Intro to Hugging Face: A Valuable Directory of AI Models and Tools

Hugging Face is a highly esteemed platform widely recognized as one of the most valuable resources for discovering and utilizing Language Model (LLM) technology. Despite its somewhat amusing name (named after an emoji), Hugging Face has earned a solid reputation as a premier directory of AI models and tools. With its vast collection of pre-trained models that are readily available for fine-tuning, Hugging Face offers a comprehensive solution for AI practitioners and researchers alike.
Exploring the Model Hub
At the forefront of the AI landscape, Hugging Face's Model Hub is a repository with an impressive array of over 230,000 pre-trained models as of June 2023. These models encompass a wide range of cutting-edge solutions, including notable ones like FALCON, Alpaca, and FLAN, enabling users to access state-of-the-art resources to advance their AI applications.
Its user-friendly interface, designed to facilitate exploration and understanding of the models it hosts, sets Hugging Face apart. Each model featured on Hugging Face's platform comes with comprehensive information, allowing users to delve into the intricacies of each model's architecture, capabilities, and performance metrics. Crucial details such as model size, download count, and the last update date are provided, empowering users to make informed decisions when selecting the most suitable model for their specific requirements. You also can demo those models right from the Hugging Face website.
Why Fine-Tuning LLMs Is Essential
Out of the box, LLMs can handle general tasks fairly easily. But what do you do when you need to complete tasks that require more specialized knowledge than what LLMs typically have? You'll need to fine-tune the model by training it on your specific use case. This article is an excerpt from our ebook - The Essential Guide to Fine-Tuning LLMS. You can download the entire book here.
Navigating the Hugging Face Ecosystem
Powerful Filtering and Search Tools
Hugging Face offers robust filtering and sorting options, making navigating the extensive model catalog effortless. Users can refine their searches based on criteria such as model architecture, task domain, language support, or specific performance metrics. This streamlines the process of finding the optimal model that aligns with the user's desired functionalities and constraints.
Community Collaboration and Open Contributions
Furthermore, Hugging Face's platform fosters a vibrant community of AI enthusiasts and experts. The platform enables users to contribute to the ecosystem by sharing their own models and providing valuable feedback and insights on existing models. This collaborative environment fuels the constant evolution and refinement of the models hosted on the platform, ensuring that users have access to the latest advancements in AI research.
Tools for the Full AI Lifecycle
In addition to the Model Hub, Hugging Face also offers a comprehensive suite of tools and utilities to support the entire lifecycle of AI model development. These include easy-to-use libraries and frameworks that facilitate model training, fine-tuning, deployment, and evaluation. Hugging Face's ecosystem equips practitioners with the necessary resources to efficiently develop and deploy AI models in various real-world applications.
Spotlight on the LLM Leaderboard
One of the most helpful tools on Hugging Face is the LLM Leaderboard. The Open LLM Leaderboard is a platform designed to track, rank, and evaluate the performance of various Large Language Models (LLMs) and chatbots. This leaderboard provides an objective measure of the progress being made in the open-source community and helps identify the current state-of-the-art models.
One of the key features of this leaderboard is its openness to community contributions. Anyone can submit a model for automated evaluation, provided it is a Transformers model with weights on the Hub. The platform also supports evaluation of models with delta-weights for non-commercial licensed models, such as LLaMa.
The leaderboard evaluates models on two main fronts: LLM Benchmarks and Human and GPT-4 Evaluations.
- LLM Benchmarks assesses models on four key benchmarks:
- AI2 Reasoning Challenge (25-shot) - a set of grade-school science questions.
- HellaSwag (10-shot) - a test of commonsense inference, which is easy for humans (~95%) but challenging for SOTA models.
- MMLU (5-shot) - a test to measure a text model’s multitask accuracy. The test covers 57 tasks including elementary mathematics, US history, computer science, law, and more.
- TruthfulQA (0-shot) - a test to measure a model’s propensity to reproduce falsehoods commonly found online.
Benchmarks are chosen to test a variety of reasoning and general knowledge across a wide variety of fields in 0-shot and few-shot settings.
Human + GPT-4 Evaluation
Evaluations are conducted by engaging humans and GPT-4 to compare outputs from a selection of popular open-source Large Language Models (LLMs) based on a confidential set of instruction prompts. These prompts encompass tasks such as brainstorming, creative generation, commonsense reasoning, open-question answering, summarization, and code generation. Both human evaluators and a model rate the comparisons on a 1-8 Likert scale, with the evaluator required to express a preference each time. These preferences are then used to establish bootstrapped Elo rankings.
The collaboration with Scale AI facilitated the generation of completions using a professional data labeling workforce on their platform, adhering to the provided labeling instructions. GPT-4 was also utilized to label the completions using a specific prompt to gain insights into evaluating popular models.
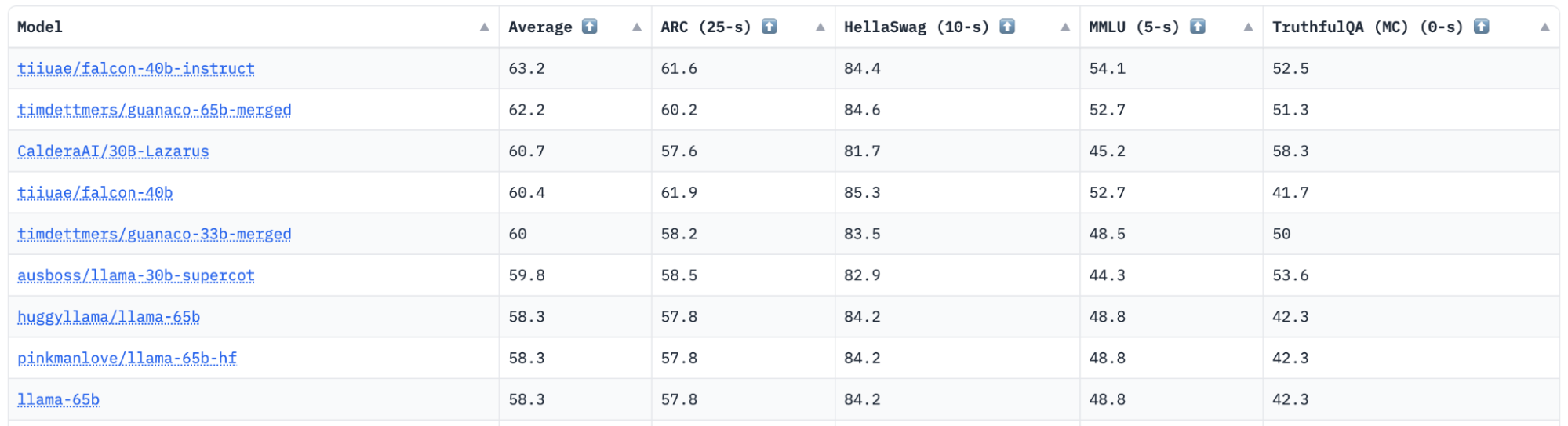
Hugging Face LLM Leaderboard
Hugging Face is an indispensable resource for the AI community, providing a robust and user-friendly platform for accessing a vast collection of pre-trained models. Its Model Hub, housing over 230,000 models, and its intuitive interface and powerful search capabilities empower users to effortlessly navigate and select the ideal model for their specific AI tasks. With its collaborative ecosystem and comprehensive suite of tools, Hugging Face remains at the forefront of AI research and development, supporting the advancement of state-of-the-art language models and fueling innovation in the field.
Related Content
-

The 5 Metrics That Actually Move AI Into Production
A practical framework for turning AI metrics into clearer decisions about what to fix, ship, and scale.

Sheree Zhang
April 15, 2026
-

Scaling AI Data Quality: Best Practices for Onboarding and Evaluating Annotators
A practical workflow for onboarding and evaluating annotators with clear instructions, calibration, quality gates, reviewer feedback, and dashboards that keep labeling consistent as volume grows.

Alec Harris
March 12, 2026
-

How to Create a Prompt Generator with Label Studio and RLVR
In this article, you'll learn how to apply an RLVR-based score verifier and use an LLM as a prompt optimizer to enhance your prompts.

Label Studio Team
March 2, 2026