Memory vs Retrieval Augmented Generation: Understanding the Difference
When large language models (LLMs) struggle to answer questions accurately or maintain consistent context, it’s often because they’re operating with a limited view of the world: no up-to-date facts, no long-term memory, and no sense of what’s been said before. That’s where augmentation strategies come in.
Two of the most common approaches are Retrieval Augmented Generation (RAG) and Memory Augmented Generation (MAG). While they both aim to give LLMs more information, they do so in very different ways and understanding that difference is key to choosing the right approach for your use case.
Retrieval Augmented Generation (RAG): Injecting External Knowledge
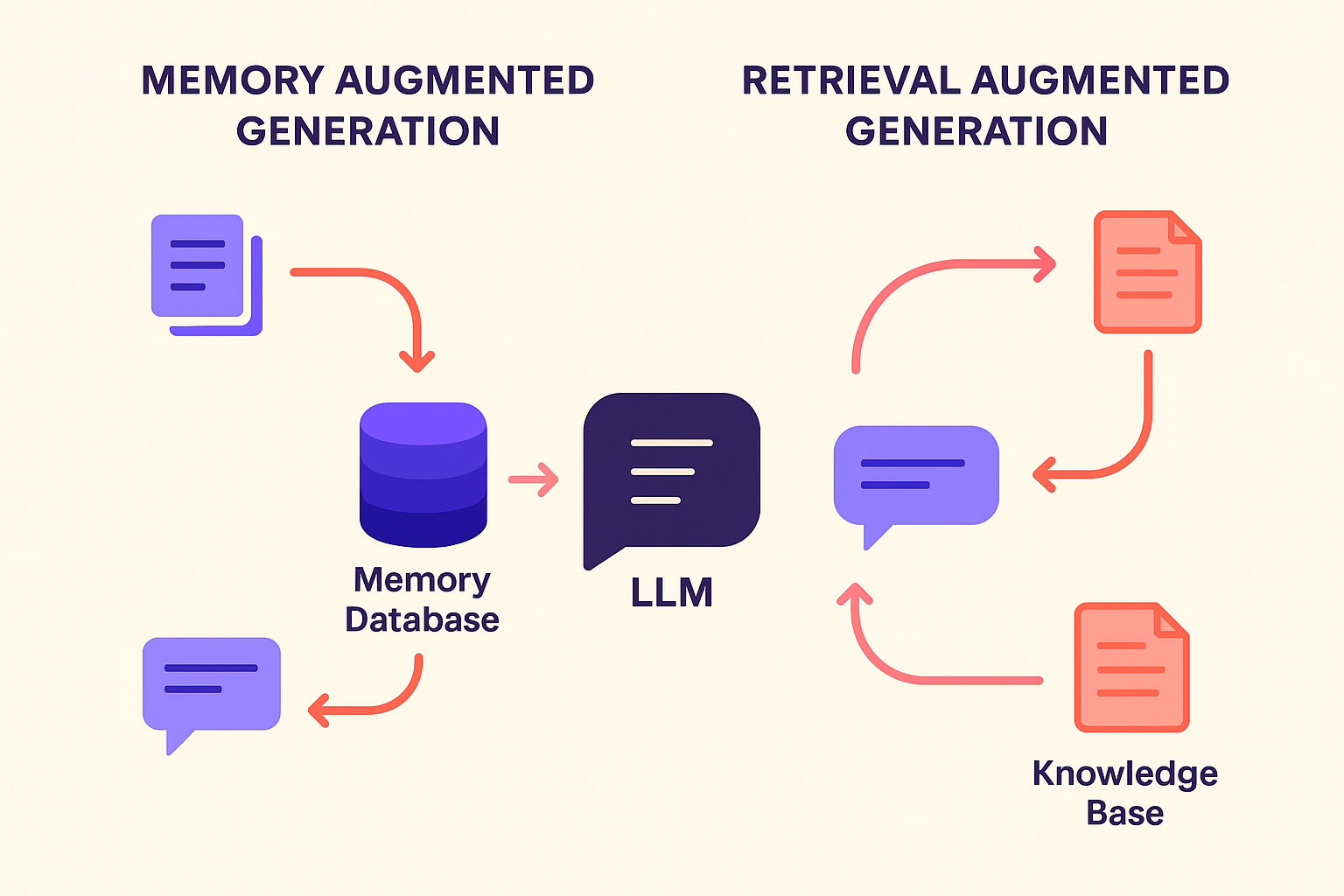
RAG helps LLMs ground their responses by pulling in information from an external knowledge source, like a database, document store, or vector index. Instead of answering based solely on pre-trained weights, the model gets a curated snapshot of relevant context to consider during generation.
Think of it like an open-book test: the model retrieves supporting material just in time, then uses that to generate a more accurate answer.
For example, in a customer support bot, RAG might pull from internal documentation to help the model answer a product question. The model doesn’t need to “remember” the answer, it just needs to know how to read.
RAG is especially useful when:
- You need answers tied to a large or frequently changing dataset
- Hallucinations are a concern
- You want to keep the LLM general-purpose, but supplement it with domain-specific facts
Memory Augmented Generation (MAG): Preserving Interaction History
MAG, by contrast, gives models the ability to remember things across interactions. Rather than retrieving facts from an external source, MAG recalls what’s already happened in previous conversations or tasks, the model’s own past prompts, responses, or annotations.
It’s not about fetching encyclopedic knowledge. It’s about simulating memory, continuity, and personalization.
In practice, this might look like a tutoring assistant that remembers a student’s past questions, or a product recommendation engine that recalls user preferences over time. MAG creates a sense of long-term awareness—even if the underlying model itself is stateless.
MAG makes the most sense when:
- You want models to behave consistently over time
- Personalization or continuity is key
- You're building multi-turn or long-running interactions
Same Goal, Different Paths
Both RAG and MAG are ways to work around the limitations of language models. Pretrained models are powerful, but they’re static: they can’t access current facts or remember what happened yesterday. Augmentation fills in those gaps, but whether you reach for memory or retrieval depends on the kind of “knowledge” your system needs.
If your problem is about facts, go with retrieval.If your problem is about context, go with memory.
In many real-world systems, teams blend both: using RAG for factual accuracy and MAG for conversational continuity.
Frequently Asked Questions
Frequently Asked Questions
How are RAG and MAG different from fine-tuning?
Fine-tuning bakes knowledge into the model weights, whereas RAG and MAG provide dynamic context at runtime. They’re more flexible and often more efficient to implement.
Does MAG store everything a model sees?
Not usually. Most systems implement a selective memory strategy, only storing key moments, user feedback, or specific inputs and outputs.
What tools support these approaches?
Frameworks like LangChain and LlamaIndex make it easier to build both RAG and MAG pipelines. Vector databases (like Pinecone or Weaviate) are common in RAG setups, while memory systems often use structured stores or semantic memory layers.
Related Content
-
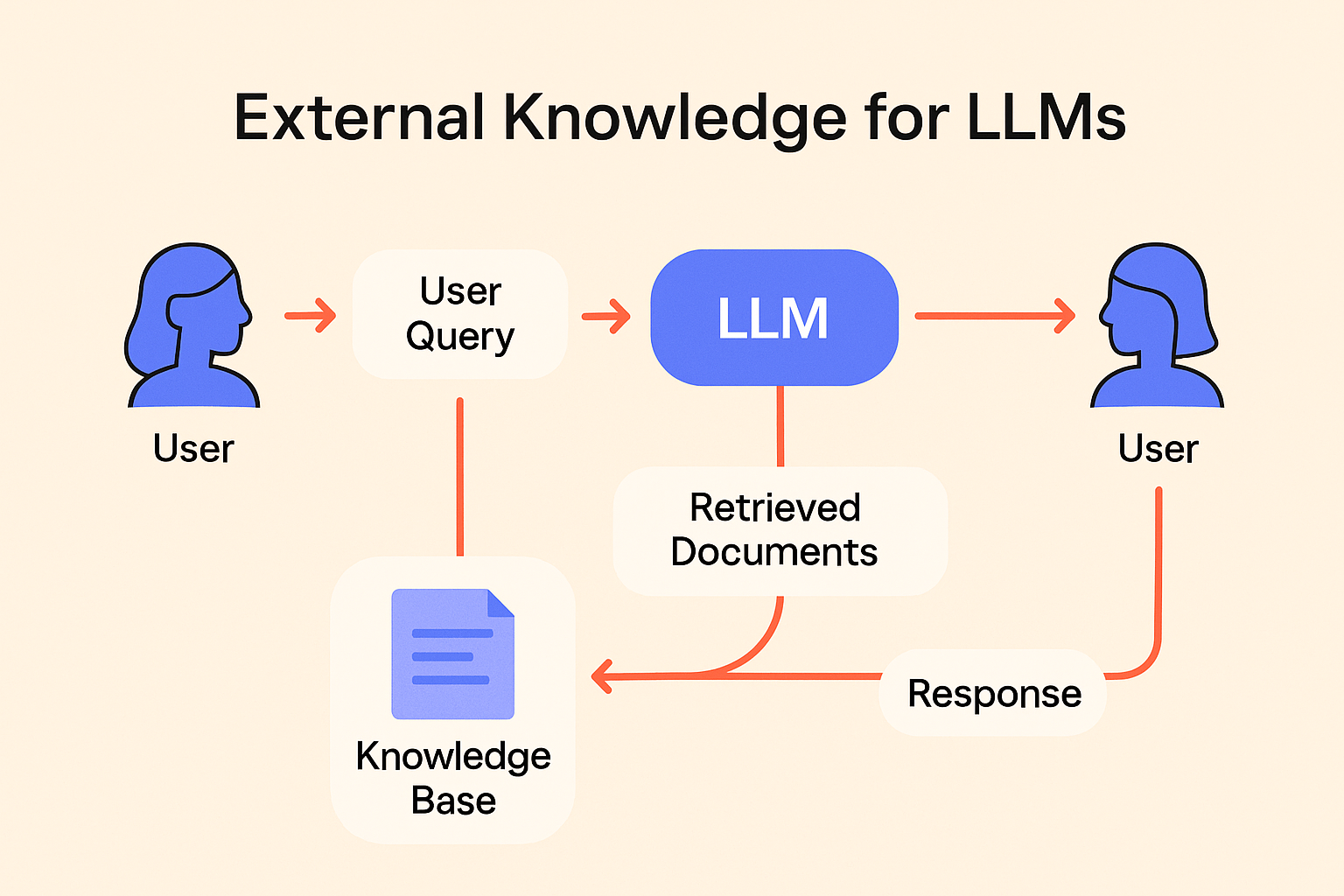
External Knowledge: Why Augmented Language Models Need More Than What They’re Trained On
LLMs don’t know everything, and that’s a feature, not a flaw. By adding external knowledge, you can keep models accurate, relevant, and grounded in real-world data.
-
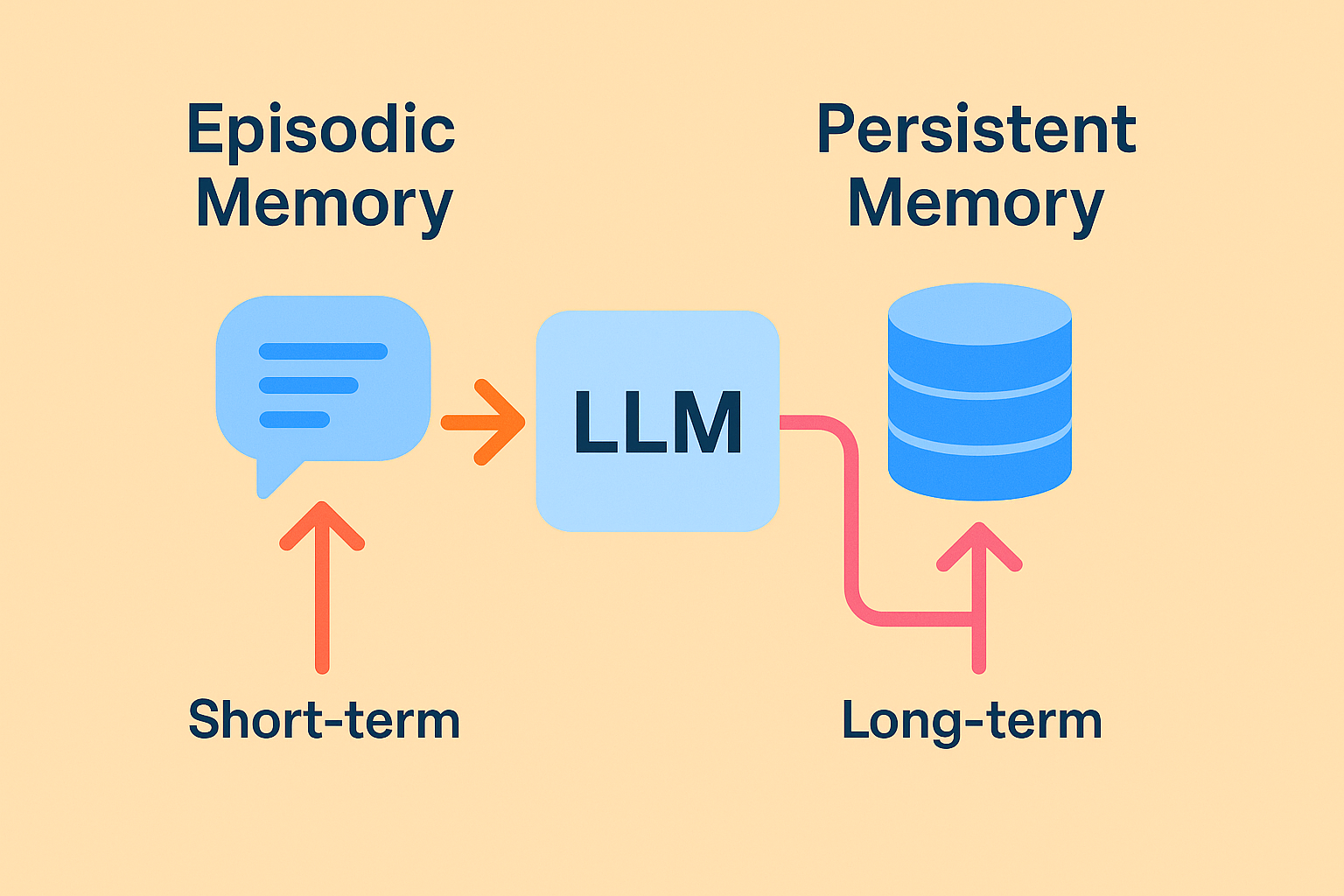
Episodic vs Persistent Memory in LLMs
Episodic and persistent memory offer two distinct ways to manage information in large language models. Knowing when to use each can shape how your system learns, remembers, and interacts.
-

A Guide to Augmented Language Models
Pretrained LLMs are powerful, but they can't access real-time facts, remember past interactions, or use external tools on their own. Augmented language models solve these limitations and in this guide, we’ll explore how.