Five Open Dataset Resources For Fine-Tuning and Training AI Models

Collecting and cleansing data can be time-consuming and expensive. Now, let's dive into the top 5 open dataset resources that could be the key to your next project's success.But if you have an upcoming project that doesn’t require using your own dataset, you can cut some time from the process by using an open dataset. By leveraging an open dataset, anyone can easily obtain organized data on just about any topic you can collect data on.
At its core, open data is data anyone can use, reuse, and redistribute. Open datasets available for public use are usually only subject to limitations that preserve their provenance and availability, meaning you can use them in any way possible that doesn’t damage or cut access to the original source.
If you’re looking for an open dataset to help you train a machine learning (ML) model, further a software development project, or are just curious to see what’s out there, here are five places to look.
Benefits of Using Public Data Sets
Using public datasets for large language model (LLM) training and fine-tuning offers several advantages:
- Broad Knowledge Base: Public datasets often encompass a wide range of topics, which can help the model gain a comprehensive understanding of diverse subjects.
- Cost-Efficient: Acquiring and curating proprietary datasets can be expensive and time-consuming. Public datasets are typically free and have already undergone a degree of preprocessing, making them a cost-effective solution.
- Reproducibility: Using public datasets can make experiments more reproducible. When researchers and developers use the same datasets, it's easier to compare results and build on each other's work.
- Benchmarking: Public datasets, especially those that are widely recognized in the AI community, are often used as benchmarks. Training or fine-tuning on these datasets allows for a standard comparison of model performance against other models.
- Trust and Transparency: Using public datasets can increase the trustworthiness of a model. When others know the sources of data the model was trained on, it can help in understanding the model's biases and potential limitations.
- Regular Updates: Some public datasets are regularly updated, ensuring that models trained on them are kept current.
- Diverse Input: Public datasets often have contributions from a wide range of sources, which can introduce the model to various writing styles, perspectives, and nuances.
- Legal and Ethical Considerations: Using proprietary or private data can introduce legal and ethical challenges. Public datasets, especially those designed for research purposes, often come with clearer licensing terms and fewer privacy concerns.
- Community Support: Popular public datasets often have community support, meaning there may be forums, tools, and additional resources available to help with the training and fine-tuning process.
- Faster Iteration: Since public datasets are readily available, developers can quickly iterate on model designs, training regimes, and fine-tuning techniques without waiting for proprietary data collection and curation.
- Cross-Domain Knowledge: Public datasets often span multiple domains, from news articles to scientific papers to web pages. Training on such diverse data can make the LLM more versatile.
While public datasets offer numerous advantages, it's essential to be aware of their limitations and potential biases. Ensuring a fair and unbiased model requires careful consideration of the data sources and potentially combining multiple datasets or performing additional fine-tuning.
Five Sources for Training AI Models
As you embark on your journey of training AI models, one of the most important components to consider is the quality and relevance of your datasets. In the vast world of data collection, it can be challenging to find the right sources. However, worry not because we're here to help guide you to some of the best open dataset resources available for your next project. These resources are treasure troves of high-quality, diverse datasets that will help you improve your models and make your data labeling tasks in Label Studio more efficient and effective.
GitHub
GitHub is one of the most popular online resources for developers across the globe. With around 100 million users, you can find just about anything to help with an open-source project — including datasets.
For example: The awesomedata Github account , access a plethora of datasets organized by topic. Some of the datasets available on this account focus on healthcare, eSports, education, and even psychology. The best part is that this isn’t the only account that offers open datasets. There is an ocean of open datasets to utilize on GitHub, so it shouldn’t take too long to find what you’re looking for.Another great resource is the
Google Cloud Public Datasets
In addition to everything Google provides, they also have a valuable collection of datasets available for public use. Powered by Cloud Storage, BigQuery, Earth Engine, and other Google Cloud services, Google’s open datasets enable users to strengthen their data analytics and ML projects with fully managed data pipelines.
On Google’s dataset page, Google not only highlights datasets for use, but also lists potential use cases for them, such as:
- Google Trends: Identify the most searched retail items in a specific geographical location.
- LinkUp: Create models that can analyze and predict job growth by sector level.
- House Canary: Better inform your housing investment decisions with access to 40-year historical volatility data.
AWS Open Data Registry
Amazon Web Services (AWS) has an Open Data Registry that acts as a repository for datasets available through public AWS resources. The datasets available through the AWS Open Data Registry are not maintained by AWS itself but through various third parties such as researchers, businesses, government organizations, and individuals.
Similar to Google’s public datasets, AWS provides examples of how some open datasets have been leveraged before. Take, for example, Common Crawl — a non-profit organization that crawls the internet and makes every dataset and archive available for public use, for free. Through AWS, author Jonathan Dunn leveraged a dataset from Common Crawl to write a paper titled "Mapping Languages: The Corpus of Global Language Use."
Kaggle
A subsidiary of Google, Kaggle is an online community of data scientists and machine learning (ML) engineers. With almost 23,000 open datasets available for use, Kaggle supports users in publishing datasets, building AI models, collaborating with other data scientists and engineers, and even entering data science competitions!
Check out all the datasets you can leverage on Kaggle, ranging in topics from coffee quality, to average job salaries, current Netflix subscriber count, and much more.
Data.gov
At data.gov, you can leverage datasets straight from federal agencies thanks to the OPEN Government Data Act. The OPEN Government Data Act is a statute requiring all U.S. federal agencies to make their information publicly accessible online in the form of open data.
By providing access to datasets published by federal agencies across the U.S., the government hopes to encourage more citizen participation in government initiatives, build up economic development, support the idea of a transparent government, and enable better decision-making in both private and public sectors. With over 250,000 datasets available for use, the possibilities are endless.
How to Leverage Open Datasets Responsibly
When utilizing open datasets for any type of project, it’s important to use them with caution — as you don’t have any control over the quality and cleanliness of said data.
Using your own datasets not only guarantees that the data you’re using is high-quality (because you know first-hand how it was gathered), but it also gives your organization a competitive advantage. Any organization can leverage an open dataset, but it can’t access your organization’s datasets without permission.
If you’d like to learn even more about the many uses of datasets, check out how you can use reinforcement learning with human feedback to ensure that the data used to train an ML model is diverse and free from bias.
Related Content
-
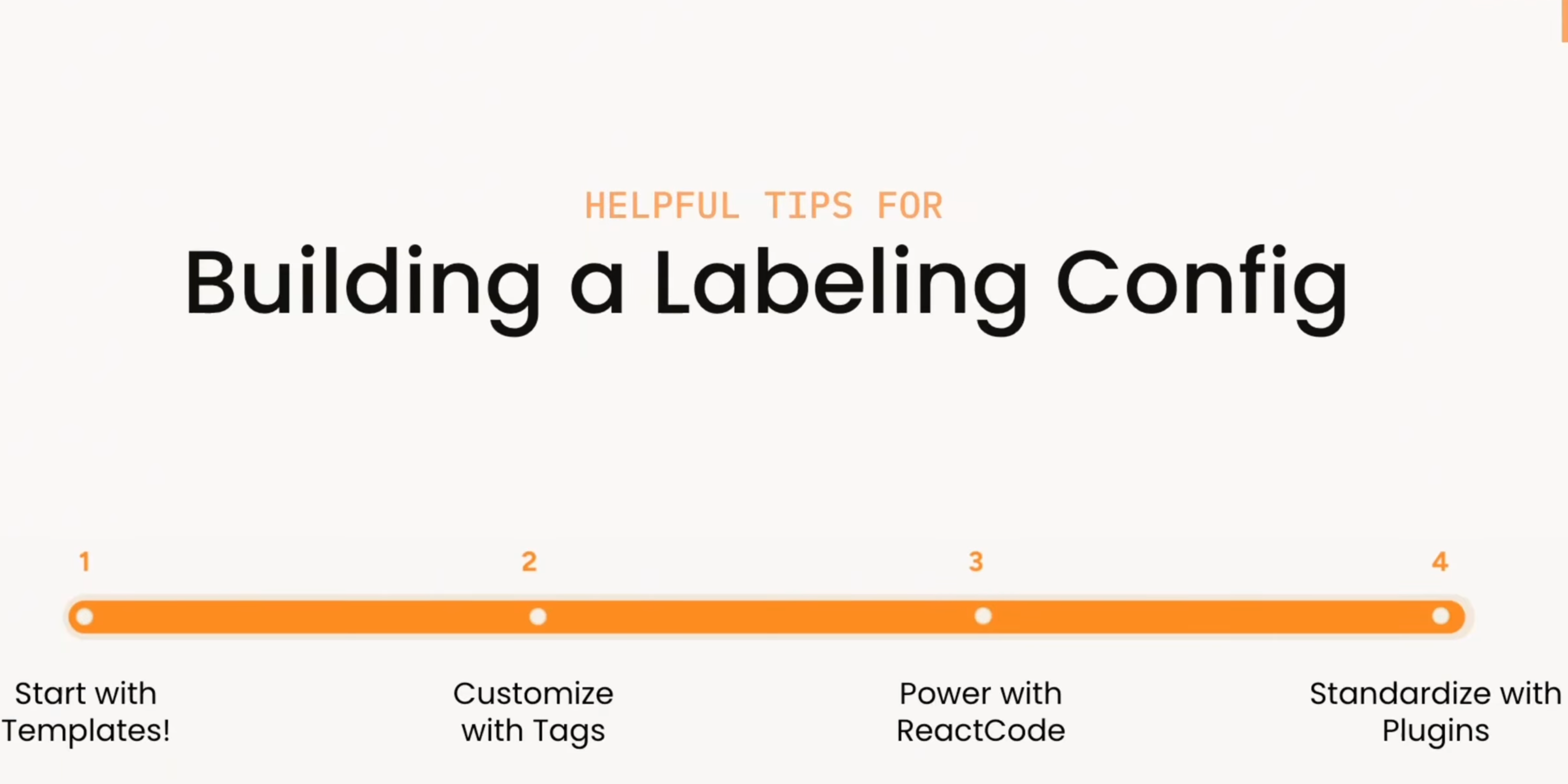
Building A Labeling Config in Label Studio Enterprise
How do you build the right labeling interface in Label Studio? This video walks through a practical progression: start with templates, customize with XML tags, extend with React Code, and standardize workflows with plugins.
-

Learn how to connect YOLO26 to a Label Studio project using the YOLO ML Backend so annotators can start from model predictions and focus on review and correction instead of drawing boxes from scratch.

Micaela Kaplan
February 12, 2026
-

Getting started with Label Studio
Everything you need to know about Label Studio to get started, from downloading and installing the tool to creating your first project, adding new members, and more!