External Knowledge: Why Augmented Language Models Need More Than What They’re Trained On
Large language models (LLMs) are built on vast amounts of data, but once training stops, their view of the world freezes in time. They can’t browse the web. They can’t fact-check themselves. And they certainly can’t reason with information they were never trained on in the first place. For teams building production-grade systems, that’s a problem.
The solution? Give the model access to external knowledge.
Rather than relying solely on what's stored in model weights, many modern systems augment LLMs by injecting fresh, relevant context from external sources at the time of generation. This approach not only extends the model’s capabilities, it helps bridge the gap between static training data and dynamic, real-world use.
What Counts as External Knowledge?
In this context, “external knowledge” refers to any data the model wasn’t trained on but can use at inference time. That might include:
- Company-specific documentation
- Real-time financial or market data
- Knowledge bases and internal wikis
- Legal or scientific references
- Previously unseen customer interactions
This data doesn’t need to be massive. It just needs to be accessible at the right time and relevant to the task at hand.
Retrieval Augmented Generation (RAG) in Practice
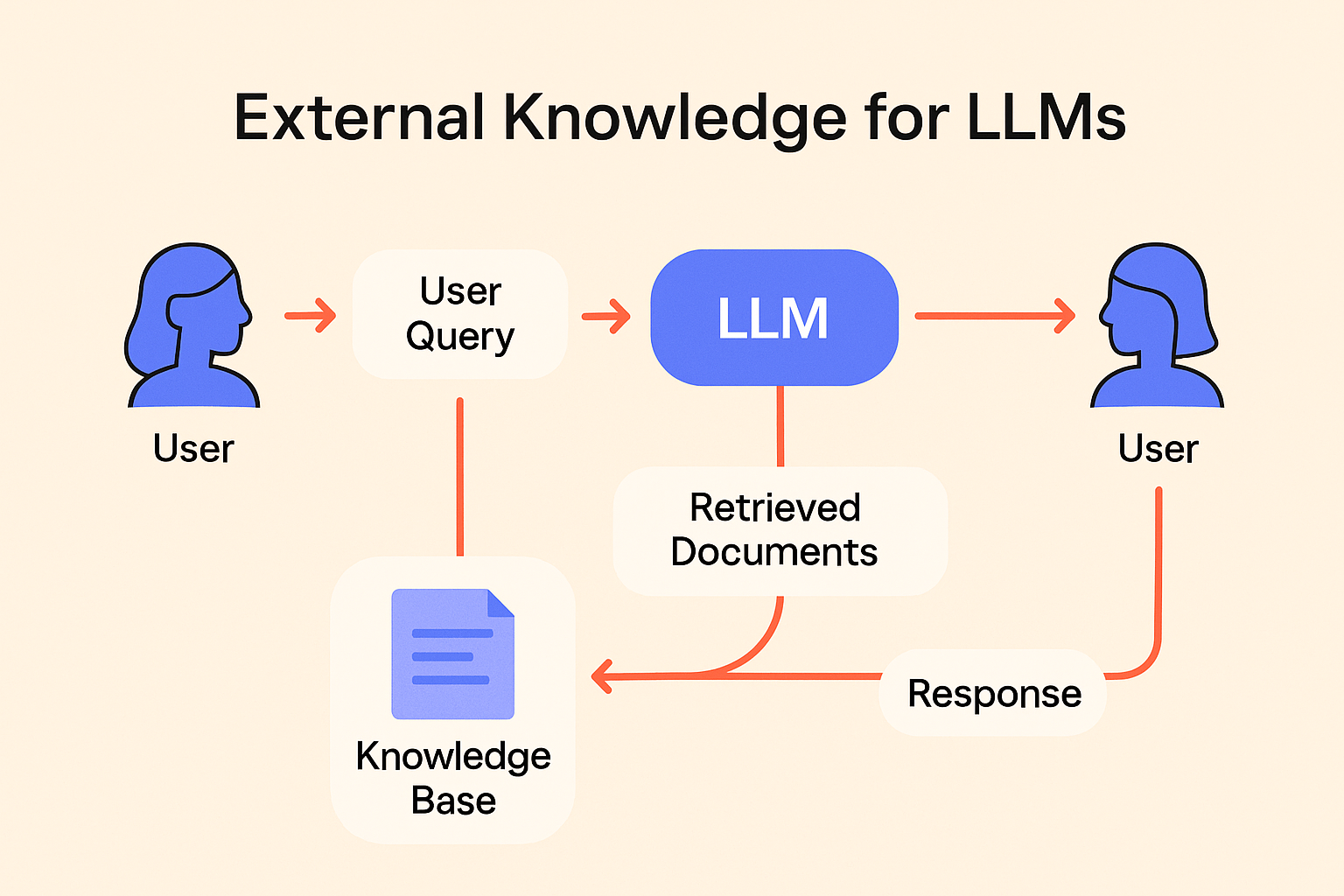
The most common way to integrate external knowledge is through retrieval augmented generation (RAG). With RAG, you introduce a retrieval step before the LLM generates a response. A user prompt is used to search a document store, pull in relevant passages, and feed them to the model as part of the prompt context.
This approach has taken off in applications like:
- Customer support assistants that pull knowledge base articles
- Legal research tools that cite source material
- AI tutors that reference curriculum documents
- Enterprise copilots that query internal systems for answers
In each of these, the model’s strength isn’t memorization, it’s the ability to read, interpret, and respond to retrieved information in real time.
When and Why External Knowledge Matters
Using external knowledge is more than just a feature add, it’s often necessary for safety, accuracy, and utility.
- LLMs hallucinate because they’re forced to guess when they don’t know something.
- They go stale because their training data becomes outdated.
- They miss edge cases because no model can see every possibility.
By grounding generation in external knowledge, you get:
- Better alignment with real-world facts
- More control over the model’s behavior
- Flexibility to update knowledge without retraining
This is especially important in regulated industries (like healthcare or finance) where traceability and transparency are non-negotiable.
Tools and Components That Make This Work
To build with external knowledge, teams often rely on:
- Vector databases to semantically index documents (e.g., Weaviate, Pinecone)
- Embeddings models to convert text into searchable vectors
- Retrieval pipelines to match queries with the most relevant passages
- Prompt templates that blend user input with retrieved context
How External Knowledge Fits Into the Bigger Picture
External knowledge is just one part of a broader movement toward augmented language models, systems that combine LLMs with memory, tools, feedback, and control mechanisms.
If you're new to the space or want to understand where retrieval fits in, we recommend starting with our foundational guide: A Practical Guide to Augmented Language Models.
Frequently Asked Questions
Frequently Asked Questions
How is external knowledge different from fine-tuning?
Fine-tuning changes the model’s weights. Using external knowledge doesn’t retrain the model, it gives it more context at inference time.
Can I use external knowledge without building a RAG pipeline from scratch?
Yes. Frameworks like LangChain, LlamaIndex, and Haystack make it easier to implement RAG without building every component yourself.
What if my documents are private or sensitive?
You can store and retrieve knowledge from private, access-controlled sources. Many companies run RAG systems entirely on-premise or in VPC environments.
Will giving a model access to more documents slow it down?
Not necessarily. The retrieval step is designed to be fast and selective. You’re only passing a small set of relevant documents to the model, not your entire database.
Related Content
-
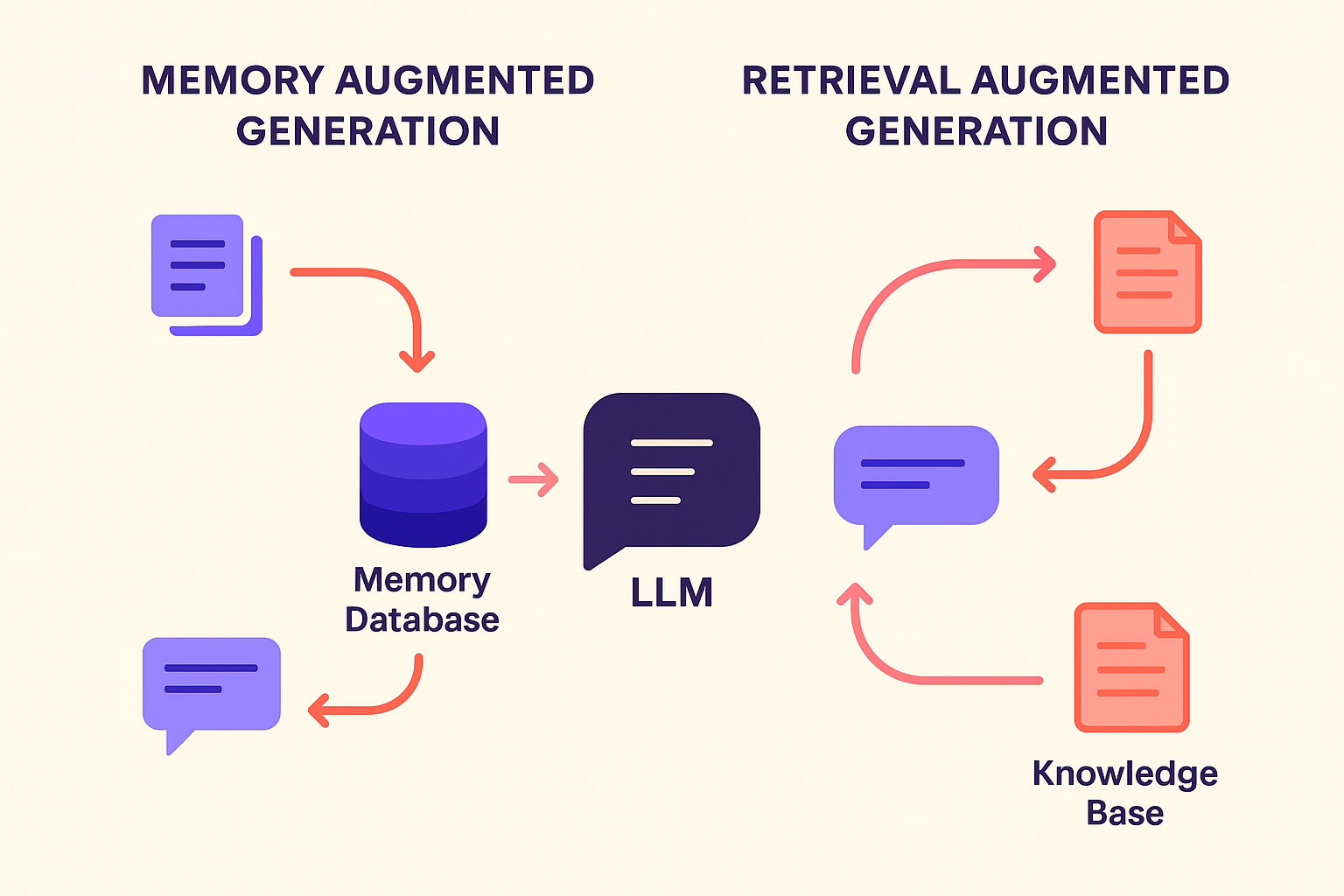
Memory vs Retrieval Augmented Generation: Understanding the Difference
Memory Augmented Generation and Retrieval Augmented Generation both aim to improve LLM outputs, but they solve different problems. In this guide, we unpack how each method works, where they shine, and how teams are using them in real-world systems.
-
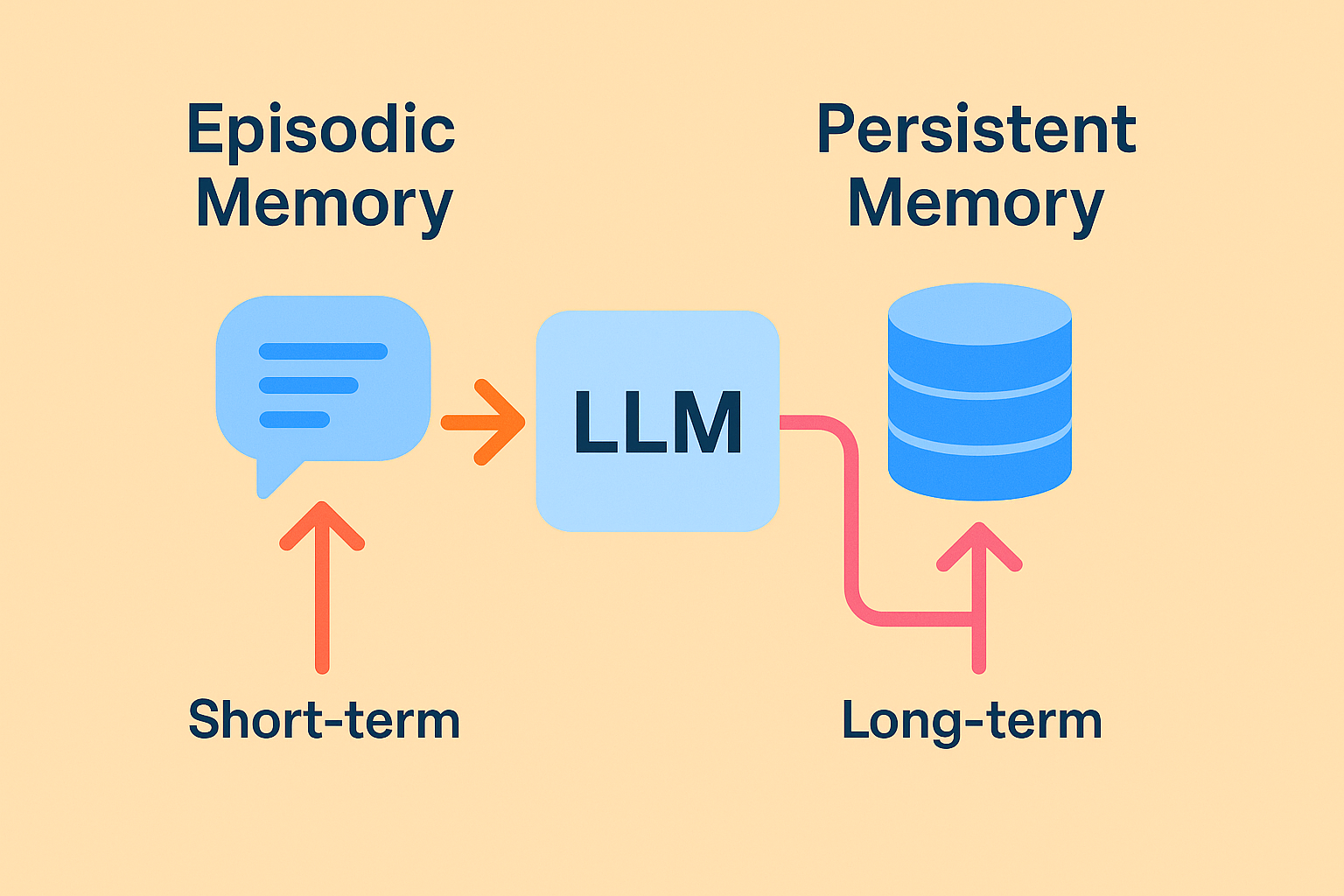
Episodic vs Persistent Memory in LLMs
Episodic and persistent memory offer two distinct ways to manage information in large language models. Knowing when to use each can shape how your system learns, remembers, and interacts.
-

A Guide to Augmented Language Models
Pretrained LLMs are powerful, but they can't access real-time facts, remember past interactions, or use external tools on their own. Augmented language models solve these limitations and in this guide, we’ll explore how.