How to Review LangSmith Traces with Label Studio

0. Label Studio Requirements
This tutorial uses ReactCode templates, a feature available in Label Studio Enterprise only. ReactCode allows you to build fully custom React-based annotation interfaces — in this case, a 3-panel trace review UI. We recommend connecting with our team to request a trial or to enable them in your account.
After section 2, you will need a running Label Studio Enterprise instance and an API key from your account settings.
1. Installation & Setup
First, install the required dependencies:
!pip -q install requests label-studio-sdk python-dotenv langsmith langchain langchain-anthropic anthropicEnvironment Configuration
Create a .env file in the repository root (or the same directory as this notebook) with the following variables:
# Label Studio Enterprise
LABEL_STUDIO_HOST=http://localhost:8080 # or your LS Enterprise instance URL
LABEL_STUDIO_API_KEY=your_label_studio_api_key
# LangSmith
LANGSMITH_API_KEY=your_langsmith_api_key
LANGSMITH_PROJECT=your_project_name # project name for tracing and fetching
LANGSMITH_ENDPOINT=https://api.smith.langchain.com
# Anthropic (only needed for Section 3a sample trace generation)
ANTHROPIC_API_KEY=your_anthropic_api_keyLangSmith Setup: Visit LangSmith Documentation to create an account, get your API key, and set up a project.
Label Studio Setup: Visit Label Studio Documentation for installation instructions and how to generate an API token from your account settings.
import os
from dotenv import load_dotenv
load_dotenv(override=True)
load_dotenv(os.path.join(os.path.dirname(os.getcwd()), '.env'), override=True)
# Label Studio Enterprise
LABEL_STUDIO_HOST = os.getenv('LABEL_STUDIO_HOST', 'http://localhost:8080')
LABEL_STUDIO_API_KEY = os.getenv('LABEL_STUDIO_API_KEY', '')
# LangSmith
LANGSMITH_API_KEY = os.getenv('LANGSMITH_API_KEY', '')
LANGSMITH_PROJECT = os.getenv('LANGSMITH_PROJECT', '')
LANGSMITH_ENDPOINT = os.getenv('LANGSMITH_ENDPOINT', 'https://api.smith.langchain.com')
# Enable LangSmith tracing for LangChain/LangGraph (auto-instrumentation)
os.environ['LANGSMITH_TRACING'] = 'true'
# Anthropic (only needed for sample trace generation in Section 3a)
ANTHROPIC_API_KEY = os.getenv('ANTHROPIC_API_KEY', '')
print('LABEL_STUDIO_HOST:', LABEL_STUDIO_HOST)
print('LANGSMITH_PROJECT:', LANGSMITH_PROJECT or '(not set)')
print('LANGSMITH_ENDPOINT:', LANGSMITH_ENDPOINT)
print('Has LABEL_STUDIO_API_KEY?', bool(LABEL_STUDIO_API_KEY))
print('Has LANGSMITH_API_KEY?', bool(LANGSMITH_API_KEY))
print('Has ANTHROPIC_API_KEY?', bool(ANTHROPIC_API_KEY))Setup: The Evaluation Pipeline
This tutorial connects LangSmith’s engineering-centric observability tooling with Label Studio’s expert evaluation interface:
Step 1: Trace Collection in LangSmith
- LangSmith auto-instruments all LangChain/LangGraph calls when
LANGSMITH_TRACING=true— no manual callbacks needed - Engineer-centric interface for technical debugging and iteration
- Hierarchical run storage: each trace is a tree of typed runs (
llm,tool,chain)
Step 2: Expert Evaluation in Label Studio
- Import traces from LangSmith into Label Studio as structured annotation tasks
- Domain experts evaluate each turn using the custom ReactCode UI
- Collaborative workflow: multiple SMEs can annotate the same traces
- Structured output feeds directly into quality reports, prompt improvements, and LLM-as-a-judge pipelines
2. Label Studio ReactCode Config
Skip the setup — clone the project directly
The pre-configured project below includes the full 3-panel ReactCode annotation interface ready to use. Click the button to clone it into your Label Studio Enterprise account and jump straight to importing your LangSmith traces in Section 4.
If you prefer to configure the project programmatically, follow the rest of this section.
This tutorial uses a ReactCode label configuration — a Label Studio Enterprise feature that lets you embed a custom React component as your annotation interface.
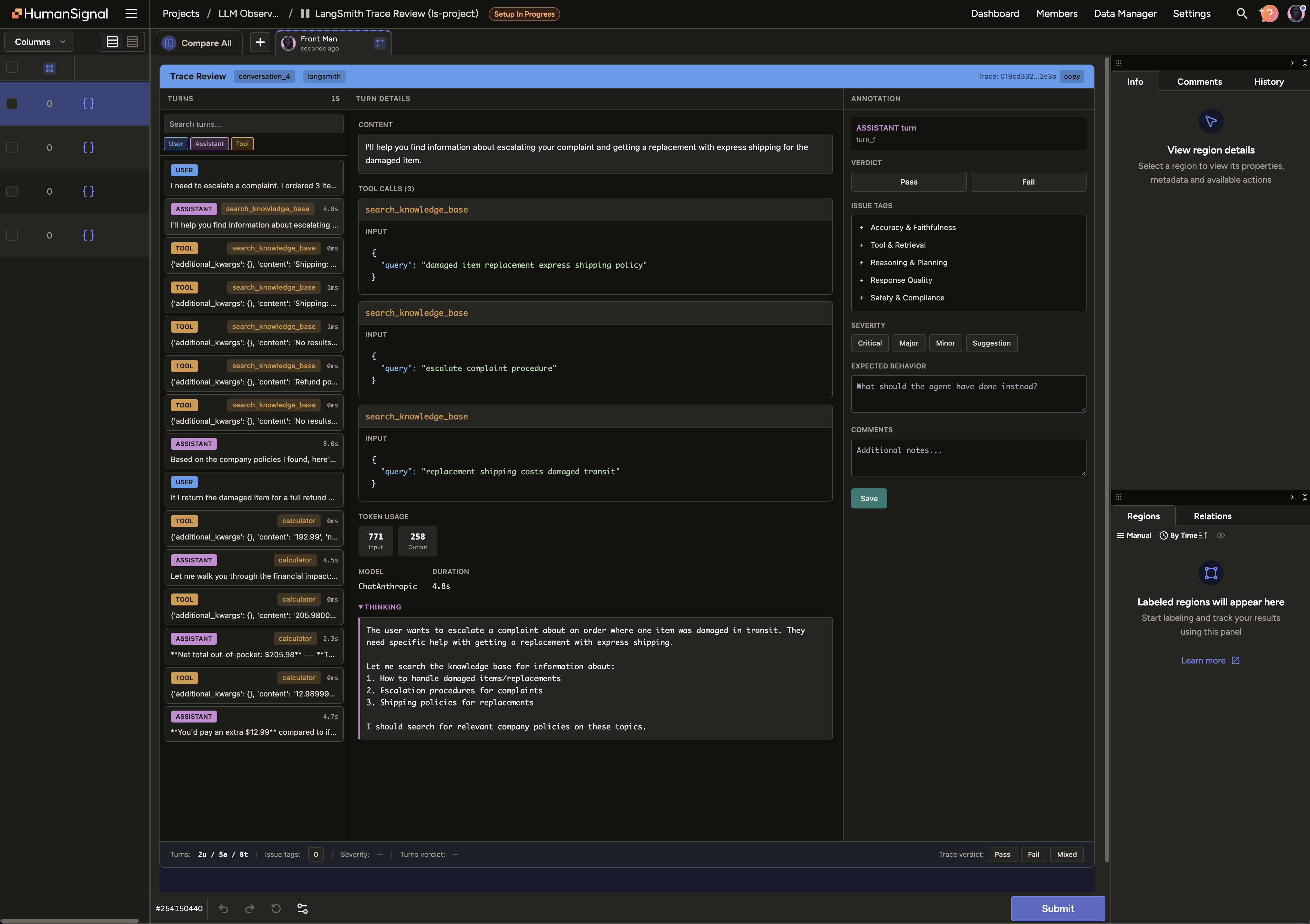
The UI has three panels:
| Panel | Purpose |
|---|---|
| Turns (left) | Scrollable list of all turns. Filter by role, search by content. Each card shows role, tool badges, latency, and verdict once annotated. |
| Turn Details (center) | Full content, tool call inputs/outputs, token usage, latency, and Claude’s extended thinking (when present). |
| Annotation (right) | Structured form for evaluating each turn — see annotation model below. |
Annotation model — what you capture per turn:
- Verdict — Pass or Fail
- Issue tags — taxonomy across 5 categories: Accuracy & Faithfulness, Tool & Retrieval, Reasoning & Planning, Response Quality, Safety & Compliance
- Severity — Critical / Major / Minor / Suggestion
- Expected behavior — free text: what should the agent have done instead?
- Comments — any additional notes
A trace-level verdict (Pass / Fail / Mixed) in the bottom bar captures overall conversation quality, independent of individual turn verdicts.
# ReactCode 3-panel trace annotation config (self-contained — no external files needed)
# The full ~40KB React component is inlined as _TEMPLATE_JS (see notebook for complete code).
_TEMPLATE_JS = r"""function TraceAnnotator({ React, addRegion, regions, data }) {
// 736-line React component defining the 3-panel trace review UI.
// Panels: Turns list (left) | Turn details (center) | Annotation form (right)
// Bottom bar: turn statistics + trace-level verdict (Pass / Fail / Mixed)
// ... see notebook for the full implementation ...
}"""
LABEL_CONFIG_XML = (
'<View>\n'
' <ReactCode style="height: 95vh" name="trace" toName="trace"'
' outputs=\'{"trace_id":"string","turn_id":"string","turn_role":"string",'
'"verdict":"string","failure_modes":"array","severity":"string",'
'"expected_behavior":"string","comments":"string"}\'>\n'
' <![CDATA[\n '
) + _TEMPLATE_JS + (
'\n ]]>\n'
' </ReactCode>\n'
'</View>'
)
print(LABEL_CONFIG_XML[:300] + '\n...')3. Generate Sample Traces (Optional)
If you already have traces in LangSmith, skip this section — set GENERATE_TRACES = False and go directly to Section 4.
Otherwise, this cell creates a ReAct agent with multiple tools and runs 4 multi-turn conversations using Claude with extended thinking to produce realistic traces in your LangSmith project. Requires ANTHROPIC_API_KEY.
Extended thinking lets Claude reason through complex, ambiguous problems step-by-step before responding. The thinking content is captured in the trace and visible in the Label Studio UI.
LangSmith auto-instruments all LangChain/LangGraph calls when LANGSMITH_TRACING=true is set — no callback handler needed.
GENERATE_TRACES = True # Set to False if you already have traces in LangSmith
if GENERATE_TRACES:
from langsmith import traceable
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage
from langchain_anthropic import ChatAnthropic
from langchain.agents import create_agent
if not ANTHROPIC_API_KEY:
raise RuntimeError('ANTHROPIC_API_KEY is required. Set it in your .env or set GENERATE_TRACES=False.')
if not LANGSMITH_PROJECT:
raise RuntimeError('LANGSMITH_PROJECT is required. Set it in your .env file.')
@tool
def calculator(expression: str) -> str:
"""Evaluate a math expression."""
try:
return str(eval(expression))
except Exception as e:
return f"Error: {e}"
@tool
def search_knowledge_base(query: str) -> str:
"""Search an internal knowledge base for company policies, products, or procedures."""
kb = {
"refund": "Refund policy: Full refund within 30 days. After 30 days, store credit only. Damaged items: full refund at any time with photo evidence.",
"shipping": "Standard (5-7 days, free over $50), Express (2-3 days, $12.99), Overnight ($24.99).",
"warranty": "1-year limited warranty. 2-year extended warranty available for $29.99.",
"pricing": "Base $99/mo (10 users), Pro $249/mo (50 users), Enterprise custom. Annual billing saves 20%.",
}
results = [v for k, v in kb.items() if k in query.lower()]
return results[0] if results else f"No results found for: {query}"
@tool
def get_weather(city: str) -> str:
"""Get current weather for a city."""
weather_data = {
"new york": "New York: 72°F, Partly Cloudy, Humidity 65%, Wind 8 mph SW",
"london": "London: 58°F, Overcast, Humidity 80%, Wind 12 mph W",
"tokyo": "Tokyo: 82°F, Clear, Humidity 55%, Wind 5 mph NE",
"paris": "Paris: 63°F, Light Rain, Humidity 75%, Wind 10 mph NW",
}
return weather_data.get(city.lower(), f"Weather data not available for {city}")
# Claude with extended thinking — produces richer traces that surface the model's reasoning
llm = ChatAnthropic(
model='claude-sonnet-4-5-20250929',
max_tokens=16000,
thinking={'type': 'enabled', 'budget_tokens': 5000},
)
agent = create_agent(llm, [calculator, search_knowledge_base, get_weather])
# 4 multi-turn conversations designed to elicit extended thinking
conversations = [
["I bought a product 37 days ago with a manufacturing defect and an extended warranty. What are all my options?",
"The item costs $289. Can I use store credit toward a new extended warranty while keeping the original warranty claim open?"],
["We have 60 employees — 40 need full access, 20 need read-only. How do we minimize cost?",
"If we commit to annual billing and add 15 more full-access users next quarter, what's our 12-month total?"],
["I'm planning a 20-person client retreat. Compare Tokyo, London, and New York on weather and logistics.",
"12 attendees are in New York, 8 in London. Re-evaluate the three options for minimal travel disruption."],
["I ordered 3 items for $180 with express shipping. One arrived damaged — I need a replacement urgently.",
"If I return the damaged item and pay for express shipping on the replacement, what's my net out-of-pocket?"],
]
# LangSmith auto-instruments the agent via LANGSMITH_TRACING=true — no explicit decorator needed
for i, conv_messages in enumerate(conversations, 1):
print(f"\n--- Conversation {i} ---")
chat_history = []
for msg_text in conv_messages:
print(f" User: {msg_text[:80]}...")
chat_history.append(HumanMessage(content=msg_text))
result = agent.invoke({'messages': chat_history})
chat_history = result['messages']
reply = result['messages'][-1].content
if isinstance(reply, list):
reply = ' '.join(b.get('text', '') for b in reply if isinstance(b, dict) and b.get('type') == 'text')
print(f" Assistant: {str(reply)[:100]}...")
print(f'\n✓ Generated {len(conversations)} traces. Proceed to Section 4.')
else:
print('Skipped trace generation. Proceed to Section 4.')4. LangSmith Client
Uses the langsmith SDK to fetch traces (runs) from your project. LangSmith runs are hierarchical — each trace is a tree of runs sharing the same trace_id.
from langsmith import Client
from typing import Any, Dict, List
if not LANGSMITH_API_KEY:
raise RuntimeError('Missing LANGSMITH_API_KEY — set it in your .env file.')
if not LANGSMITH_PROJECT:
raise RuntimeError('Missing LANGSMITH_PROJECT — set it in your .env file.')
ls_client = Client(api_key=LANGSMITH_API_KEY, api_url=LANGSMITH_ENDPOINT)
print(f'LangSmith client ready — project: {LANGSMITH_PROJECT}')5. Normalize LangSmith Traces → Unified Schema
LangSmith stores traces as a hierarchy of typed runs (llm, tool, chain). This cell flattens that tree into a flat sequence of turns — the same schema used by all three platform integrations — so the ReactCode UI doesn’t need to know which platform the trace came from.
Each turn carries: role, content, tool_name, tool_input, tool_calls, model, usage (token counts), duration_ms, and thinking (Claude extended thinking blocks, when present).
import json as _json
def _to_str(x):
if x is None: return ''
if isinstance(x, str): return x
try: return _json.dumps(x, indent=2, default=str)
except: return str(x)
def _extract_content(obj):
if obj is None: return ''
if isinstance(obj, str): return obj
if isinstance(obj, dict):
for key in ('content', 'text', 'input', 'output', 'result'):
if isinstance(obj.get(key), str) and obj[key].strip():
return obj[key]
return _to_str(obj)
if isinstance(obj, list):
parts = [_extract_content(item) for item in obj if _extract_content(item).strip()]
return '\n'.join(parts) if parts else _to_str(obj)
return str(obj)
def _duration_ms(start_str, end_str):
if not start_str or not end_str: return None
try:
from datetime import datetime
def _parse(s): return datetime.fromisoformat(str(s).replace('Z', '+00:00'))
return int((_parse(end_str) - _parse(start_str)).total_seconds() * 1000)
except: return None
def _split_thinking(content):
"""Split Anthropic extended-thinking content blocks into (text, thinking)."""
if isinstance(content, str): return content, None
if isinstance(content, list):
text_parts, thinking_parts = [], []
for block in content:
if isinstance(block, dict):
if block.get('type') == 'thinking': thinking_parts.append(block.get('thinking', ''))
elif block.get('type') == 'text': text_parts.append(block.get('text', ''))
elif isinstance(block, str): text_parts.append(block)
return '\n\n'.join(text_parts), '\n\n'.join(thinking_parts) or None
return str(content) if content else '', None
def normalize_langsmith_trace(root_run, all_runs):
"""Convert LangSmith runs into the unified trace schema.
Run hierarchy (LangGraph + auto-instrumentation):
conversation_N (root, run_type=chain)
└── LangGraph (run_type=chain)
├── agent (run_type=chain)
│ └── ChatAnthropic (run_type=llm) ← LLM input/output
├── tools (run_type=chain)
│ └── search_knowledge_base (run_type=tool)
...
Strategy:
- run_type=llm → extract user messages from inputs + assistant response from outputs
- run_type=tool → extract tool execution as a tool turn
- run_type=chain → skip (structural wrappers)
"""
trace_id = str(root_run.get('trace_id') or root_run.get('id', ''))
runs_sorted = sorted(all_runs, key=lambda r: str(r.get('start_time') or r.get('dotted_order') or ''))
turns = []
turn_counter = 0
seen_user_messages = set()
def add_turn(role, content, **kwargs):
nonlocal turn_counter
if not content or not content.strip(): return
turn = {'turn_id': f'turn_{turn_counter}', 'role': role, 'content': content.strip(),
'timestamp': kwargs.get('timestamp', '')}
for k in ('model', 'usage', 'tool_calls', 'tool_name', 'tool_input', 'duration_ms', 'thinking'):
if kwargs.get(k) is not None: turn[k] = kwargs[k]
turns.append(turn)
turn_counter += 1
for run in runs_sorted:
run_type = (run.get('run_type') or '').lower()
ts = str(run.get('start_time') or '')
duration = _duration_ms(run.get('start_time'), run.get('end_time'))
inp = run.get('inputs') or {}
out = run.get('outputs') or {}
if run_type == 'llm':
messages = inp.get('messages') or inp.get('input') or []
if isinstance(messages, list) and messages and isinstance(messages[0], list):
messages = messages[0]
if isinstance(messages, list):
for msg in messages:
if isinstance(msg, dict):
if 'kwargs' in msg:
role = msg.get('id', [''])[-1] if isinstance(msg.get('id'), list) else ''
msg_data = msg.get('kwargs', {})
else:
role = msg.get('role') or msg.get('type', '')
msg_data = msg
if role in ('user', 'human', 'HumanMessage'):
content = msg_data.get('content', '')
if isinstance(content, list):
content = ' '.join(p.get('text', '') if isinstance(p, dict) else str(p) for p in content)
if content and content.strip():
msg_key = content[:200]
if msg_key not in seen_user_messages:
seen_user_messages.add(msg_key)
add_turn('user', content, timestamp=ts)
raw_content, tool_calls = '', []
gens = out.get('generations')
if isinstance(gens, list) and gens and isinstance(gens[0], list) and gens[0]:
gen = gens[0][0]
if isinstance(gen, dict):
message = gen.get('message', {})
msg_data = message.get('kwargs', {}) if 'kwargs' in message else message
raw_content = msg_data.get('content', '') or ''
for tc in (msg_data.get('additional_kwargs') or {}).get('tool_calls') or []:
if isinstance(tc, dict):
func = tc.get('function') or {}
tool_calls.append({'tool_name': func.get('name') or 'unknown',
'input': _to_str(func.get('arguments') or ''),
'call_id': tc.get('id', '')})
assistant_content, thinking = _split_thinking(raw_content)
usage = None
if run.get('prompt_tokens') or run.get('completion_tokens'):
usage = {'input_tokens': run.get('prompt_tokens', 0),
'output_tokens': run.get('completion_tokens', 0)}
if assistant_content and assistant_content.strip():
add_turn('assistant', assistant_content, timestamp=ts,
model=run.get('name') or '', usage=usage,
tool_calls=tool_calls if tool_calls else None,
duration_ms=duration, thinking=thinking)
elif run_type == 'tool':
tool_name = run.get('name') or 'unknown'
tool_output = (out.get('output', '') or _extract_content(out)) if isinstance(out, dict) else _extract_content(out)
if tool_output:
tool_input = _to_str(inp.get('input') or inp.get('query') or inp) if isinstance(inp, dict) else _to_str(inp)
add_turn('tool', str(tool_output), timestamp=ts, tool_name=tool_name,
tool_input=tool_input, duration_ms=duration)
if not turns:
root_input = _extract_content((root_run.get('inputs') or {}).get('input') or root_run.get('inputs'))
root_output = _extract_content((root_run.get('outputs') or {}).get('output') or root_run.get('outputs'))
if root_input: add_turn('user', root_input, timestamp=str(root_run.get('start_time', '')))
if root_output: add_turn('assistant', root_output, timestamp=str(root_run.get('end_time', '')))
return {
'trace_id': trace_id,
'session_id': str(root_run.get('session_id') or trace_id),
'metadata': {
'name': root_run.get('name') or '',
'source': 'langsmith',
'tags': root_run.get('tags') or [],
'start_time': str(root_run.get('start_time') or ''),
},
'turns': turns,
}
print('✓ Normalization functions defined')6. Fetch, Normalize, and Import into Label Studio
Fetches traces from LangSmith, normalizes them, creates a Label Studio project with the ReactCode config, and imports the tasks.
from label_studio_sdk import LabelStudio
from label_studio_sdk.core.request_options import RequestOptions
from typing import Any, Dict, List
_REQUEST_OPTS = RequestOptions(timeout_in_seconds=120)
def create_project(ls_host: str, api_key: str, title: str, label_config: str) -> int:
client = LabelStudio(base_url=ls_host, api_key=api_key)
project = client.projects.create(title=title, label_config=label_config, request_options=_REQUEST_OPTS)
return int(project.id)
def import_tasks(ls_host: str, api_key: str, project_id: int, tasks: List[Dict[str, Any]]) -> Any:
client = LabelStudio(base_url=ls_host, api_key=api_key)
return client.projects.import_tasks(id=project_id, request=tasks, return_task_ids=True)
if not LABEL_STUDIO_API_KEY:
raise RuntimeError('Missing LABEL_STUDIO_API_KEY — set it in your .env file.')
# 1) Fetch root runs (traces) from LangSmith
print(f'Fetching traces from LangSmith project: {LANGSMITH_PROJECT}...')
root_runs = [r.model_dump() for r in ls_client.list_runs(
project_name=LANGSMITH_PROJECT,
is_root=True,
limit=20,
)]
if not root_runs:
raise RuntimeError('No traces returned. Run Section 3 to generate sample traces.')
print(f'Fetched {len(root_runs)} root runs from LangSmith')
# 2) For each root run, fetch all child runs and normalize
tasks: List[Dict[str, Any]] = []
skipped = 0
for root in root_runs:
trace_id = str(root.get('trace_id') or root.get('id'))
all_runs = [r.model_dump() for r in ls_client.list_runs(
project_name=LANGSMITH_PROJECT,
trace_id=trace_id,
)]
if len(all_runs) <= 1:
skipped += 1
continue
normalized = normalize_langsmith_trace(root, all_runs)
if normalized['turns']:
tasks.append({'data': normalized})
print(f" + Trace {trace_id[:12]}... -> {len(normalized['turns'])} turns "
f"({sum(1 for t in normalized['turns'] if t['role']=='user')} user, "
f"{sum(1 for t in normalized['turns'] if t['role']=='assistant')} assistant, "
f"{sum(1 for t in normalized['turns'] if t['role']=='tool')} tool)")
if skipped:
print(f' (skipped {skipped} traces without child runs)')
print(f'\nPrepared {len(tasks)} tasks for import')
# 3) Create project and import
project_id = create_project(
ls_host=LABEL_STUDIO_HOST,
api_key=LABEL_STUDIO_API_KEY,
title=f'LangSmith Trace Review ({LANGSMITH_PROJECT})',
label_config=LABEL_CONFIG_XML,
)
print(f'Created project: {project_id}')
resp = import_tasks(LABEL_STUDIO_HOST, LABEL_STUDIO_API_KEY, project_id, tasks)
print(f'Imported {len(tasks)} tasks')
print(f'\nDone! Open your project: {LABEL_STUDIO_HOST.rstrip("/")}/projects/{project_id}')What’s Next
- Start annotating: Open the project link above and click through traces in the ReactCode UI
- Share with SMEs: Invite domain experts to your Label Studio project for collaborative evaluation
- Incremental sync: Re-run sections 4–6 periodically to pull new traces
- Export annotations: Use the Label Studio SDK or REST API to pull structured annotations for downstream analysis or fine-tuning
- Custom taxonomy: Edit the
_TEMPLATE_JSvariable in the label config cell to add failure modes specific to your domain - Braintrust / Langfuse: See companion tutorials for other observability platforms
Summary
This tutorial demonstrated the complete workflow from LangSmith traces to expert evaluation:
- ✓ Set up environment with LangSmith and Label Studio Enterprise
- ✓ Defined a ReactCode-based 3-panel annotation UI (Enterprise feature)
- ✓ Ran a multi-tool ReAct agent with Claude extended thinking — LangSmith captured traces automatically via
LANGSMITH_TRACING=true - ✓ Fetched traces from LangSmith using the
langsmithSDK - ✓ Normalized the hierarchical run structure into a unified trace schema
- ✓ Created a Label Studio project and imported traces as annotation tasks
Key Takeaway
LangSmith excels at automatic trace instrumentation and hierarchical run inspection during development. Label Studio Enterprise provides the collaborative, expert-driven evaluation framework — with the ReactCode interface giving domain experts an intuitive turn-by-turn review experience. The two tools complement each other throughout the AI development lifecycle.