New LLM Evaluation Templates For Label Studio
While Large Language Models (LLMs) are becoming increasingly popular, there's still a big gap to putting Generative AI applications into production without proper evaluation workflows. After all, how do you know the LLM is providing the output that you want or expect when your brand is on the line?
At HumanSignal, we've been deeply focused on evaluation as part of the Generative AI development lifecycle. We believe a combination of automated evaluations plus human-in-the-loop supervision is the most efficient and effective path to AI evaluation, and we recently released new features in our Enterprise platform that support automated Evals using the LLM-as-a-Judge methodology.
As part of this effort, we’ve also introduced five new LLM Evaluation templates for Label Studio to get you up and running with manual and even semi-automated evaluations. Each template in the documentation will outline the labeling config, task format expectations, and other necessary code samples to get you started. These templates are meant to help you evaluate an LLM that is running in another system by uploading the outputs of your LLM as tasks to Label Studio. You can always integrate these pieces together by leveraging our ML Backend, but we won’t cover that in this post.
For each template, you’ll follow the following steps:
- Create a Label Studio config that specifies the ways in which you want to moderate your content. You can find the example for this in the linked documentation.
- Use the config to create a new project. You can do this using our API! Follow the steps under Create a Project.
- Create a task. In the example documentation, we show you what the sample response moderation template is expecting for each task: a chat that shows a conversation between a user and an assistant. We also show you one way that you can generate this format using an LLM!
- Upload your task to your project. We provide instructions for uploading data in our documentation. Then, you can begin labeling!
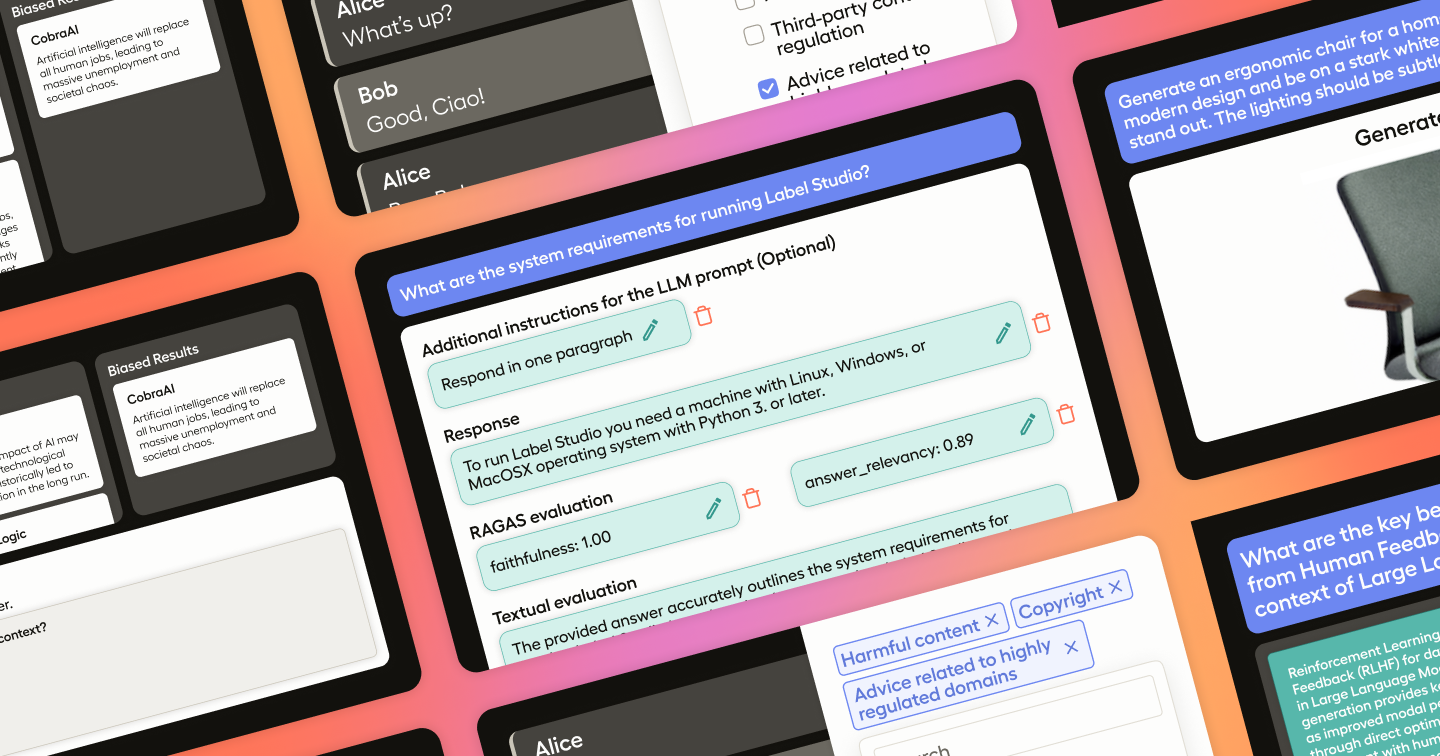
LLM Response Moderation
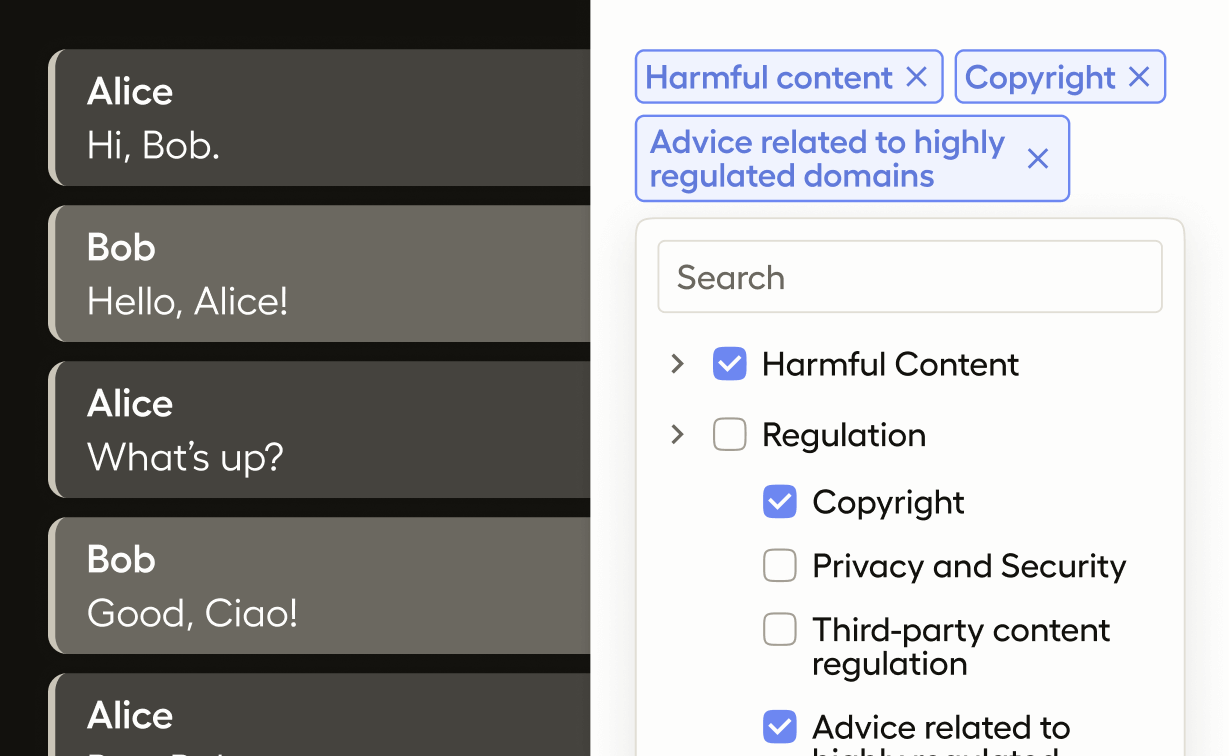
In general, a response moderation use case is one in which the goal is to classify the document provided as having some characteristics in a defined set. In this case, we’re concerned with whether the LLM output contains some form of harmful content, is in violation of some regulation, whether or not the model has hallucinated, as well as some other classifications such as accountability and quality of service. The basic idea with response moderation is that a human user will read the output of an LLM and then decide which, if any, of the provided classes are relevant to the sample. Content moderation is important when working with LLMs to ensure that no harm is caused by your model, and to catch problems before they occur so that the model can be finetuned or retrained as needed.
To do response moderation in Label Studio, you can follow the steps outlined in our documentation.
You could also moderate the output for other categories, simply by modifying the template!
LLM Response Grading

In other LLM use cases, the goal might be to assign a score on a scale to an LM response based on the quality of generated text. This scale will usually encompass many aspects of LLM output, including factual accuracy, relevance, style, and completeness. In this example, we use a five-star scale to indicate how good an LLM response really is. Grading can be a useful tool when trying to decide how well a model performs on average, or across different types of data.
To do response grading in Label Studio, you can follow the steps outlined in our documentation.
Side-by-Side LLM Output Comparison

A more complicated case of evaluating LLMs comes when you want to compare multiple models. How do you know which model provides a better answer to the same prompt?
In this template, we’ll show you how to populate the Label Studio tool with the outputs of each of the models you want to compare so that you can click on whichever answer is better. This allows you to not only decide which model performed better, but also to gather helpful data on the outputs of the various models that can be used for various purposes downstream.
To do this side-by-side comparison in Label Studio, you can follow the steps outlined in our documentation.
Evaluate RAG with Human Feedback
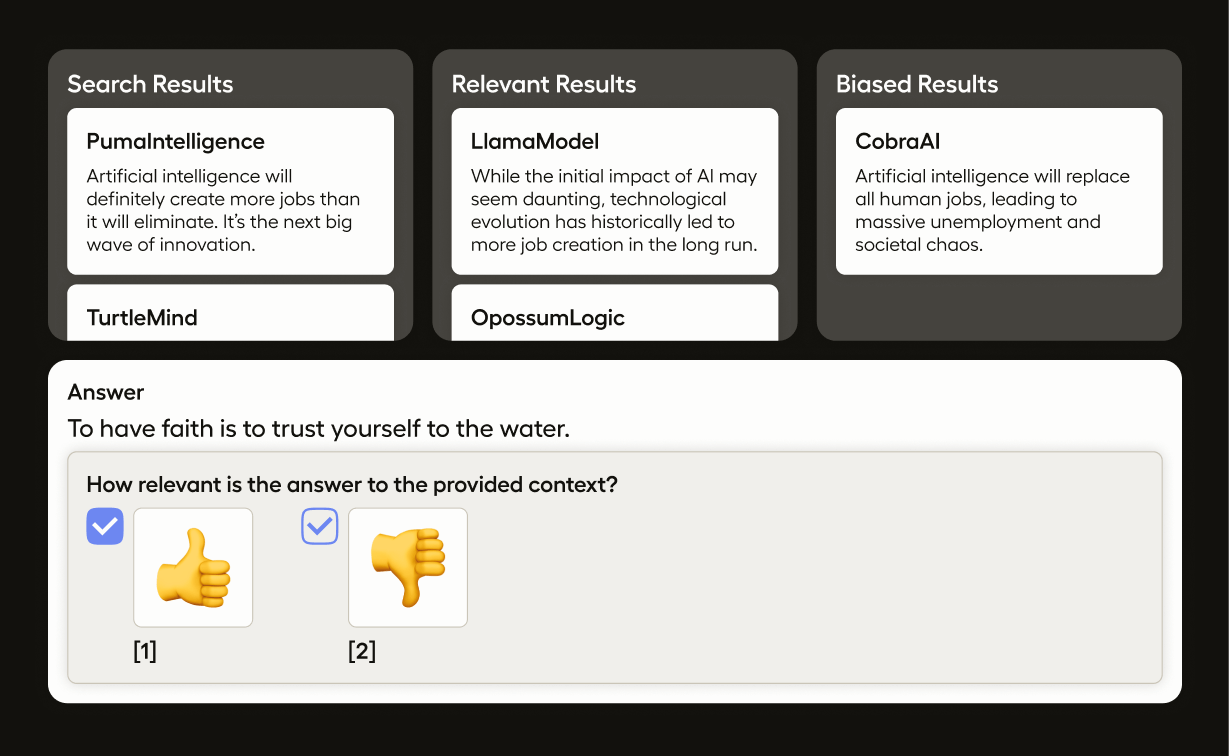
RAG pipelines provide an interesting use case for the evaluation of LLMs because you’ll need to evaluate multiple steps in the pipeline instead of just the output. Our configuration template aims to evaluate the contextual relevance of the retrieved documents, as well as the relevancy and faithfulness of the answer itself. Evaluating each piece of the RAG pipeline separately but on one page allows you to streamline your annotation review process and get a better understanding of how the whole pipeline works end to end.
To evaluate your RAG pipeline in Label Studio, you can follow the steps outlined in our documentation.
Evaluate RAG with Ragas
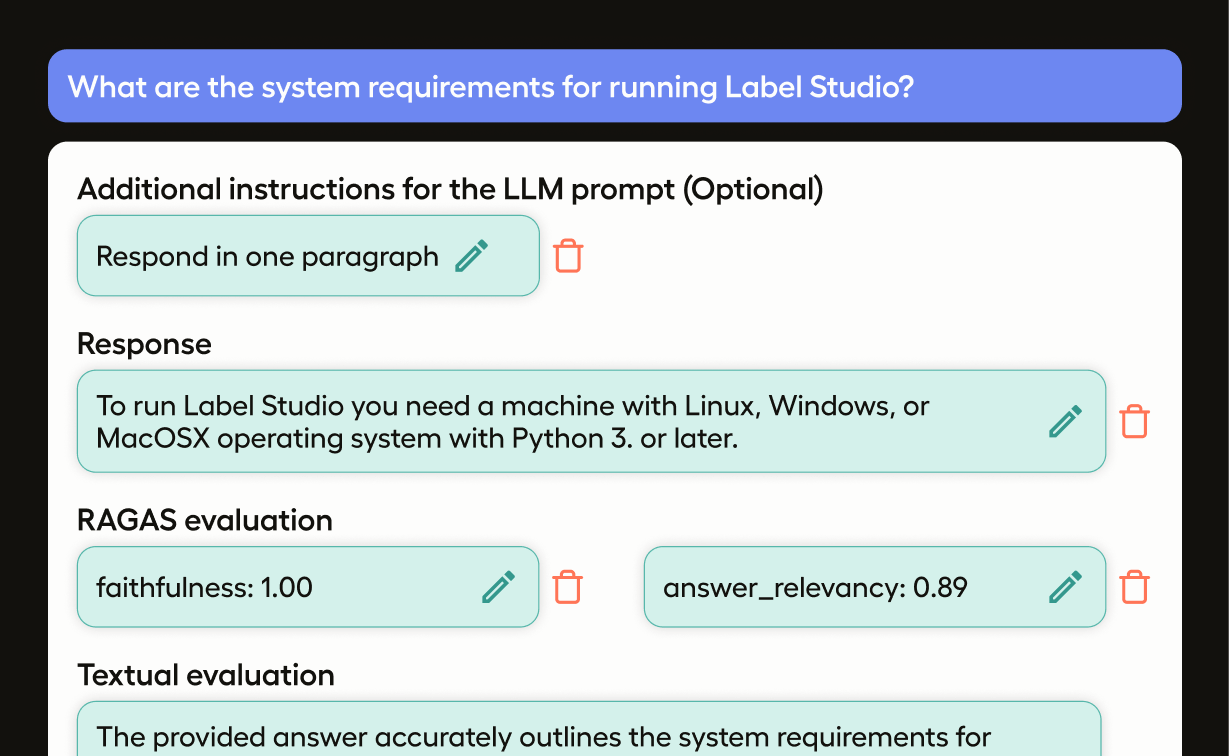
Ragas is a popular framework for evaluating RAG Pipelines. For each component of your pipeline, Ragas offers metrics that can help you understand how your pipeline is performing, such as faithfulness and relevancy of the LLM response given the context, or the precision and recall of the retrieved documents.
In this template, alongside the corresponding ML Backend example, we’ll help you set up a labeling project that, given some data and a prompt, will automatically generate the LLM response and the Ragas metrics for the response and populate it into your Label Studio UI, making evaluation easy.
We hope you find these new templates to be helpful. As always, you can check out our entire library of templates to help you with an array of use cases.
Happy labeling!
Related Content
-
Vibe Code Any Labeling or Evaluation Interface with Label Studio Enterprise
Now you can have the speed and flexibility of coding agents with the powerful backend of Label Studio Enterprise.

HumanSignal Team
June 10, 2026
-
Building the New Human Evaluation Layer for AI and Agentic systems
Programmable. Embeddable. Multimodal. Meet the new evaluation engine powering custom interfaces for AI and agentic systems.

Michael Malyuk
January 14, 2026
-

Label Studio Wrapped 2025: Inside the Workflows Powering Today’s AI Teams
See how Label Studio evolved in 2025 to support richer labeling, measurable quality, and deeper analytics for real-world AI systems.

Label Studio Team
December 11, 2025