Implementing Audio Classification for Machine Learning Projects Using Label Studio
It’s easy enough to say, “Hey Alexa, play my favorite Christmas songs.” But how does the virtual assistant find the song you want?
The answer is audio classification—the process of analyzing and identifying audio data to classify and interpret the data accordingly. Along with voice-based smart assistants, audio classification has applications in music recommendation engines, chatbots, speech recognition software, and even voice payments.
With this guide, learn how audio classification works and how to implement it when building audio ML projects, so you can optimize your ML models and build a better overall product.
How Audio Classification for Machine Learning Works
To understand how audio classification works, let’s walk through an example of audio classification in a voice-based virtual assistant. The goal is for the virtual assistant to recognize the user's voice and respond to a command.
All digital virtual assistants have two main components:
- Speech-to-Text (STT) - a voice processing component that takes the user input (i.e., speech) as an audio format and transcribes the utterance into text.
- Natural Language Understanding (NLU) - a component that takes the text transcription of the user input and extracts structured data that allows the system to understand human language.
Voice-enabled technologies rely on deep learning—a specific kind of machine learning (ML)—to train the STT and NLU components. Here, we label a large and wide diversity of speech samples (audio samples from children, women, and men from different countries and ethnicities with multiple intonations).
We then mark every word in the audio sample with a text label from the corresponding audio in the text. This labeling aims to help the machine learning algorithm find patterns in the data (referred to as training data), which it can then use to identify a new audio sample (test data). This process is repeated multiple times until the ML model learns to perform STT and NLU with high accuracy.
Once we have tested the models, they can be deployed in virtual assistants to identify the user's voice, intent, and key information in the command that is required to address it.
Approaches to Machine Learning Training
This process of training ML models to learn usually involves supervised, unsupervised, and semi-supervised learning.
Supervised learning is a type of ML that trains algorithmic models on known input and output data (i.e., labeled data samples). Supervised learning classifies items based on an underlying truth supplied to the learning model. This approach is beneficial in classification problems like identifying a speaker in a conversation.
In the case of our earlier example, the training sets for STT consist of audio files, and the corresponding word-level transcriptions are the labels. In contrast, the training sets for NLU consist of text files, and the related intents and key pieces of information we extract are the labels. The STT and NLU require a massive amount of labeled training data to achieve excellent performance.
Unsupervised learning is the process of teaching an ML model to use data that has neither been classified nor labeled and then letting the program use that data without supervision. Here the goal of the machine is to group unsorted information according to similarities, patterns, and differences without any prior training of the data.
Unsupervised learning helps solve clustering and associative problems, especially in music recommendation engines where similar songs can be grouped based on tempo, beat, pitch, and musical instruments. In voice-assisted technology devices, unsupervised learning helps discover subword units like phonemes and syllables and build models for under-resourced languages, i.e., languages for which only a few hours of data are available.
Semi-supervised learning is a combination of supervised and unsupervised learning. Semi-supervised models use small amounts of labeled training data along with large quantities of unlabeled training data to overcome the disadvantages of both supervised and unsupervised ML.
This type of learning uses high-quality transcriptions and annotations on a small portion of the data to provide a strong reference model that is used for the rest of the data. However, the effectiveness of this method depends on the quality of the model created on the labeled data.
Types of Audio Labeling for Audio Classification
As established, for machine learning models to respond accurately to audio, they must be trained to distinguish between audio and speech patterns. Like all other annotation types, audio annotation requires human judgment to accurately tag and label the audio data. There are a few ways you can label audio data for classification.
Audio Transcription
In audio transcription, we convert audio/speech recordings to written text while correctly assigning labels to the words and phrases. We then use these as input for natural language processing (NLP) models. In addition, classifying audio for audio transcription helps create transcripts and subtitles of recordings or other audio content.
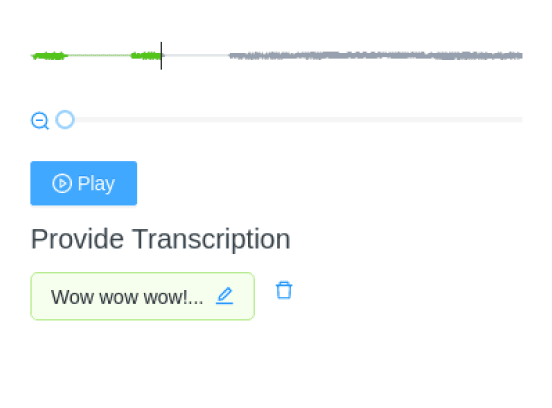
Audio transcription labeling
Sound Event Detection
Labeling data for Sound Event Detection (SED) is done by annotating the sound events and their temporal start and end times. Sound event detection use cases include fast retrieval of audio clips in recordings and unobtrusive monitoring of heartbeats in healthcare devices.
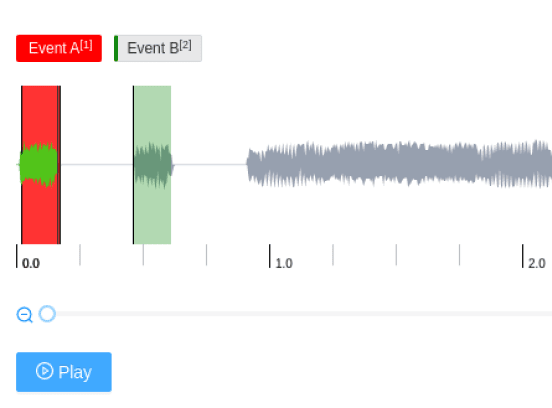
Sound event detection labeling
Speaker Diarization
Speaker diarization labeling involves dividing an input audio stream into homogeneous segments according to the speaker's identity. Speaker diarization increases audio transcript readability and helps identify speakers in audio recordings.
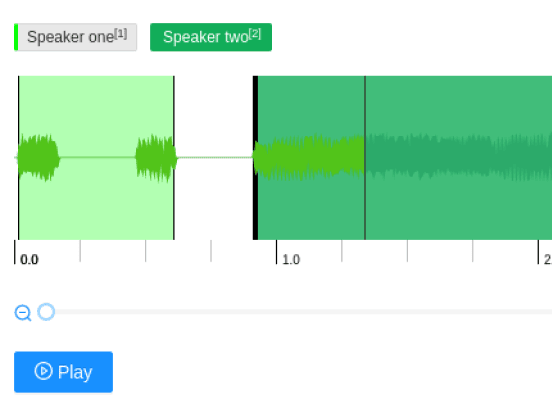
Speaker diarization labeling
Sentiment/Intent Classification
Labeling audio data for intent or sentiment classification involves listening to an audio file and classifying the file's topic based on specific intents. Sentiment analysis can help businesses analyze customer emotions and general sentiments about their products.
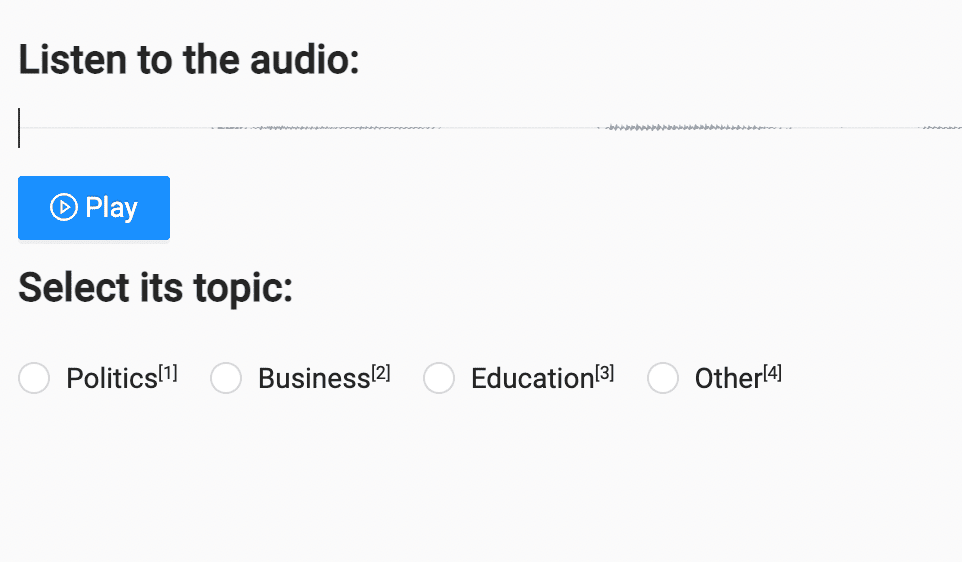
Sentiment classification labeling
Open Source vs. Enterprise: Choosing an Audio Labeling Tool for Your Audio Classification Project
When looking for an audio labeling tool for an audio classification project, there are several factors to consider—the primary one being which tool to use. Several open-source and enterprise tools exist to solve this problem, but making a choice requires several considerations.
Open-Source Tools for Audio Classification: Pros and Cons
Open-source tools offer several advantages, such as:
- Flexibility: Open-source tools are flexible and can be easily customized to fit specific needs.
- Cost-effectiveness: Open-source audio labeling products typically feature lower license fees or sometimes none at all when compared to their enterprise counterparts.
- High-quality software: Open-source tools are based on open standards that provide high performance and compatibility with other software solutions and IT systems.
Despite the advantages, going the open-source route for audio labeling requires thoughtful discussions about features and priorities. With a great level of flexibility comes an increased responsibility for managing the systems and pipelines of the open-source tool. Some open-source tools also have inadequate documentation and low community support, which might hurt your product.
Enterprise Tools for Audio Classification: Pros and Cons
On the other hand, enterprise systems offer advantages such as:
- Extensive customer support: Enterprise software provides comprehensive support from the companies who develop them in addition to binding service-level agreements. So if you experience any issues, you can reach out to the service provider.
- High-quality software: Most enterprise software is developed with high-quality and robust functionality. There's also a focus on user experience and ease of use.
- Reliability: In enterprise software, the responsibility for managing the software, pushing updates, and providing security patches are in the hands of the company that created the software. So you can eliminate a whole host of issues.
Choosing enterprise open-source tools also comes with disadvantages. For most enterprise audio classification software, you will need to purchase a license for use, which will permit you to use the software. You also have to consider ongoing maintenance fees and the cost of scaling and upgrades. Additionally, enterprise software cannot be easily customized to suit the needs of your business.
Both open and closed source have their pros and cons. A good option is a mix of open source and enterprise, where organizations can test the open-source version first as a sort of "proof of concept" before investing in the enterprise version. This option allows you to harness the benefits of open source with relatively few risks.
How to Use Label Studio’s Open-Source Audio Classification Tool
Label Studio is an open-source data labeling tool for annotating audio, text, images, videos, and time series data. It features:
- Pre-built templates for audio/speech labeling tasks—including audio transcription, automatic speech recognition, intent classification, signal quality detection, and speaker segmentation
- Labeling setup for conversational AI projects like coreference resolution, response generation, and selection
- Support for all popular audio formats (wav, aiff, mp3, au, flac, m4a, ogg) and cloud data sources
- Easy integration with ML/AI pipelines using webhooks, Python SDK, and APIs
Here’s how to start using the platform:
Step 1: Install Label Studio
Label Studio can be installed on any Windows, MacOSX, or Linux machine running Python 3.6 or later. Follow the instructions here to find out different ways to install Label Studio.
We recommend installing it using a virtual environment (venv or conda) to reduce the likelihood of missing packages or package conflicts. In this guide, we will be using conda to manage the Label Studio installment:
conda create --name label-studio
conda activate label-studio
pip install label-studio
Step 2: Run Label Studio
After you install Label Studio, run it by starting the server using the command below:
label-studio start
Label Studio login screen
Step 3: Create a Project with Its Description
Creating a project in Label Studio
Step 4: Choose a Labeling Template
Choose between different labeling templates (automatic speech recognition, intent classification, signal quality detection, and speaker segmentation).
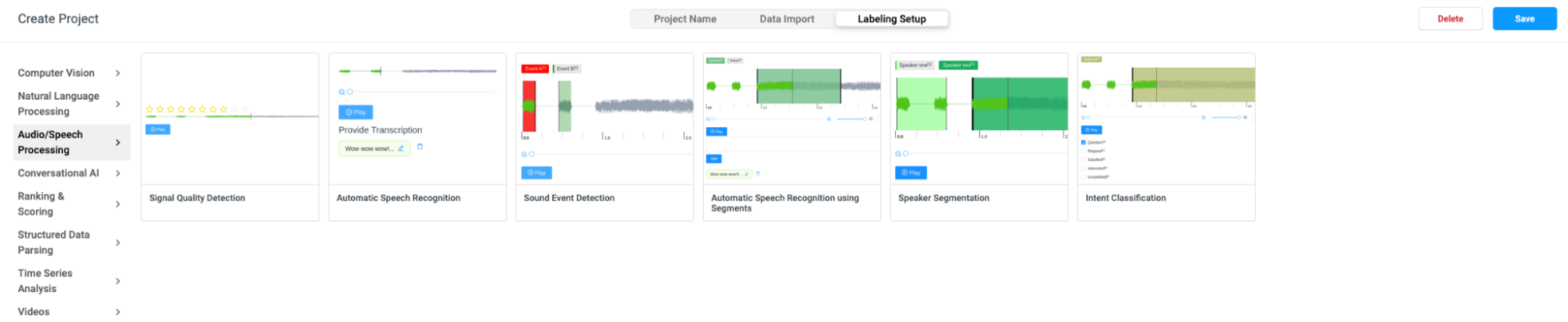
Audio labeling templates in Label Studio
Step 5: Perform Audio Labeling
In this guide, we are performing audio labeling for a speaker segmentation project, as shown below:
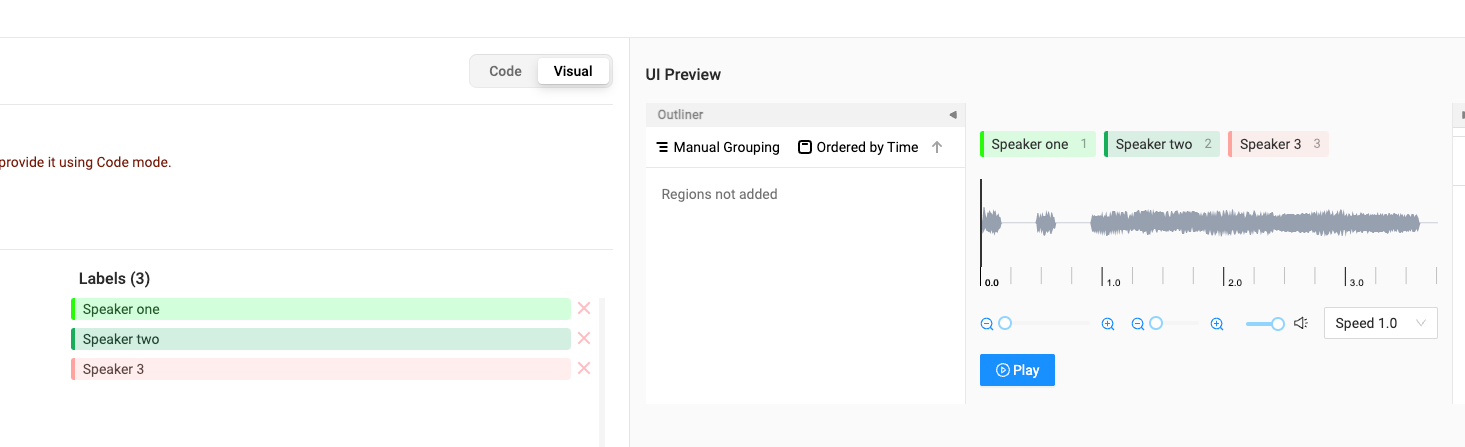
Performing speaker segmentation audio labeling
Step 6: Export the Labeled Data to Your Desired Formats
Finally, we export the labeled data to the JSON format, which is used as input to our machine learning model.
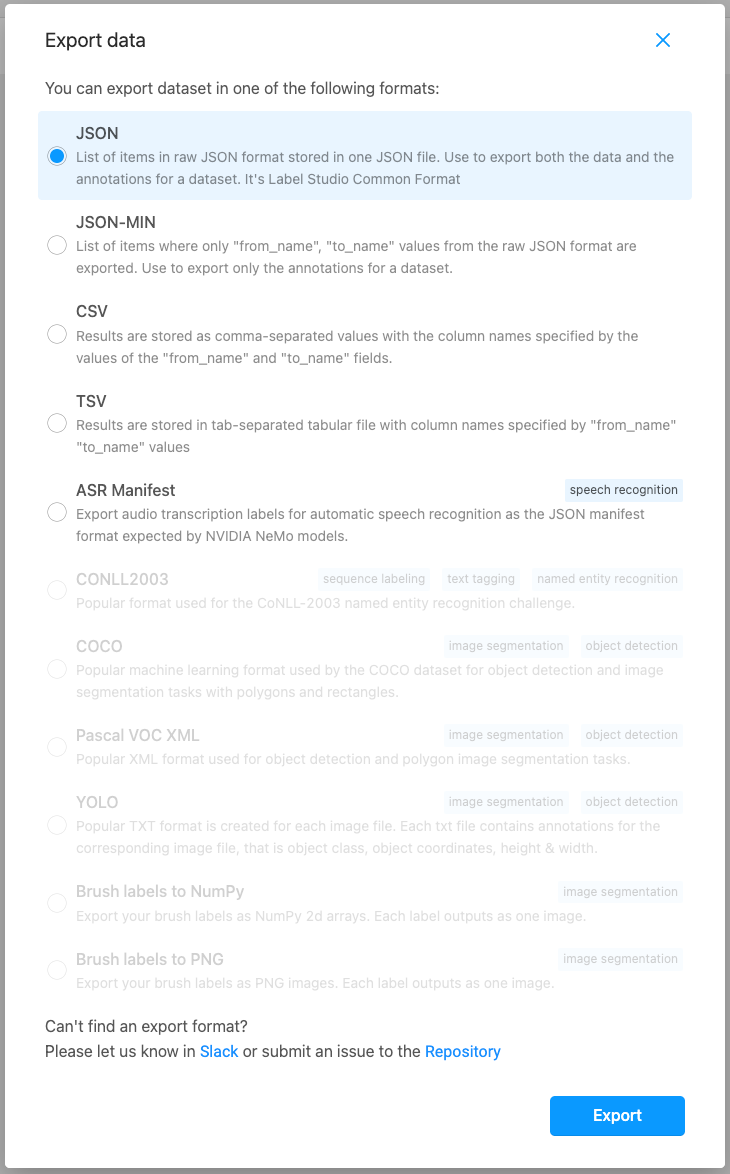
Exporting labeled data
Simplify Your Audio Classification Process with Label Studio
An audio classification project is only as effective as the data it's trained with. Audio classification projects rely on a foundation of high-quality labeled audio data to accurately interpret the meaning and context of human speech, sounds, and emotions.
Label Studio can help simplify your audio classification process by improving your audio labeling. Check out the official documentation to learn and try out Label Studio’s audio/data annotation features in both open-source and enterprise options.
Related Content
-

Understanding Audio Classification: Everything You Need to Know
This article takes a look at audio classification and discusses the various use cases that can benefit from this technique.

Label Studio Team
November 16, 2022
-
How To Choose an Open-source Audio Classification Tool and 6 Options To Use
When choosing an annotation tool for your audio classification project, you need to carefully study its unique features and ensure that it works well with the rest of your stack. Finding the right tool will give you the best value in your audio classification projects.
Label Studio Team
November 9, 2022
-

Improve Amazon Transcribe Audio Transcriptions with Label Studio
Use open source data labeling software Label Studio to improve audio transcriptions of customer support calls, video conference meetings, and other audio recordings.
Label Studio Team
May 10, 2021