Fine-Tuning OpenAI Models: A Guide with Wikipedia Data

Fine-tuning large language models (LLMs) is a powerful way to tailor AI to your specific needs. With OpenAI’s new fine-tuning feature, you can tune their models using domain-specific data, instructions, or even custom formats. This means you can get more accurate, relevant responses without constantly tweaking prompts, ultimately reducing costs and improving efficiency.
In this guide, we’ll walk you through the entire fine-tuning process on OpenAI’s platform—from preparing your data to estimating costs and deploying your fine-tuned model. If you’ve followed our previous post on fine-tuning a Llama 3 model, this post will take a similar direction, but focusing on OpenAI’s tools and showcasing a real-world example using updated Wikipedia data.
Fine-Tuning and When to Use It
Fine-tuning a large language model (LLM) means continuing to train it on new, specific data, allowing you to shape its responses for a particular task or domain. This approach lets you build on the broad knowledge the model already has while teaching it to handle more specialized content.
Take OpenAI’s GPT-4o model, for example—it’s highly versatile and works well for a wide range of tasks. But like any general-purpose tool, it has limits. For instance, its training data cuts off in September 2023, so it won’t know anything beyond that point. You might also find that the model needs long, complex prompts to get exactly what you’re after, which can drive up costs due to token usage.
Fine-tuning can help overcome these challenges, but it’s not always the right choice. Here’s when it makes sense to fine-tune:
- You have a specific dataset with prompts and the exact outputs you want.
- You need the model to consistently follow a format—whether it’s structured reports or making API calls.
- You want to reduce the length and cost of your prompts.
- You have domain-specific data that should be incorporated, avoiding the need for expensive retrieval-augmented generation (RAG) workflows.
In this guide, we’ll show you how to fine-tune a model with recent updates from Wikipedia. If you’d like to dive deeper into the full code, you can find the notebook in our examples repository.
Data Curation and Preparation
To demonstrate the fine-tuning process, we’ll be working with a real-world dataset—recent updates to hurricane data from Wikipedia. This dataset is ideal for a couple of reasons. First, it’s time-sensitive information that the model hasn’t been exposed to due to its September 2023 cutoff. Second, it gives us a chance to fine-tune the model to handle new information about a very specific and important topic: hurricanes. The goal here is to ensure the model can generate accurate, up-to-date responses based on the latest data. Let’s walk through how we prepare the data step-by-step.
- Collect Data: Gather the latest revisions from selected Wikipedia pages.
- Generate Q&A Pairs: Turn the raw hurricane data into a useful set of question-and-answer pairs.
- Create Fine-Tuning Dataset: Format the dataset to fit OpenAI’s requirements for fine-tuning.
Collect Data
We start by defining the list of Wikipedia pages that contain relevant information about hurricanes. This could include articles on specific storms, like Hurricane Milton, or broader topics like the 2024 Atlantic hurricane season. By pulling the most recent revisions from these pages, we ensure that the data we’re feeding the model is current and hasn’t been included in its original training set.
# List of relevant topics
topics = [
"List_of_United_States_hurricanes",
"2024_Atlantic_hurricane_season",
"Hurricane_Milton",
"Hurricane_Beryl",
"Hurricane_Francine",
"Hurricane_Helene",
"Hurricane_Isaac"
]A key part of this process is specifying a date range—specifically, we’ll focus on updates made after the model’s September 2023 knowledge cutoff. This guarantees that the model doesn’t already “know” the data we’re using for fine-tuning. Once we’ve collected all the necessary updates, we’ll move on to creating a training set.
def get_wikipedia_revisions(article_title, start_date):
...
def fetch_revisions_for_topics(topics, start_date):
"""Fetches revisions for all topics after a certain date and returns a combined dataset."""
full_dataset = [] # List to hold data for all topics
for topic in topics:
try:
print(f"Fetching revisions for {topic} starting from {start_date}...")
topic_data = get_wikipedia_revisions(topic, start_date)
full_dataset.extend(topic_data) # Append the data for each topic to the full dataset
except Exception as e:
print(f"Error fetching revisions for {topic}: {str(e)}")
return full_dataset # Return the full dataset
# Specify the start date (ISO 8601 format)
start_date = "2023-09-01T00:00:00Z"
# Fetch the latest revisions for all topics and store them in a dataset
dataset = fetch_revisions_for_topics(topics, start_date)If you’re interested in the detailed code for fetching Wikipedia revisions, it’s available in our notebook linked here.
Generate QA Pairs
Once we’ve collected the new data, the next step is to format it in a way that the model can effectively learn from. A highly effective method is to generate question-and-answer (Q&A) pairs. Why? Because this format closely mimics how the model will be used in real-world applications—whether that’s answering customer queries, handling FAQs, or providing information in response to prompts.
For example, given new hurricane data, we can generate questions like “When did Hurricane Milton hit the U.S.?” and then provide the corresponding answer based on the Wikipedia update. While creating these Q&A pairs manually would be time-consuming and error-prone, we can leverage OpenAI’s existing capabilities to generate them automatically from the Wikipedia revisions.
One particularly useful feature is Structured Output, which ensures that the generated answers follow a consistent format. This is important because it makes it easier to work with the data during the next stage of the process. If you’re interested in learning more about how to use Structured Outputs effectively, we’ve written a detailed blog post on the topic, which you can check out here.
from openai import OpenAI
from pydantic import BaseModel
from typing import List, Literal
import json
# Define the Pydantic model for the output format
class QAItem(BaseModel):
prompt: str
completion: str
class QADataset(BaseModel):
dataset: List[QAItem]
def generate_qa_pairs_from_changes(new_content, article_title):
"""
Query OpenAI to analyze the new content and generate a set of question-answer pairs.
If substantial information changes are detected (such as new sections, significant updates, or meaningful additions of facts),
the function returns a list of question-answer pairs in the specified JSON format.
"""
client = OpenAI()
# Create a query prompt to ask OpenAI to generate question-answer pairs based on the content
prompt = f"""
The following is newly added content to the Wikipedia article titled '{article_title}'.
Analyze the content and generate a set of specific question-answer pairs based on the new facts, updates, or meaningful changes.
Focus on creating general questions that a person might ask and answered them comprehensively with the content provided.
Do not ask questions that directly reference the date of the revision or the specific article title.
If a hurricane is mentioned, it should be referred to by its full name.
Ignore trivial changes such as typos or formatting.
Example questions:
- List the hurricanes that hit the US in 2024.
- What was the most recent hurricane to hit the US?
- What was the name of the hurricane that hit Florida in 2024?
- What was the category of hurricane Beryl?
- What was the path of hurricane Milton?
New Content:
\"\"\"{new_content[:3000]}\"\"\"
Please return a set of question-answer pairs in the form of a JSON array where each item is an object containing
'prompt' as the question and 'completion' as the direct answer from the content.
"""
try:
response = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06", # or "gpt-4o" if available
messages=[
{"role": "system", "content": "You are a helpful assistant that generates a set of specific question-answer pairs based on the new facts, updates, or meaningful changes Wikipedia articles."},
{"role": "user", "content": prompt}
],
max_tokens=1000,
temperature=0.7,
response_format=QADataset
)
return response.choices[0].message.content
except Exception as e:
return f"Error in generating QA pairs: {str(e)}"Once we have curated our Q&A dataset, we view some of the examples that were generated.
Number of examples in master_qa_list: 10362
{'prompt': 'When were shelters opened on the Caribbean islands due to Hurricane Beryl?', 'completion': 'Shelters were opened on June 29 on the Caribbean islands in response to Hurricane Beryl.'}
{'prompt': 'What measures were taken in Tobago in response to Hurricane Beryl?', 'completion': 'A state of emergency was declared for Tobago. Ferry schedules were modified on June 30, and all ferries to Tobago for July 1 were cancelled. Schools across the nation were also closed for July 1. Additionally, 145 people were sheltered in 14 shelters across Tobago.'}
{'prompt': 'How did Hurricane Beryl affect ferry operations in Trinidad and Tobago?', 'completion': 'Ferry schedules were modified on June 30, and all ferries to Tobago for July 1 were cancelled due to Hurricane Beryl.'}
{'prompt': 'How many people sought shelter in Tobago during Hurricane Beryl?', 'completion': '145 people sought shelter in 14 shelters across Tobago during Hurricane Beryl.'}Once we’ve compiled a robust Q&A dataset, it’s always a good idea to take a closer look at the results. At this point, we likely want to have human reviewers validate the Q&A pairs to ensure accuracy. We will create a project in Label Studio to annotate the dataset.
from label_studio_sdk.client import LabelStudio
# Connect to the Label Studio API and check the connection
ls = LabelStudio(base_url=LABEL_STUDIO_URL, api_key=API_KEY)
label_config = """
Details in Notebook...
"""
# Create a new project
project = ls.projects.create(
title='Hurricane Data Project',
description='Label questions and completions about hurricanes with their respective contexts and titles.',
label_config=label_config
)
from label_studio_sdk.label_interface.objects import PredictionValue
for qa_pair in master_qa_list:
# Create task data
task_data = {
"data": {
"question": qa_pair['prompt'],
"article_title": qa_pair['article_title'],
"context": qa_pair['new_content']
}
}
# Create the task in Label Studio
task = ls.tasks.create(project=project.id, **task_data)
task_id = task.id
print(f"Task created with ID: {task_id}")
# Create prediction data
prediction = PredictionValue(
model_version="v1",
result=[
{
"from_name": "completion",
"to_name": "question",
"type": "textarea",
"value": {
"text": [qa_pair['completion']]
}
}
]
)
# Insert prediction into the task
ls.predictions.create(task=task_id, **prediction.model_dump())
print(f"Prediction added for task ID: {task_id}")After inserting our data into the project, we view our dataset with the predictions generated as shown in Figure 1.
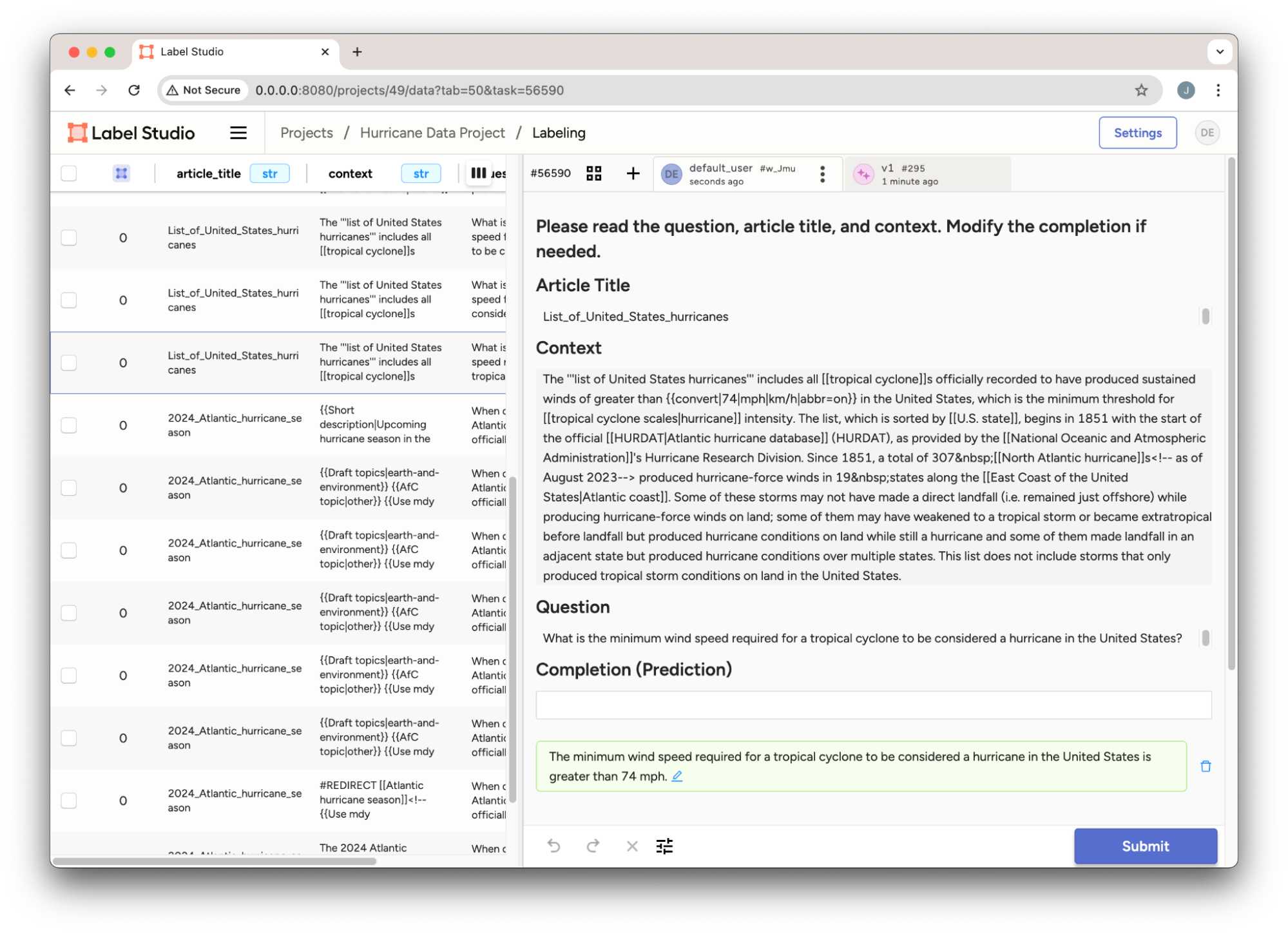
Figure 1: Hurricane Q&A Project in Label Studio.
The full details for using the Label Studio SDK to create and set up our project, see the example notebook.
Create Fine-Tuning Dataset
With our Q&A dataset ready, the final step is to format the data for OpenAI’s fine-tuning platform. OpenAI requires a specific format, known as the jsonl chat format, where each interaction includes a system message, a user prompt, and the corresponding response from the assistant. This ensures that the fine-tuned model understands how to respond in a way that fits your use case.
For instance, here’s a simplified example from OpenAI’s Fine-Tuning Docs, which shows a model being trained to respond in a slightly sarcastic tone:
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?"}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters."}]}In our case, we’ll need to manipulate our Q&A data to match this structure, replacing the sarcastic chatbot context with a more neutral, helpful tone suited for answering questions about hurricanes. Once that’s done, the dataset will be ready for fine-tuning.
# System message for all entries
system_message = {"role": "system", "content": "You are a helpful assistant that answers questions about current events in hurricanes. Provide detailed answers."}
# List to store the converted dataset
new_format_dataset = []
# Convert each prompt-completion pair to the new format
for entry in master_qa_list:
new_entry = {
"messages": [
system_message,
{"role": "user", "content": entry['prompt']},
{"role": "assistant", "content": entry['completion']}
]
}
new_format_dataset.append(new_entry)Fine-Tuning
Now that we’ve prepared our dataset, the next step is uploading it to OpenAI’s platform for fine-tuning. This involves writing the data to a file and then creating a fine-tuning job that uses the formatted dataset to train the model.
Uploading the Dataset
The first thing we need to do is upload the dataset to OpenAI. This is straightforward using OpenAI’s API, where we specify the file containing our Q&A pairs in the correct format (`jsonl`), along with the purpose of the file—fine-tuning.
client.files.create(
file=open("qa_pairs_openai_wiki_hurricane_dataset_format.jsonl", "rb"),
purpose="fine-tune"
)Once the file is uploaded, you’ll receive a response containing metadata about the file. One key piece of information is the file ID, which we’ll need to reference when we start the actual fine-tuning job. You should see an output similar to this:
FileObject(id='file-qBVnzhGrEHvEPvZg6ZwvTfpK', bytes=4301148, created_at=1728916096, filename='qa_pairs_openai_wiki_hurricane_dataset_format.jsonl', object='file', purpose='fine-tune', status='processed', status_details=None)The id (`file-qBVnzhGrEHvEPvZg6ZwvTfpK` in this example) is what we’ll use when we create the fine-tuning job.
Starting the Fine-Tuning Job
With the file uploaded, we’re ready to kick off the fine-tuning job. This step involves telling OpenAI which model you want to fine-tune, which dataset to use, and optionally providing a custom suffix for easy identification later on.
In our case, we’re fine-tuning the model `gpt-4o-mini-2024-07-18` with the hurricane data we just uploaded:
client.fine_tuning.jobs.create(
training_file="file-qBVnzhGrEHvEPvZg6ZwvTfpK",
model="gpt-4o-mini-2024-07-18",
suffix="wiki-hurricane-2024"
)Monitoring the Fine-Tuning Process
Once you’ve created the job, you can track its progress via the OpenAI dashboard or API. Figure 1 shows what we can expect to see in the fine-tuning page. We can monitor the status of our fine-tuning job or we can wait for an email notifying us when it completes or if there were any errors.
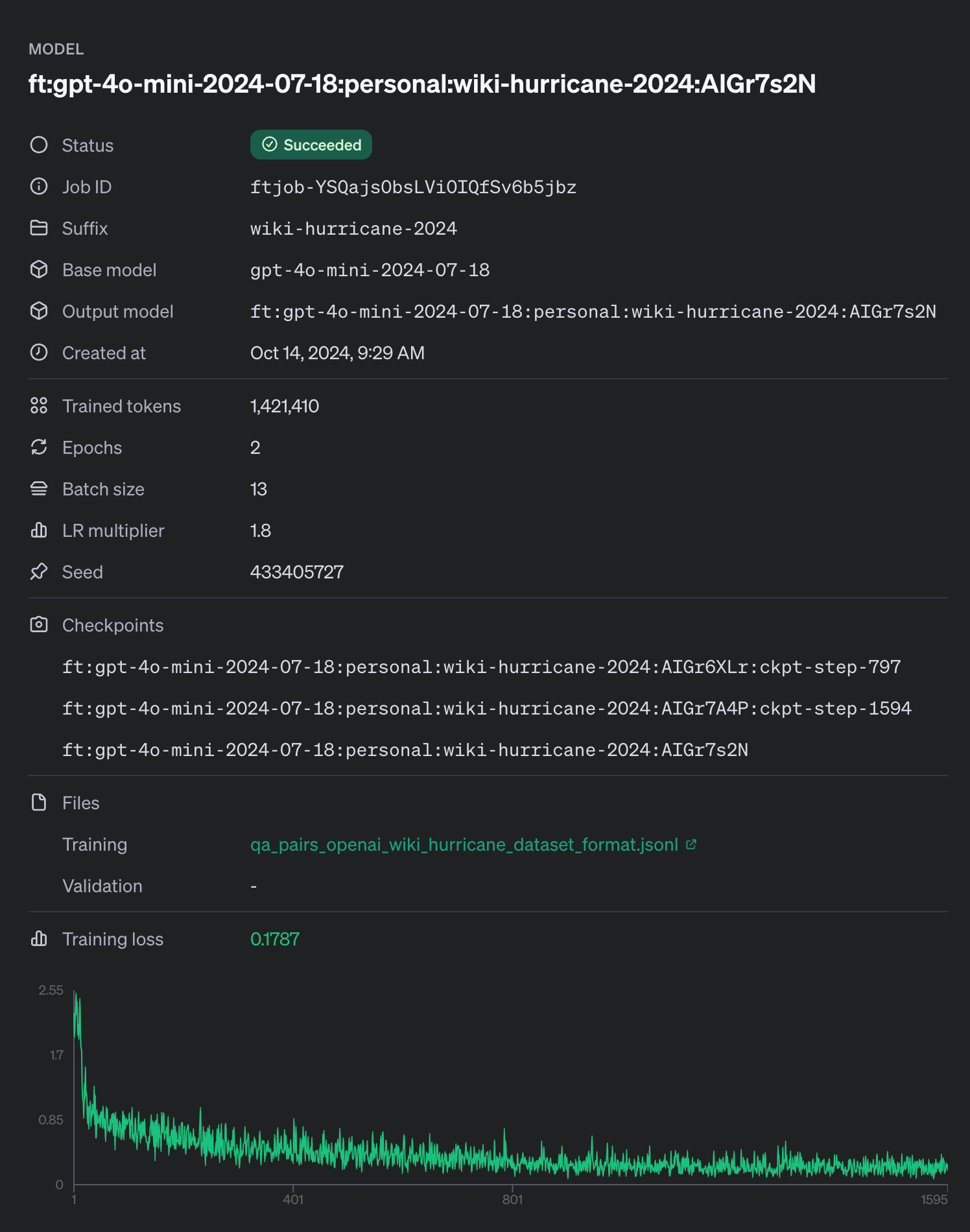
Figure 2: OpenAI fine-tuning details from our hurricane dataset.
In our example here we did not include a validation dataset. A validation set can be used to ensure that the model isn’t overfitting to the training data, that the knowledge is generalizable (e.g. only answering the exact question that is asked and not a similar question).
Fine-Tuning Time and Costs
It’s important to note that fine-tuning a model isn’t instantaneous—it can take time depending on the size of the model and the complexity of your dataset. Larger models like GPT-4o will naturally require more processing power and time compared to smaller ones. Similarly, a dataset with thousands of detailed entries will take longer to fine-tune than a smaller, more focused set of examples.
Beyond time, fine-tuning comes with costs, so it’s essential to plan your budget accordingly. OpenAI charges based on factors like the number of tokens used during the fine-tuning process, as well as the type of model you’re working with. To help manage this, OpenAI provides tools for tracking token usage and costs throughout the process, enabling you to optimize your fine-tuning workflow and avoid unnecessary expenses. We’ve included some of these tools in the example notebook, that will provide statistics like the following:
Dataset has ~736249 tokens that will be charged for during training
By default, you'll train for 2 epochs on this dataset
By default, you'll be charged for ~1472498 tokensFor exact pricing and more details, take a look at OpenAI’s pricing page.
Using the Fine-Tuned Model
Once the fine-tuning process is complete, you can start using your newly customized model just like any other model from OpenAI. The key advantage here is that the model is now specialized for your particular use case—in our example, answering questions about recent hurricanes based on the latest Wikipedia updates.
To interact with the fine-tuned model, we use OpenAI’s API, specifying the unique identifier of the model we just trained. In this case, the fine-tuned model is called `ft:gpt-4o-mini-2024-07-18:personal:wiki-hurricane-2024:AIGr7s2N`. Here’s a simple example of how to use the fine-tuned model to get information about Hurricane Milton:
from openai import OpenAI
client = OpenAI()
completion = client.beta.chat.completions.parse(
model="ft:gpt-4o-mini-2024-07-18:personal:wiki-hurricane-2024:AIGr7s2N",
messages=[
{"role": "system", "content": "You are a helpful assistant that answers questions about current events in hurricanes. Provide detailed answers."},
{"role": "user", "content": "When did Hurricane Milton hit the US?"}
]
)
print(completion.choices[0].message)In this example, the model uses the fine-tuned data on hurricanes to answer a specific question about Hurricane Milton. The result should reflect the up-to-date information we included during the fine-tuning process:
The most recent hurricane to hit the US in 2024 is Hurricane Milton, which struck Florida on October 9.This response demonstrates how the model now “knows” recent information that it didn’t have access to before the fine-tuning. You can now use this model for similar queries or integrate it into applications, such as chatbots, that require real-time knowledge of current events in your specific domain.
It’s important to note that while the model is now tuned for your needs, testing it with a range of inputs is still crucial. This helps ensure the model consistently delivers the desired outputs and performs well across various scenarios. This is typically an iterative process that requires refining your dataset and subsequent fine-tuning jobs to get desirable results.
If you want to integrate this fine-tuned model into Label Studio, you can easily do so using the Label Studio ML Backend, specifically the LLM Interactive Example. By setting the `OPENAI_MODEL` parameter to the name of your fine-tuned model, you can leverage it for generating predictions with new prompts. This can help streamline your annotation process by allowing the model to assist with re-generating predictions or supporting other annotation projects.
Conclusion
Fine-tuning is a powerful tool for customizing AI models, allowing them to perform more accurately in specific contexts with minimal manual intervention. OpenAI’s platform makes the fine-tuning process straightforward, reducing the complexity of configurations and letting you focus on curating quality data. Whether you’re improving chatbot performance or generating tailored content, fine-tuning can significantly boost your model’s performance in real-world scenarios.
If you’re interested in incorporating LLMs into your GenAI workflow, be sure to check out the Enterprise feature, Prompts. Prompts provide a flexible way to integrate these advanced AI features into your projects, streamlining tasks like annotation and decision-making across your organization.
Related Content
-

The 5 Metrics That Actually Move AI Into Production
A practical framework for turning AI metrics into clearer decisions about what to fix, ship, and scale.

Sheree Zhang
April 15, 2026
-

Scaling AI Data Quality: Best Practices for Onboarding and Evaluating Annotators
A practical workflow for onboarding and evaluating annotators with clear instructions, calibration, quality gates, reviewer feedback, and dashboards that keep labeling consistent as volume grows.

Alec Harris
March 12, 2026
-

How to Create a Prompt Generator with Label Studio and RLVR
In this article, you'll learn how to apply an RLVR-based score verifier and use an LLM as a prompt optimizer to enhance your prompts.

Label Studio Team
March 2, 2026