RAG Evaluation and Fine-Tuning with Label Studio
Trying to build a RAG pipeline but struggling with reliability? Label Studio can help.
Label Studio is a free, open source data labeling platform that makes labeling data for evaluating and fine-tuning RAG use cases easier and faster, while ensuring that you get the high-quality data that you need to make your project successful.
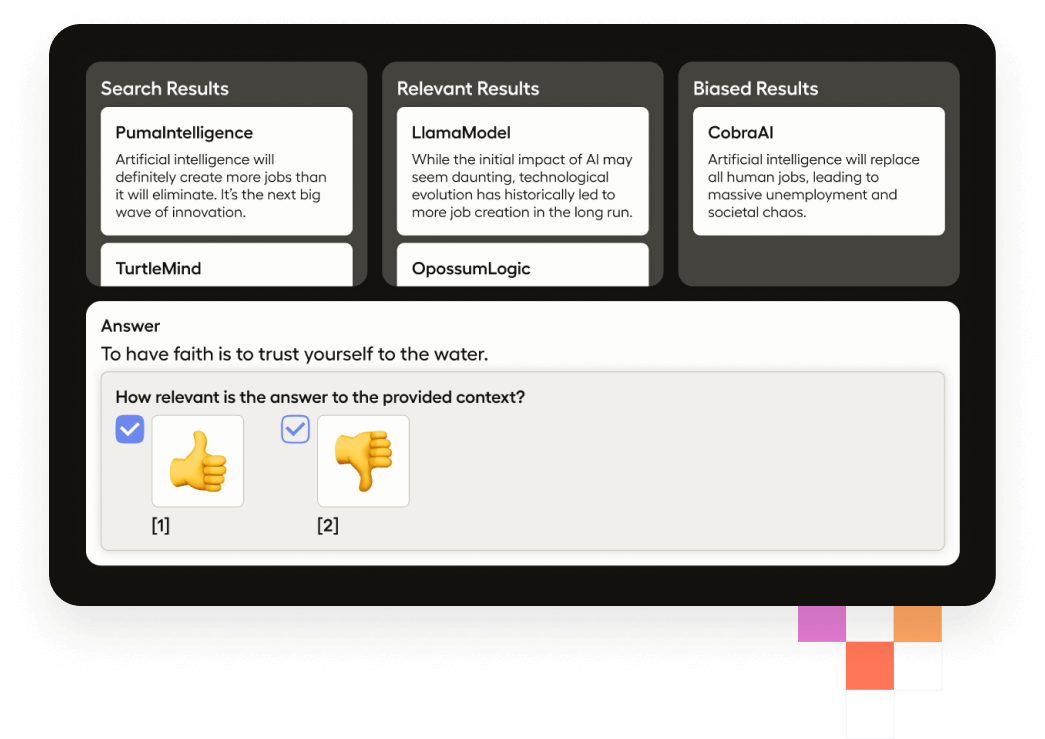
Using Label Studio for RAG applications
Retrieval-Augmented Generation (RAG) pipelines solve one of the major obstacles of using Large Language Models (LLMs) in production by enabling them to retrieve contextual data in real-time, which allows them to generate more relevant responses for end users. A RAG pipeline is particularly advantageous in use cases where the knowledge base is extremely large and dynamic, such as customer support, content generation, and real-time data analysis.
But while RAG pipelines offer significant advantages, they are not without limitations, especially when it comes to precision, conflicting data sources, complex queries, and adapting to dynamic data environments. But Label Studio can help you optimize your RAG pipeline for reliability and efficiency much faster and more easily.
Pre-built configurations and templates get you started quickly
Streamline your process of setting up evaluation tasks for RAG applications and make it easier to rank LLM outputs at scale. Our templates and configurations help jumpstart different stages of your RAG pipeline, from data preparation to evaluation and fine-tuning.
-
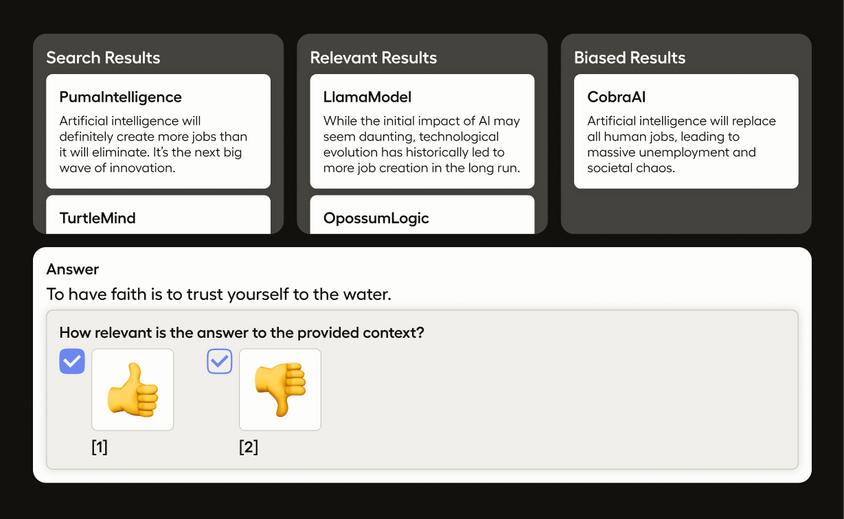
Evaluate RAG with Human Feedback
Enable human reviewers to assess the relevance and faithfulness of generated content, providing feedback to refine and improve the quality of your RAG pipeline.
Use template -
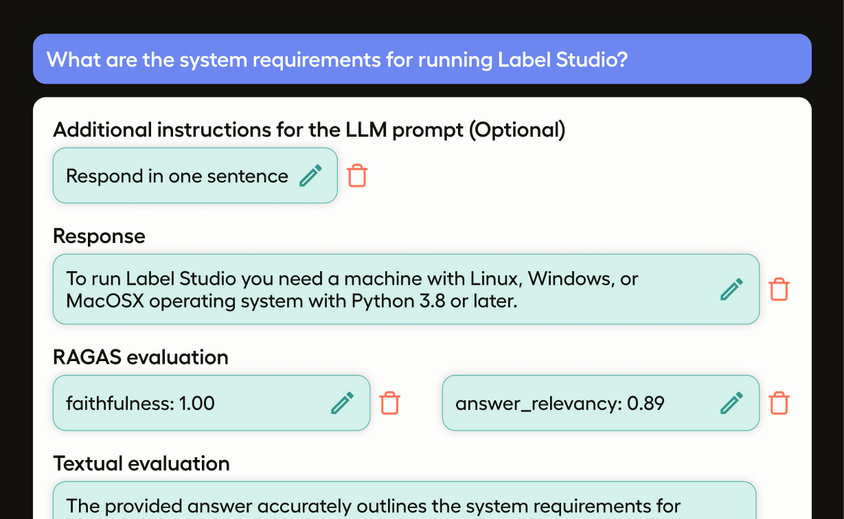
Use the RAGAS framework to assess the relevance and faithfulness of responses, providing detailed metrics and a comprehensive evaluation of the documents used as context.
Use template -

Rank LLM responses based on relevance and quality, helping identify the best answers and build preference models for Reinforcement Learning from Human Feedback (RLHF).
Use template
RAG evaluation and fine-tuning integrations
Label Studio offers a range of integrations to enhance RAG evaluation and fine-tuning workflows. These integrations facilitate seamless data annotation, model training, and evaluation processes, ensuring your RAG applications are both efficient and effective.
-
 LangChain
LangChainEvaluate LLM Output Quality
-
 Hugging Face
Hugging FaceLabel Studio in Hugging Face Spaces
-
 PyTorch
PyTorchOpen source machine learning framework
-
 TensorFlow
TensorFlowOpen source deep learning framework
-
 Scikit Learn
Scikit LearnMachine learning toolkit
-
 Amazon SageMaker
Amazon SageMakerIntegrate Label Studio with AWS SageMaker
-
 Lightly.ai
Lightly.aiActive learning for data management
-
 Galileo
GalileoUncover data issues and errors
-
 Unstructured.io
Unstructured.ioUnstructured data ingestion and preprocessing
Why use Label Studio to optimize Your RAG pipeline?
RAG evaluation metrics
Implement tailored metrics to assess your RAG pipeline’s performance, identify areas for improvement, and ensure alignment with your goals.
Document ranking and re-ranking
Improve search precision by enabling annotators to rank and re-rank retrieved documents based on relevance and accuracy.
AI-powered textual evaluations
Use "LLM as judge" for AI-driven, qualitative analysis of generated answers, ensuring quality, accuracy, and alignment with content goals.
Customizable labeling interfaces
Design intuitive interfaces that match your RAG evaluation needs for efficient data annotation and fine-tuning.
ML backend integration
Integrate Label Studio with ML backends like OpenAI or Cohere to streamline connections between your RAG system and AI models.
Versatile data handling
Import and manage data in multiple formats—text, image, audio, video, HTML, and time series—giving you flexibility in your RAG evaluation.
Getting started with Label Studio
- Install Label Studio: Follow the installation guide for your preferred setup.
- Create a Project: Start a new project, name it, and specify your project's parameters.
- Import data: Upload your data into the project.
- Configure labeling interface: Use a custom template or pre-built template to set up the desired annotation tools and labels.
- Integrate ML backend (optional): Integrate your ML models with Label Studio to enable pre-annotations and active learning. Watch video tutorial
- Label data: Annotate your data using the tools and tags you configured.
- Export data: Export your labeled data for training or further analysis.
Want some extra help getting started with Label Studio?
We've got some additional resources to help you get up and running:
- First, make sure you have downloaded Label Studio.
- Check out our Getting Started tutorial to learn how to set up your first project, including labeling configuration and template creation.
- Join our Slack community (11,000+ members, and growing).
Introducing Label Studio Enterprise
Get more from your team and existing workflows with advanced automation and management tools
The open source Community version of Label Studio provides a solid foundation for building RAG applications. The Enterprise version offers advanced, exclusive features that emphasize scalability, automation, fine-tuning, and detailed evaluation.
Auto-labeling with LLMs
Generate high-quality annotations at scale using LLM-powered auto-labeling, reducing manual workload and ensuring consistency with ground truth data.
Prompt evaluation and fine-tuning
Refine prompts in real-time with human feedback to optimize your RAG pipeline, enhance model outputs, and align responses with your content goals.
Dataset sourcing and curation
Generate embeddings and curate high-quality datasets using semantic and similarity search, enhancing the relevance and effectiveness of labeling tasks.
Trusted by 350,000+ users and companies large and small





Frequently Asked Questions
Evaluation
What is RAG evaluation?
RAG evaluation is the process of assessing the quality and effectiveness of a Retrieval-Augmented Generation system. This involves measuring how well the system retrieves relevant information and how accurately it generates responses based on that information. RAG evaluation goes beyond assessing a single LLM response and incorporates various assessments of retrieved documents, including contextual and answer relevancy and faithfulness.
Why is evaluating RAG applications important?
Evaluating RAG applications is crucial because it ensures that the system provides correct, up-to-date, and contextually relevant information to the user. RAG systems can sometimes produce random, irrelevant, or fabricated outputs, making thorough evaluation essential. The success of a RAG application depends on how well it retrieves and integrates external information, so monitoring metrics like the relevance of retrieved documents, accuracy of answers, and consistency of responses is essential.
How do you evaluate a RAG system?
Evaluating a RAG system involves several steps:
- Define specific metrics: Use quantitative metrics for precision, recall, and accuracy. User satisfaction should also be measured.
- Create an evaluation dataset: Mimic real user queries with a set of questions, along with relevant passages (retriever ground truth) and correct answers (answer ground truth).
- Use automated tools: Tools like AutoRAG can optimize pre-production RAG using a small dataset.
- Implement observability: Collect and analyze information for every response generated, including user feedback (thumbs up/down), cosine similarity of text chunks, and cohere relevance scores.
- Assess context relevance and query matching: Evaluate how well the query matches documents in the vector database, and whether the retrieved context is fully relevant.
- Evaluate faithfulness and answer relevance: Assess if the generated response is factually correct based on retrieved documents (faithfulness) and if the answer directly addresses the query (answer relevancy).
- Use LLMs as judges: Employ LLMs to assess the quality of answers, checking if they are actual answers to the questions and if they come from the sources.
- Evaluate the retrieval component: Assess if the system is retrieving the right information using metrics like cosine similarity and re-ranking methods to ensure the most pertinent documents appear first.
- Incorporate human feedback: Use human reviewers to validate the system's outputs and make corrections. Collect user feedback to refine the system.
- Iteratively refine the system: Use feedback and evaluations to update the corpus, fine-tune the embedding model, and adjust the prompts.
What are some good RAG evaluation metrics?
Good RAG evaluation metrics include:
- Precision, recall, and F1 score: To evaluate the quality of retrieval.
- METEOR, BLEU, ROUGE, and BERTScore: To evaluate the quality of generated answers.
- Cosine similarity and cohere relevance scores: To measure the relevance of text chunks.
- Faithfulness: Measures whether the response is factually correct based on the retrieved documents.
- Answer relevancy: Measures whether the generated answer directly addresses the query.
- Ragas metrics: Faithfulness and answer relevancy. Ragas also provides other metrics that might be useful.
- Textual evaluation: Subjective assessment of the quality of the LLM's answer by another LLM to identify issues such as unsupported facts or irrelevant details.
How do I know if my RAG application's performance is improving?
You can assess if your RAG application is improving by:
- Monitoring metrics: Track metrics like faithfulness and answer relevancy using tools like Ragas.
- Analyzing user feedback: Collect and analyze user feedback such as thumbs up/down. Ask specific questions such as “did we answer your question?” instead of vague ones like “how did we do?”
- Evaluating textual analysis: Review the textual evaluations provided by the LLMs to identify and address issues in the responses.
- Observing consistency: Check if the system provides more consistent and relevant answers over time.
- Refining prompts: Make changes to prompts and observe their influence on faithfulness and relevancy.
Fine-Tuning
What is RAG fine-tuning?
RAG fine-tuning involves adjusting the model parameters to improve its performance on specific tasks. This can include fine-tuning the LLM used for both retrieval and generation components. Fine-tuning can help the model avoid repeating mistakes, learn a desired response style, and handle rare edge cases more effectively. Fine-tuning can also improve the model’s ability to access external data and enhance the transparency of its responses.
How do you fine-tune the embedding model for RAG?
Fine-tuning the embedding model for RAG involves training the model to better represent the semantic content of the text in your specific domain. This can be achieved by:
- Collecting relevant data: Gather domain-specific data.
- Using positive and hard-negative examples: Create a training dataset with positive examples of relevant documents for a query, as well as hard-negative examples, to train the model.
- Employing triplet-loss: Use a triplet-loss function for training.
- Re-ranking: Implement re-ranking of search results to prioritize the most relevant documents.
- Iterative refinement: Continuously refine the embedding model based on performance metrics and evaluations.
Is it possible to do RAG evaluation without ground truth?
Yes, it is possible to do RAG evaluation without ground truth. Some Ragas metrics, such as faithfulness and answer relevancy, do not depend on having an established ground truth. Textual evaluations by LLMs also provide a subjective assessment of answer quality. However, having ground truth data can be helpful for more comprehensive evaluations when available. For example, you can use LLMs to generate questions based on a document set or you may manually create questions and answers.
Read more about RAG and Label Studio
View All Articles-

Key Considerations For Evaluating RAG-Based Systems
Implementing RAG-based systems comes with challenges to be aware of, particularly in assessing the quality of generated responses. This article will walk you through some of those challenges.

Jo Booth
Senior Full Stack Engineer
-
Optimizing RAG Pipelines with Label Studio
In this introduction to our tutorial series on optimizing RAG pipelines, we'll introduce an example question answering (QA) system leveraging a Retrieval-Augmented Generation (RAG) architecture and outline three methods for optimizing your RAG pipeline utilizing Label Studio.

Max Tkachenko
Co-founder, HumanSignal and Label Studio
-

An Introduction to Retrieval-Augmented Generation (RAG)
Get a brief overview of RAG and how it relates to LLMs, learn when you might consider using RAG, and get a summary of some challenges based on current research you should be aware of should you choose to travel down this path.

Nate Kartchner
Director of Marketing