How to Scale Evaluation for RAG and Agent Workflows
RAG assistants and agent workflows add a lot more moving parts to evaluate. A few years ago, you could read the final answer and get a decent sense of quality. Now the outcome is shaped by what context the system pulled in, what it missed, and what decisions it made along the way.
A response can read well even when behavior is unstable underneath. Issues often appear in production or after routine changes like prompt edits, retrieval updates, model swaps, or workflow adjustments. A repeatable evaluation setup keeps standards consistent across releases without depending on a single reviewer.
In this blog, we’ll walk through four building blocks that make a repeatable evaluation workflow possible: a rubric for consistent scoring, a ground truth set that anchors the standard, calibrated automated scoring to extend coverage, and disagreement review to keep everything aligned over time.
If you’d like more detail and real-world examples you can apply, download the full guide, Scaling Model Benchmarking for Enterprise AI
Rubrics make review consistent
In production, “good” usually includes more than correctness. Reviewers look for completeness, responsible handling of uncertainty, alignment with policy, and reasoning that makes sense in the domain.
A rubric captures those expectations in a way reviewers can apply consistently across tasks. Scored dimensions create structure, and comments can focus on the cases that need context, which makes the results easier to compare, diagnose, and connect back to fixes.
Rubrics also need to be usable at speed. A short set of clear dimensions applied consistently tends to produce cleaner signal than a long checklist that leaves room for interpretation, and you can expand the rubric later when specific failure patterns show up repeatedly.
A ground truth set anchors the standard
A rubric gives reviewers a shared set of criteria, but the rubric still needs an anchor that shows what “good” looks like in practice. A ground truth set provides that anchor. It’s a curated slice of tasks scored by subject matter experts with enough detail that other reviewers (and any automated judge) can follow the reasoning behind the score.
The set stays smaller than the full benchmark because it’s meant to be a reference point you can reuse over time, even when the rubric evolves or the reviewer pool changes. It also gives you a reliable basis for checking automated scoring, since you can measure where a judge aligns with expert judgment and where it needs refinement.
What to include in a strong ground truth set
- Representative tasks that reflect real decisions, including routine cases and high-risk edge cases
- Expert scores tied to the rubric, with short notes explaining the decision
- Coverage that exercises the rubric, so each dimension gets used in practice
- Version history, so updates don’t blur comparisons over time
- A subset reserved for calibration, used to test and validate any automated judge
Calibration keeps automation aligned
Automated scoring can expand evaluation coverage when it follows the same standard that human reviewers apply. Calibration connects the judge to your rubric and ground truth so scoring stays consistent as volume increases.
Run the judge on the ground truth set and compare its scores to expert scores across rubric dimensions. Focus your review on where it diverges, then use those cases to refine judge instructions, clarify rubric language, and define where automated scoring is appropriate.
What calibration produces
- A judge configuration aligned to the rubric (instructions and scoring format)
- An alignment check showing where judge scores match experts and where they don’t
- A list of weak spots (task types or rubric dimensions that trigger mis-scoring)
- Escalation rules for routing high-risk, ambiguous, or low-confidence outputs to experts
Disagreement review keeps standards consistent
Disagreements are valuable because they show exactly where the evaluation needs attention. When two reviewers score the same output differently, or when an automated judge doesn’t match expert judgment, the mismatch usually comes from a specific source: rubric language that allows multiple interpretations, tasks that don’t provide enough context, judge instructions that over-weight the wrong signal, or model behavior that falls outside what the benchmark currently covers.
A disagreement process turns those cases into improvements you can reuse. Route contested items to experts for adjudication, record the final decision with a short rationale, and use the outcome to refine the parts of the workflow that caused the mismatch. That can mean tightening rubric wording, rewriting or tagging ambiguous tasks, adjusting judge instructions, or adding a new task category when a failure pattern keeps showing up.
Over time, this keeps evaluation aligned with production reality. Standards stay consistent, benchmarks stay relevant, and automated scoring remains tied to the same criteria reviewers use.
The workflow at a glance
Below is a simple way to think about how each layer contributes to a scalable evaluation program.
| Layer | Purpose | Inputs | Outputs you can use |
| Rubric | Define “good” in a way reviewers can apply consistently | Criteria, examples, domain requirements | Structured scores, explainable decisions |
| Ground truth set | Anchor the standard and expose ambiguity early | Expert review on a focused task subset | Reference dataset for consistency checks and calibration |
| Calibrated automated scoring | Extend evaluation coverage where confidence is high | Ground truth set, rubric-aligned judge configuration | Scaled scoring plus confidence and escalation rules |
| Disagreement review | Keep standards stable and capture new failure modes | Low-confidence outputs, human vs judge conflicts, edge cases | Rubric refinements, new tasks, improved judge alignment |
| Versioning and reporting | Preserve interpretability across releases | Benchmark versions, model metadata, scoring outputs | Trend analysis, regression detection, release readiness reporting |
A workflow you can rerun after every change
RAG and agent workflows introduce failure modes that don’t show up in a quick read of the final output. With rubrics, a ground truth anchor, calibrated automated scoring, and disagreement review, evaluation becomes something you can rerun after prompt edits, model swaps, retrieval updates, and workflow changes without resetting the standard each time. That makes comparisons clearer, regressions easier to spot, and results easier to explain when stakeholders ask what changed and why.
Interested in putting this into practice in your environment? Contact our team here.
Related Content
-

The Five Stages to Keeping Benchmarks Useful as Models Evolve
A practical maturity model for taking benchmarks from proof-of-concept to versioned, continuously evolving evaluation that keeps up with models, prompts, and agent workflows.

HumanSignal Team
January 7, 2026
-
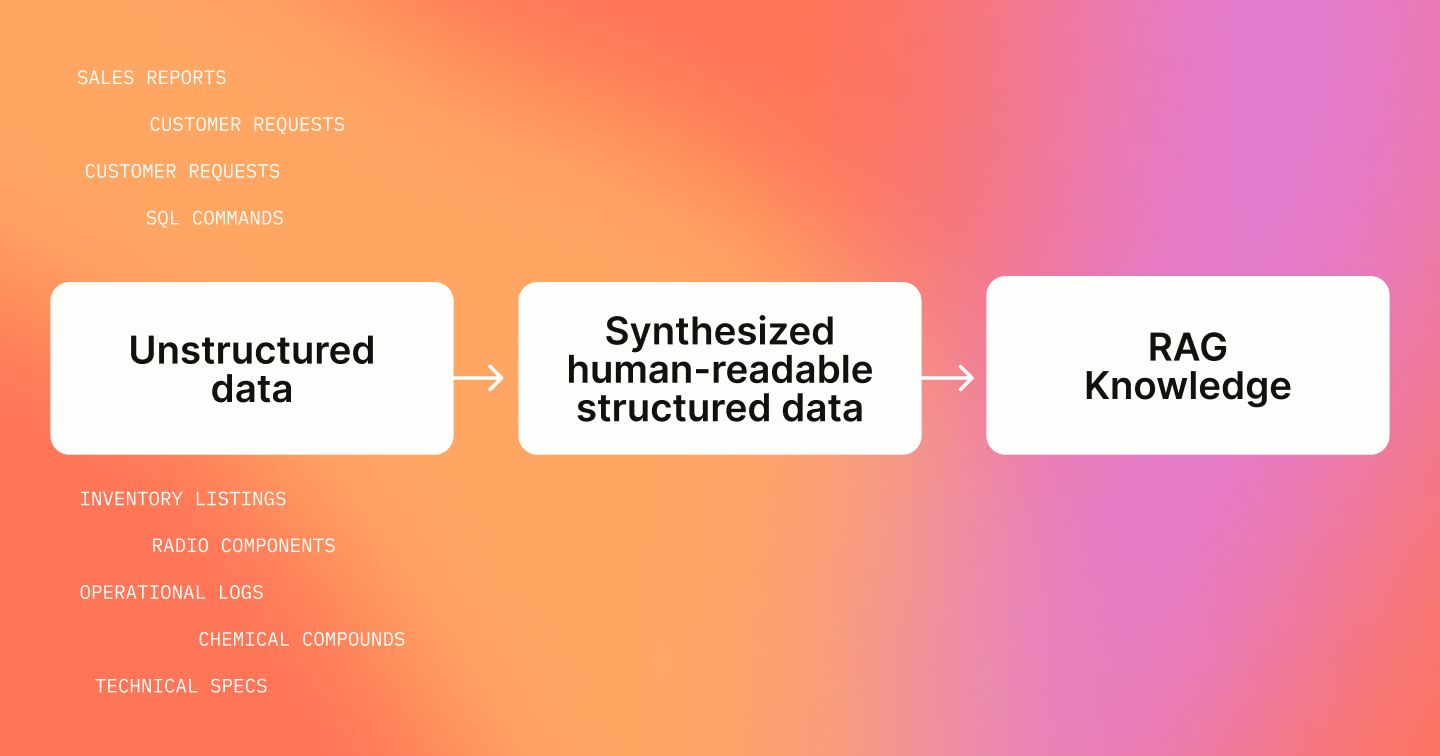
Building a RAG System with Label Studio
In this post, we share how we used Label Studio and its Prompts feature to break down tasks, synthesize QA pairs, and build a reliable RAG assistant.

Max Tkachenko
April 10, 2025