Getting Started with Sentiment Analysis

You want to know how your customers are feeling. But asking each and every one, “Hey, how are you feeling?” might not be feasible. With sentiment analysis, you can figure out how your customers feel about your business in a scalable data-driven way.
What is sentiment analysis?
Sentiment analysis is a form of natural language processing. Here, the program is specifically processing the data it's given to determine the mood of the conversation. Its goal is to not just understand what’s happening in the conversation, but to report back to you what the mood of that conversation is.
Let’s say a customer writes in, saying “I want to double up on my order of laundry detergent. I love that formula and so does my entire family!”
Your program should know that the customer wants to modify their existing order. But, if it’s running sentiment analysis, the program should also flag the response as a positive interaction.
There are different ways to score the tenor of a conversation. Some sentiment analysis programs use a numerical scale from 0 to 10 to categorize conversations, with 0 indicating a negative conversation, and 10 indicating a positive one.
Other programs assign more nuanced descriptors of conversations using words like “amicable”, “angry” “enthused” and others to segment conversations into discrete groups that reflect the nuance of the conversation itself.
An average sentiment analysis program might field or digest thousands of customer conversations and then report on the state of customer satisfaction.
With both a bird’s eye view of customer interactions, and a deeply high resolution view as well, your sentiment analysis program can unlock new data-driven learnings about customer satisfaction that you couldn’t have discovered without it.
There are a couple of other concepts it’s helpful to know about to understand sentiment analysis:
Machine Learning
This is the proverbial training ground where the program learns to make sense of customer conversations – you provide your program a set of data to work from.
Researchers training machine models have used Amazon reviews, movie reviews, and other types of large indexes of customer feedback data to teach their programs what positive, ambivalent, and negative sentiment
To start, you need to tell your novice program what a positive review looks like. It might contain words like, “awesome”, “satisfied”, “great” and other adjectives that should be tagged by your program as indicators of positive sentiment. As you train the model against more datasets and dial in its categorization, it will become more proficient at understanding the tenor of a conversation.
Natural Language Processing
When your program is reading customer responses and replying to them — that’s natural language processing. This describes the ability of a program to understand text and speech it's given, make sense of it, and reply in kind or take some sort of action on that input.
In this state, your program has moved from the training grounds where you fed it data sets and corrected its assumptions, to a real life production environment in which it’s taking in conversations on its own and making sense of them.
How to label data for sentiment analysis
A successful sentiment analysis program follows key stages or data processing.
- Data collection
- Pre-processing
- Vectorization
- Visualization
Data Collection
This first stage refers to a program taking in a dataset. That might be an uploaded, massive CSV file of information or simply making sure the pipeline of information running from a company’s automated survey database is flowing to the program being used to register its overall sentiment.
The first type of data collection, the one in which a developer uploads an archive of data, is manual data collection. Here, the sentiment analysis program is fed data at specific moments based on the discretion of the developer that built it or the company that’s running it.
The second type of data collection, in which a program is connected to a database or API that’s automatically and always feeding it information, is automated data collection. In this environment, the sentiment analysis program is constantly receiving more information it can use to train itself to be more accurate.
Pre-Processing
Humans don’t make life easy for computers. We might spell things incorrectly, use uppercase text when we shouldn’t, forget a letter here or there, or use numbers instead of letters. These mistakes might be easy for a human to fix, but they’re difficult for a computer to take action on until they’re corrected.
So, if a customer who needs a new collared shirt from your luxury fashion brand writes into your live chat system and says “DoeS any1 have another Shirt I can order?” The average human will read that, shudder a bit, but still understand what the customer is asking for.
The average sentiment analysis program can’t make sense of that gnarled text. So, in pre-processing you can normalize text, correcting casing issues and incorrectly used numbers. Now, the sentence we initially received “DoeS any1 have another Shirt I can order?” becomes “Does anyone have another shirt I can order?” That second sentence is much more digestible and actionable for your program. But, an even better pre-processing change is “does anyone have another shirt I can order.” By lowercasing the string of text the program receives, we avoid the problem of your program treating “Does” differently than “does,” even though they’re the same word. This distinction is even more important once we start converting words to numerical data.
Vectorization
In every word, there’s an ocean of context. Take a word like “commit,” that should be familiar to any developer. That word comes from the latin roots of “com” meaning with, and “mittere” meaning to put or send. The word itself might be used to describe a spouse’s devotion to their partner. Or, it might be used to detail what crime someone has committed. Programs don’t have the time or bandwidth to parse through all that context.
Vectorization is the process of taking text, assigning it a numerical tag, and organizing those numerical tags into distinct camps. You might use a binary system to categorize text, or employ a more context-aware vectorization strategy. In any case, your program will keep the meaning behind the words it's analyzing, but assemble them in vectors that are much easier for it to take action on.
Visualization
Your program has vectors that make it easy for it to parse information. But, what about you, the human, actually reading that information? That’s where visualization comes in. Using visualization tools, APIs, and software, you can port data from your program to that third-party tool to see the lesson behind your data.
Here, you might see that the word “cracked” is associated with the majority of negative conversations. If you’re an electric bicycle company shipping products out to customers, like to Vanmoof, you might want to dive into that. Maybe you discover that your bikes are being damaged in shipping and come up with an ingenious idea to ship your high-end bikes in boxes that look like they contain flat screen TVs so shippers are more careful with those bikes. The possibilities are all there, in the data brought to the surface by your visualizer.
Decisions to make before labeling data for process analysis
Before building your sentiment analysis model, there are a few decisions you’ll want to make about what the model is for, and how it will work.
- Lexicon: The dataset you use to train your sentiment analysis program will define your sentiment analysis. Having your NLP model trained against tweets will familiarize it in that lexicon. That’s a different lexicon than training your NLP model against Shakespearean verse. If you’re analyzing tweets, great. But, if your customers’ language looks less colloquial and more refined, you should pick a dataset that reflects their dialect.
- Granularity: If you’re just trying to determine if a customer is happy or sad, that’s one thing. If you’re trying to figure out if a customer’s review means their disgruntled, disappointed, enthused, excited, optimistic, stoic, or neutral, that’s an entirely different thing.
- Updates: If you’re storing data in a static environment, the onus is on you to push updated data to your program. If you’re storing your data in a dynamic environment, and particularly in the cloud, it’s much easier to continuously pipe data to your application so it stays up to date.
- Reviews: To make sure your app is performing well, you should select a series of reviewers who can make sure that your program is accurately classifying and analyzing text and other forms of data. These people can also help annotate that data as well to ensure your program is crossing its ts and dotting its is. This is where you can also employ NLP and ML frameworks to give your program a head start.
How Label Studio can help
A successful sentiment analysis program has two major components.
First, there’s the software – what libraries will you use to analyze and catalog your data, and ultimately run your model? There are lots of options out there. Pattern, TextBlob, or NLTK, for example, are great places to start, particularly if you’re a Python programmer.
But then there’s the dataset and model. After you’ve sourced your training data – whether that’s Tweets, airplane arrivals, customer service interactions, or something else altogether – you’ll need to efficiently label that data so that your model can be trained accurately.
Label Studio is a data labeling platform that can be used for annotating large datasets consisting of all data types, including text (natural language processing, documents, chatbots, transcripts, and more). Use cases include document classification, named entity recognition, question answering and sentiment analysis.
To get started, install the open source Label Studio platform, connect your data source, add your team members, and set up your labeling interface (using pre-built templates or by creating custom layouts). You can also connect your machine learning models to semi-automate the labeling and focus your team’s effort on the most nebulous or complex tasks.
Related Content
-
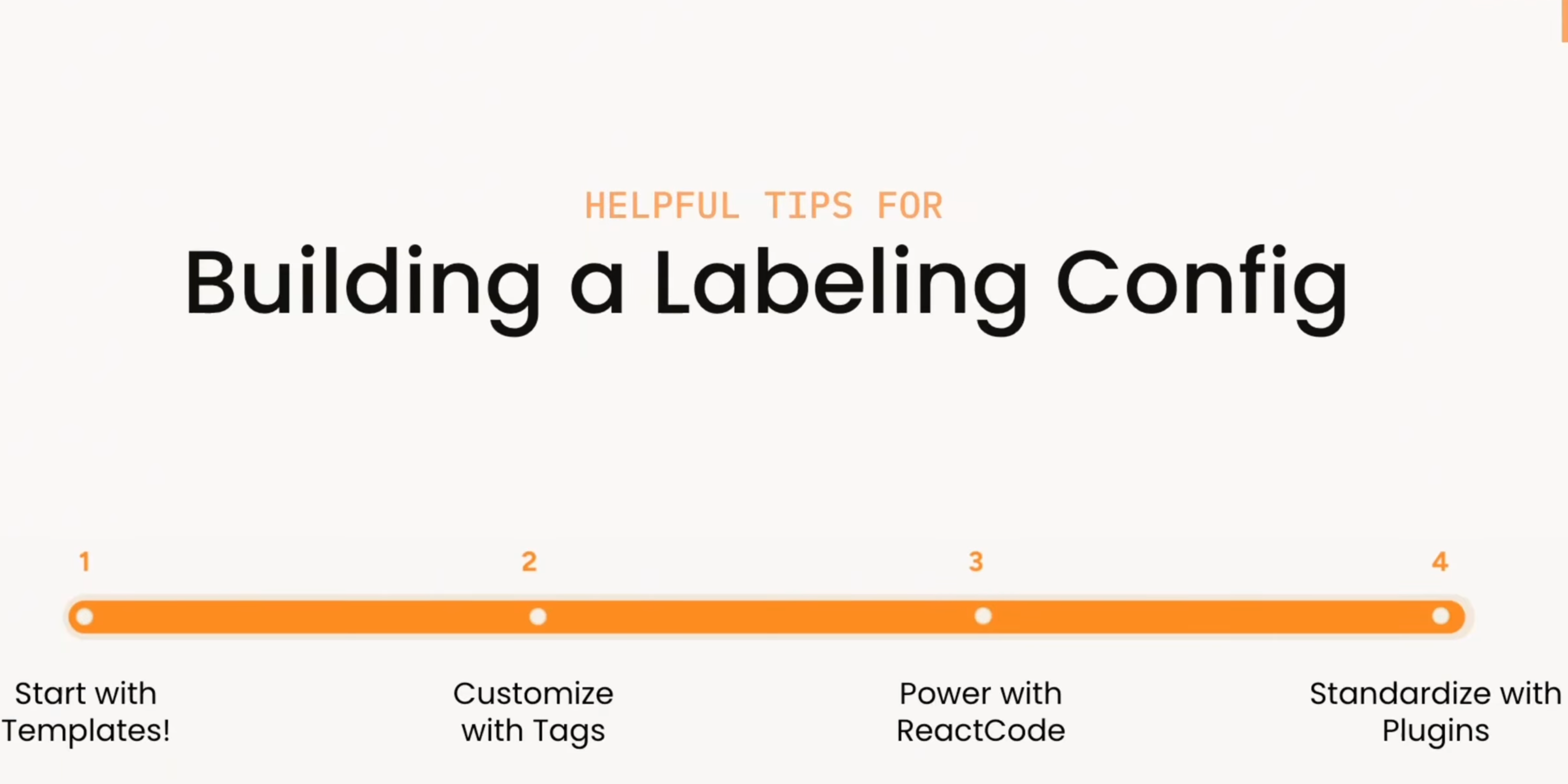
Building A Labeling Config in Label Studio Enterprise
How do you build the right labeling interface in Label Studio? This video walks through a practical progression: start with templates, customize with XML tags, extend with React Code, and standardize workflows with plugins.
-

Learn how to connect YOLO26 to a Label Studio project using the YOLO ML Backend so annotators can start from model predictions and focus on review and correction instead of drawing boxes from scratch.

Micaela Kaplan
February 12, 2026
-

Getting started with Label Studio
Everything you need to know about Label Studio to get started, from downloading and installing the tool to creating your first project, adding new members, and more!