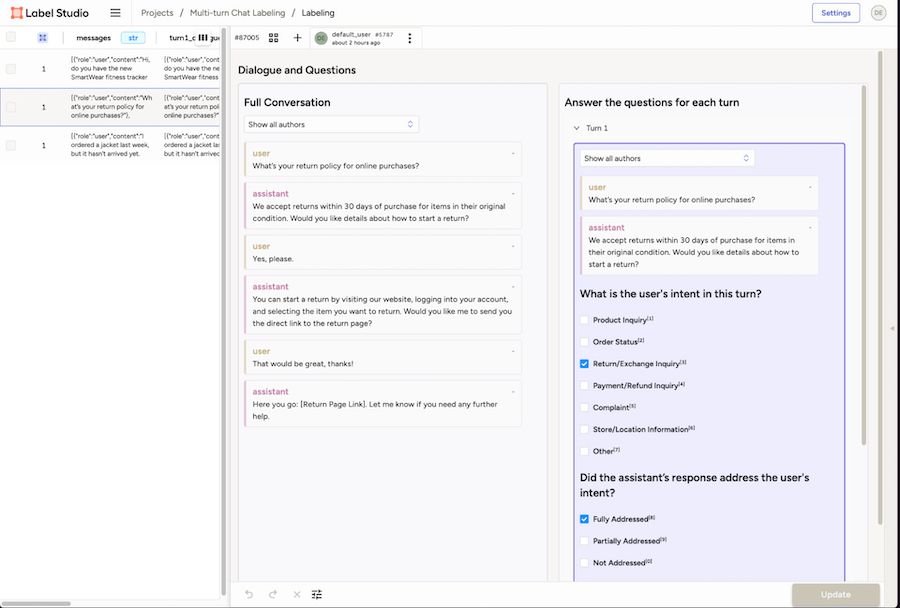
Figure 1: Two-panel, multi-turn chat labeling interface in Label Studio.
At the core of the template are two components:
- Paragraphs: Display the conversation or turn for context.
- Choices: Allow annotators to evaluate attributes like user intent, response accuracy, and helpfulness.
These components are versatile and can be adapted to various labeling needs. Here’s an example of a basic template for annotating user intent:
<View>
<Paragraphs name="conversation" value="$messages" layout="dialogue" />
<Choices name="intent" toName="conversation" choice="single">
<Choice value="Order Status" />
<Choice value="Refund Request" />
<Choice value="Product Inquiry" />
</Choices>
</View>This setup can be customized to fit different chatbot use cases. For instance, you can include questions about technical troubleshooting or escalation scenarios. In our example, we focus on assessing:
- User Intent: Identifying the purpose of the user’s message.
- Response Accuracy: Checking whether the assistant’s reply addressed the user’s intent.
- Helpfulness: Evaluating how useful the assistant’s response was.
- Action Suggestions: Recommending next steps or improvements for the assistant.
Additionally, because a conversation can have many turns, we wouldn’t want to copy, paste, and edit this template for each turn. In the notebook we programmatically configure the template to repeat the questions for each turn and even give them a unique color.
Handling Multi-Turn Conversations with MAX_CHAT_TURNS
Label Studio uses static template configurations, which can be a problem if we have conversations of varying lengths. To manage this, we must have a predefined limit on the number of turns we can label. In the example notebook, we address this programmatically by using a constant `MAX_CHAT_TURNS`. This variable should be set to the longest number of turns in your dataset. For short conversations are padded with empty turns, ensuring a consistent and manageable labeling interface.
For example, if `MAX_CHAT_TURNS` is set to `5`, a conversation with three turns will include two blank slots for consistency, while a conversation with eight turns will be divided into two tasks. This ensures annotators can focus on a manageable set of turns at any given time.
Preparing and Importing Conversation Data
To evaluate conversations in Label Studio, the data must be transformed from its original format to a structure that supports both full conversation views and turn-level analysis. Conversations are initially structured in a format like the following (commonly used in OpenAI’s chat format):
{
"messages": [
{"role": "user", "content": "Hi, do you have the new SmartWear fitness tracker in stock?"},
{"role": "assistant", "content": "Let me check that for you. Which model are you interested in—SmartWear Pro or SmartWear Lite?"},
{"role": "user", "content": "SmartWear Pro."},
{"role": "assistant", "content": "Yes, the SmartWear Pro is in stock in both black and silver. Would you like to place an order or reserve one?"},
{"role": "user", "content": "Can I reserve the black one?"},
{"role": "assistant", "content": "Absolutely! I've reserved a black SmartWear Pro for you. You can pick it up anytime today."}
]
}To align with Label Studio, we use the following function to transform the conversation into a structured format. Each conversation is split into individual turns, with empty slots added to match the MAX_CHAT_TURNS limit for consistency.
def transform_data(data, max_turns):
transformed = []
for conversation in data:
messages = conversation["messages"]
formatted_conversation = {
"data": {
"messages": messages,
**{
f"turn{i+1}_dialogue": messages[i * 2:(i + 1) * 2] if i < len(messages) // 2 else [
{"role": "", "content": ""},
{"role": "", "content": ""}
]
for i in range(max_turns)
}
}
}
transformed.append(formatted_conversation)
return transformedAfter transformation, the conversation is structured like this:
[
{
"data": {
"messages": [
{"role": "user", "content": "Hi, do you have the new SmartWear fitness tracker in stock?"},
{"role": "assistant", "content": "Let me check that for you. Which model are you interested in—SmartWear Pro or SmartWear Lite?"},
{"role": "user", "content": "SmartWear Pro."},
{"role": "assistant", "content": "Yes, the SmartWear Pro is in stock in both black and silver. Would you like to place an order or reserve one?"},
{"role": "user", "content": "Can I reserve the black one?"},
{"role": "assistant", "content": "Absolutely! I've reserved a black SmartWear Pro for you. You can pick it up anytime today."}
],
"turn1_dialogue": [
{"role": "user", "content": "Hi, do you have the new SmartWear fitness tracker in stock?"},
{"role": "assistant", "content": "Let me check that for you. Which model are you interested in—SmartWear Pro or SmartWear Lite?"}
],
"turn2_dialogue": [
{"role": "user", "content": "SmartWear Pro."},
{"role": "assistant", "content": "Yes, the SmartWear Pro is in stock in both black and silver. Would you like to place an order or reserve one?"}
],
"turn3_dialogue": [
{"role": "user", "content": "Can I reserve the black one?"},
{"role": "assistant", "content": "Absolutely! I've reserved a black SmartWear Pro for you. You can pick it up anytime today."}
],
"turn4_dialogue": [
{"role": "", "content": ""},
{"role": "", "content": ""}
],
"turn5_dialogue": [
{"role": "", "content": ""},
{"role": "", "content": ""}
]
}
}
]With our data properly prepared, we can now import it into Label Studio and begin annotating conversations.
for task in multi_turn_tasks:
client.tasks.create(
project=multi_turn_project.id,
data=task['data']
)Customizing for Your Use Case
One of the biggest advantages of using Label Studio is its flexibility. The labeling template can be customized to align with your virtual assistant’s specific requirements.This customization ensures that your annotations are not only consistent but also actionable. High-quality annotations enable you to refine training data, optimize conversation flows, and address recurring issues. With a strong setup in place, your evaluation process becomes scalable and impactful, giving you the tools to continually improve your virtual assistant’s performance.
Next, we’ll label the data and explore how to analyze the labeled data to turn these insights into meaningful improvements.
Evaluating Feedback
Now that the data has been annotated, the next step is to uncover actionable insights that can guide the improvement of your virtual assistant. By analyzing the labeled data, we can identify patterns, evaluate performance, and highlight areas for refinement. For this example, we’ll use a notebook to analyze the data, but for more advanced evaluations, tools like Human Signal’s SaaS platform provide additional metrics and evaluations at scale.
Here’s a sample of the annotated data exported from Label Studio (Tabel 1). Each row represents holds feedback for the variety of questions we asked about our virtual assistant’s conversations:
| Task ID | Turn | Field | Choice |
| 87004 | turn1 | turn1_user_intent | Product Inquiry |
| 87004 | turn1 | turn1_response_... | Partially Addressed |
| 87004 | turn1 | turn1_response_... | Yes, Accurate and Helpful |
| 87004 | turn1 | turn1_response_... | Request More Information |
| 87004 | turn2 | turn2_user_intent | Product Inquiry |
| 87004 | turn2 | turn2_response_... | Fully Addressed |
Table 1: Labeled Tasks exported from Label Studio.
Using the results from the labeling tasks, we can extract several metrics to help us understand the results.
Turn-Level Metrics
At the turn level, metrics help us understand how effectively the assistant responds to user requests. These metrics provide a detailed view of what users ask for and how well the assistant handles these queries.
User Intent Distribution
| User Intent | Count |
| Return/Exchange Inquiry | 3 |
| Product Inquiry | 2 |
| Order Status | 2 |
| Other | 1 |
| Payment/Refund Inquiry | 1 |
Table 2: User Intent Distribution.
The user intent distribution (Table 2) shows that “Return/Exchange Inquiry” and “Product Inquiry” dominate user interactions. These high-frequency intents should be prioritized for optimization to ensure the assistant meets users’ most common needs. Conversely, the low number of queries about payment or “other” suggests potential gaps in the assistant’s scope, highlighting areas where functionality can be expanded.
Assistant Intent Addressing
| Addressing Outcome | Count |
| Fully Addressed | 7 |
| Partially Addressed | 2 |
Table 3: Assistant Intent Addressing.
Table 3 evaluates how well the assistant resolves user intents. Fully addressed queries indicate the assistant’s strengths, where user needs were met entirely. However, partially addressed queries reveal areas where responses lacked completeness. For example, a user may receive partial product information without critical details like availability or pricing. Addressing these gaps will improve response quality and ensure a more consistent user experience. It should be noted, however, that this metric is on a turn-level scope. The user may have had multiple partially addressed intents throughout a conversation.
Response Quality
| Accuracy and Helpfulness | Percentage |
| Yes, Accurate and Helpful | 100.000000 |
Table 4: Assistant Response Quality.
All evaluated responses in this sample were labeled as accurate and helpful (Table 4). This indicates the assistant performs well in providing correct information when queries are understood. However, as datasets grow and scenarios become more complex, this metric may uncover areas that require further training or updates to the assistant’s knowledge base.
Assistant Implied Actions
Assistant responses were also labeled according to what action was implied. In some cases, this is simple, for example “Provide More Information” and “Request More Information” appear frequently, indicating that conversations often require additional clarification or context. However, in other cases, actions can be more nuanced. For example, if the virtual assistant states that it has performed a refund, we may want to perform additional analysis to find out if this step was actually performed.
| Suggested Action | Count |
| Provide More Information to the User | 4 |
| Request More Information from the User | 3 |
| Confirm Action Taken | 2 |
Table 5: Assistant Response Quality.
Conversation-level Metrics
Beyond individual turns, conversation-level metrics provide insights into how interactions evolve. These metrics help identify transitions, bottlenecks, and opportunities to improve the assistant’s flow and context retention.
Intent Transitions
| Other | Product Inquiry | Payment/Refund Inquiry | Return/Exchange Inquiry | Order Status | |
| Other | 0 | 0 | 0 | 0 | 0 |
| Product Inquiry | 1 | 1 | 0 | 0 | 0 |
| Payment/Refund Inquiry | 0 | 0 | 0 | 0 | 0 |
| Return/Exchange Inquiry | 0 | 0 | 2 | 0 | 0 |
| Order Status | 0 | 0 | 1 | 0 | 1 |
Table 6: Intent Transition Matrix (what intent transitioned into another intent).
The Intent Transition Matrix (Table 6) highlights how users move between intents during conversations. For example, frequent transitions within “Return/Exchange Inquiry” suggest users often need to ask follow-up questions, pointing to gaps in resolution. Transitions from “Order Status” to “Payment/Refund Inquiry” may signal user frustration with incomplete updates, emphasizing the need for clearer and more comprehensive messaging.
In the analysis of our reviewed chat interactions (Table 5), we see mostly requests for additional information. This suggests an opportunity to refine the assistant’s responses to be more proactive with the information on a topic, reducing the need for follow-ups, but we’ll want to look more into the specifics later.
| Total Conversations | Consistent Conversations | Percentage Consistent | |
| Intent Consistency | 3 | 1 | 33.33% |
Table 7: Intent Consistency (how often did users have a single intent across the conversation).
Table 7 reveals that only 33% of conversations remained consistent in intent, with users frequently shifting topics. This highlights the importance of improving the assistant’s ability to handle multi-intent scenarios, retaining context across transitions to deliver more seamless interactions.
| Intent Sequence | Count |
| ('Product Inquiry', 'Product Inquiry', 'Other') | 1 |
| ('Return/Exchange Inquiry', 'Return/Exchange Inquiry', 'Return/Exchange Inquiry') | 1 |
| ('Order Status', 'Order Status', 'Payment/Refund Inquiry') | 1 |
Table 8: Top-5 most common transition patterns.
Table 8 identifies common transition patterns within conversations. These sequences often highlight areas of user friction or unresolved concerns. Addressing these patterns can streamline the conversation flow and improve resolution times.
Next Steps for Improvement
The findings from this evaluation provide a clear roadmap for enhancing the virtual assistant’s performance. Optimizing responses for high-frequency intents like “Return/Exchange Inquiry” and “Product Inquiry” can yield immediate benefits by addressing the bulk of user interactions. Additionally, improving responses for partially addressed queries will enhance the overall user experience by reducing gaps in information.
Context management is another key area for improvement. By strengthening the assistant’s ability to retain and utilize context across multi-turn conversations, users will experience fewer misunderstandings or repeated queries. This is especially important for handling transitions between topics, such as moving from “Order Status” to “Refund Request.”
Finally, this evaluation underscores the importance of a continuous feedback loop. By regularly labeling and analyzing new conversations, the assistant’s performance can be tracked and iteratively improved to ensure it aligns with evolving user needs.
By leveraging these insights, teams can create a virtual assistant that is not only accurate and helpful but also capable of handling complex, dynamic interactions with confidence.
Iterating Towards Better Virtual Assistants
Evaluating multi-turn conversations is essential for improving virtual assistants. By combining structured labeling, detailed metrics, and iterative feedback loops, teams can pinpoint where assistants excel and where they need improvement. Metrics like user intent distribution, response quality, and intent transitions offer actionable insights to refine responses, optimize conversation flows, and enhance context retention.
With tools like Label Studio and platforms such as Human Signal, evaluations can scale to meet growing needs. The key to success lies in continuous iteration—analyzing data, addressing gaps, and refining capabilities to create a smarter, more user-friendly assistant that evolves alongside user expectations.
Want to see this process in action? Join me for a live workshop on Wednesday, January 29, 2025 at 12 Eastern / 9 Pacific. You can register here!
Related Content
-

The 5 Metrics That Actually Move AI Into Production
A practical framework for turning AI metrics into clearer decisions about what to fix, ship, and scale.

Sheree Zhang
April 15, 2026
-

Scaling AI Data Quality: Best Practices for Onboarding and Evaluating Annotators
A practical workflow for onboarding and evaluating annotators with clear instructions, calibration, quality gates, reviewer feedback, and dashboards that keep labeling consistent as volume grows.

Alec Harris
March 12, 2026
-

How to Create a Prompt Generator with Label Studio and RLVR
In this article, you'll learn how to apply an RLVR-based score verifier and use an LLM as a prompt optimizer to enhance your prompts.

Label Studio Team
March 2, 2026