Episodic vs Persistent Memory in LLMs
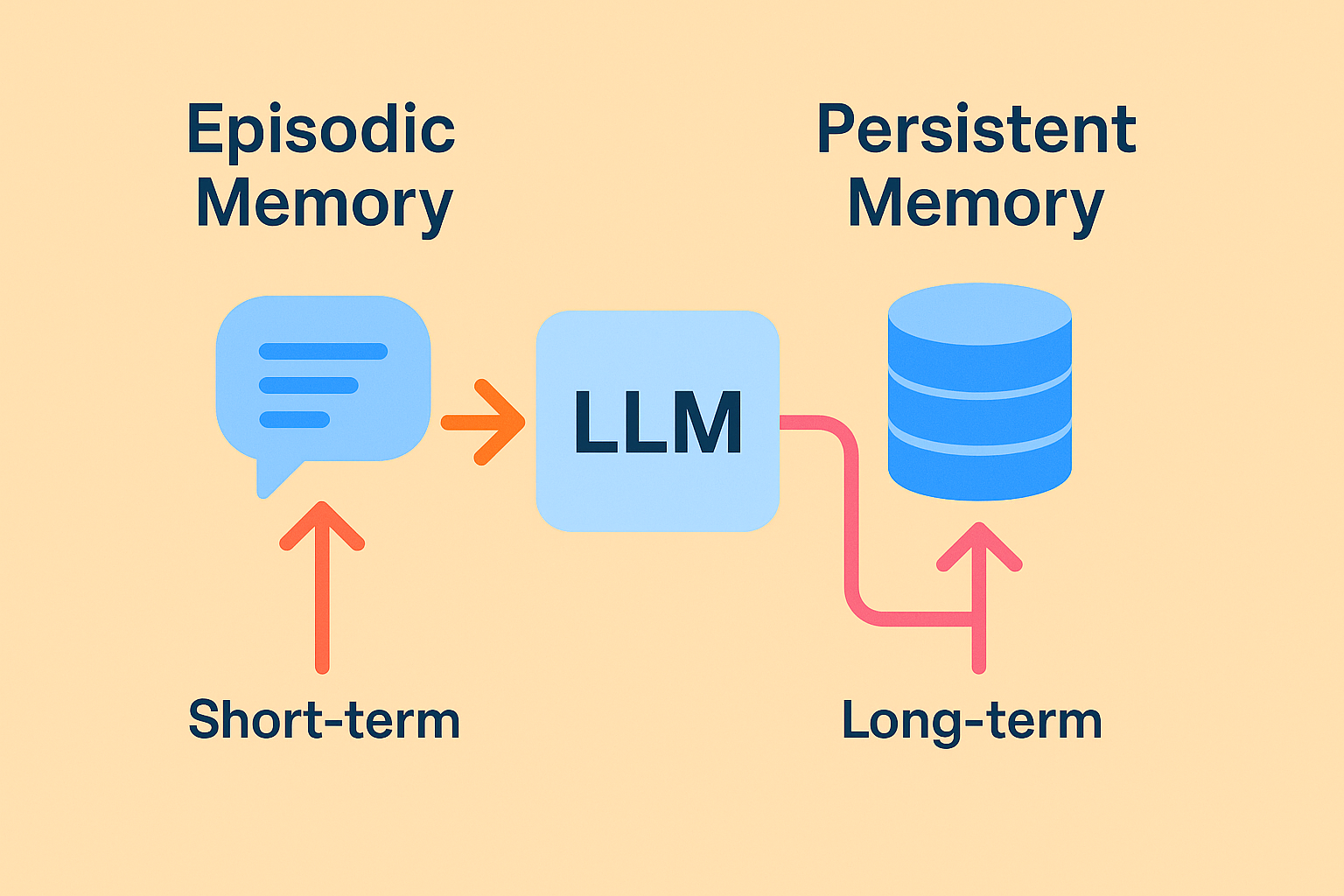
Large language models (LLMs) are great at generating fluent, human-like text. But to be truly useful in production systems, especially ones that span multiple sessions, workflows, or users, they need some form of memory. That’s where episodic memory and persistent memory come into play.
Both enable an LLM to "remember" prior information, but they do so in very different ways. Understanding the distinction is key to building more intelligent, context-aware applications.
TL;DR
- Episodic memory is short-term session data.
- Persistent memory is long-term external storage.
- Persistent memory maintains context across user sessions.
- Use episodic memory for single-session tasks.
- Use persistent memory for continuity.
- Systems combine both for best results.
What Is Episodic Memory in LLMs?
Episodic memory refers to short-term or session-based memory. It's like the model's working memory in a single conversation or task. It tracks recent dialogue turns or instructions but forgets everything once the session ends.
This type of memory is often maintained via context windows or attention over previous tokens. Tools like chat histories or conversation buffers in RAG pipelines help simulate this behavior.
Example: A customer support chatbot that keeps track of the current conversation, understanding that "it" refers to a refund request made two messages ago.
Because episodic memory is limited to the current session, it doesn’t require long-term storage. It’s fast, lightweight, and works well when tasks don’t need to persist across user sessions.
What Is Persistent Memory in LLMs?
Persistent memory is long-term. It’s stored externally—often in a vector database, knowledge base, or fine-tuned model checkpoint—and survives across sessions or user interactions.
Persistent memory gives an LLM access to facts, user preferences, or decisions made days or weeks ago. It creates a more consistent, personalized, and adaptive system. Unlike episodic memory, this type of memory requires infrastructure: storage layers, retrieval mechanisms, and often user-level access control.
Example: An AI writing assistant that remembers your preferred tone, citation style, or previous projects over time, even after you log out and return days later.
Persistent memory can take several forms:
- Embedding stores: Indexed knowledge or historical interactions
- Fine-tuned weights: Custom-trained models that internalize domain expertise
- External databases: Structured or semi-structured memory stores linked via API
Persistent vs Episodic: Why the Distinction Matters
At a technical level, the key difference lies in lifetime and accessibility:
- Episodic memory helps in maintaining coherent conversations and task flows in real time.
- Persistent memory enables a model to learn from the past and adapt behavior over long timeframes.
From a design perspective, the choice between them affects latency, cost, and complexity. Episodic memory is fast and ephemeral. Persistent memory requires storage, retrieval, and sometimes user privacy mechanisms.
For example, a healthcare assistant might use episodic memory to hold a list of symptoms described during a session, while drawing from persistent memory to reference previous diagnoses or medications across visits.
When to Use Each Memory Type
Use episodic memory when:
- You need lightweight, real-time recall within a conversation or task
- Personalization isn't required beyond the current session
- Cost and latency need to be minimal
Use persistent memory when:
- Your application spans multiple sessions or users (e.g., education, CRM, medical systems)
- You need to build up knowledge over time
- You require continuity or personalization at scale
In practice, many robust systems use both types of memory—short-term memory for coherence and responsiveness, long-term memory for personalization and continuity.
Real-World Implementation Patterns of each memory type
- Retrieval-Augmented Generation (RAG): Often includes episodic memory from the current session + persistent memory from a vector store.
- Fine-tuning with memory traces: Stores long-term preferences or task-specific corrections in persistent memory (via continual fine-tuning or prompt injection).
- Agentic LLMs: Tools like AutoGPT or LangGraph use persistent memory for world models, goals, and logs, while episodic memory helps manage current sub-tasks.
Check out our Learning Center guide to RAG for deeper coverage of how persistent memory is handled in retrieval workflows.
Final Thoughts
Memory isn't a monolith in LLM systems. Understanding the trade-offs between episodic and persistent memory can help you build more useful, reliable applications. Whether you’re fine-tuning for a niche domain or building a general-purpose AI assistant, how your model remembers determines how well it performs.
To explore more memory and interaction models, visit our related guides on Agentic LLM Design and LLM Evaluation Strategies. For enterprise software adoption, see our breakdown of top AI evaluation platforms.
FAQs about Persistent and Episodic Memory in LLMs
Frequently Asked Questions
What’s the main difference between episodic and persistent memory in LLMs?
Episodic memory is short-term and scoped to a single session. Persistent memory is long-term and survives across sessions or interactions.
Does persistent memory pose privacy concerns?
It can, especially when storing user-specific data. Systems should implement appropriate access controls, logging, and data retention policies.
Do all LLMs support persistent memory natively?
No. Persistent memory often requires additional infrastructure, most base models don’t come with this functionality out of the box.
How do vector databases enable persistent memory in large language models?
Vector databases act as an external long-term storage layer where historical interactions and domain-specific knowledge are indexed as mathematical embeddings. When a model needs to recall past context across different user sessions, it retrieves these highly relevant embeddings to seamlessly inform its current response. This specialized infrastructure allows language models to maintain deep consistency and personalization at scale without requiring constant retraining.
What role does persistent memory play in Retrieval-Augmented Generation (RAG)?
In RAG workflows, persistent memory provides the foundational, long-term knowledge base that a language model queries to generate highly accurate and context-aware responses. By accessing external document stores or vector databases, RAG systems can instantly pull established facts and historical user preferences to augment the short-term session data. This powerful combination ensures that AI applications deliver reliable answers while continually adapting to new information over time.
How does persistent memory solve the limitations of a standard context window?
A standard context window acts as a short-term workspace that permanently forgets all inputted information once a user session ends or the strict token limit is reached. Implementing persistent memory overcomes this bottleneck by storing crucial insights, rules, and user preferences in an external database for future retrieval. This architecture ensures that valuable context is retained indefinitely which reduces latency and computational costs during subsequent interactions.
Why is persistent memory essential for building agentic LLM workflows?
Agentic workflows require language models to autonomously execute complex, multi-step tasks, which demands a continuous understanding of overarching goals and past actions. Persistent memory allows these autonomous agents to log their progress, reference historical decisions, and adapt their behavior across multiple distinct sessions without losing their train of thought. Without this long-term retention mechanism, AI agents would lack the environmental awareness and consistency needed for reliable enterprise operations.
Related Content
-
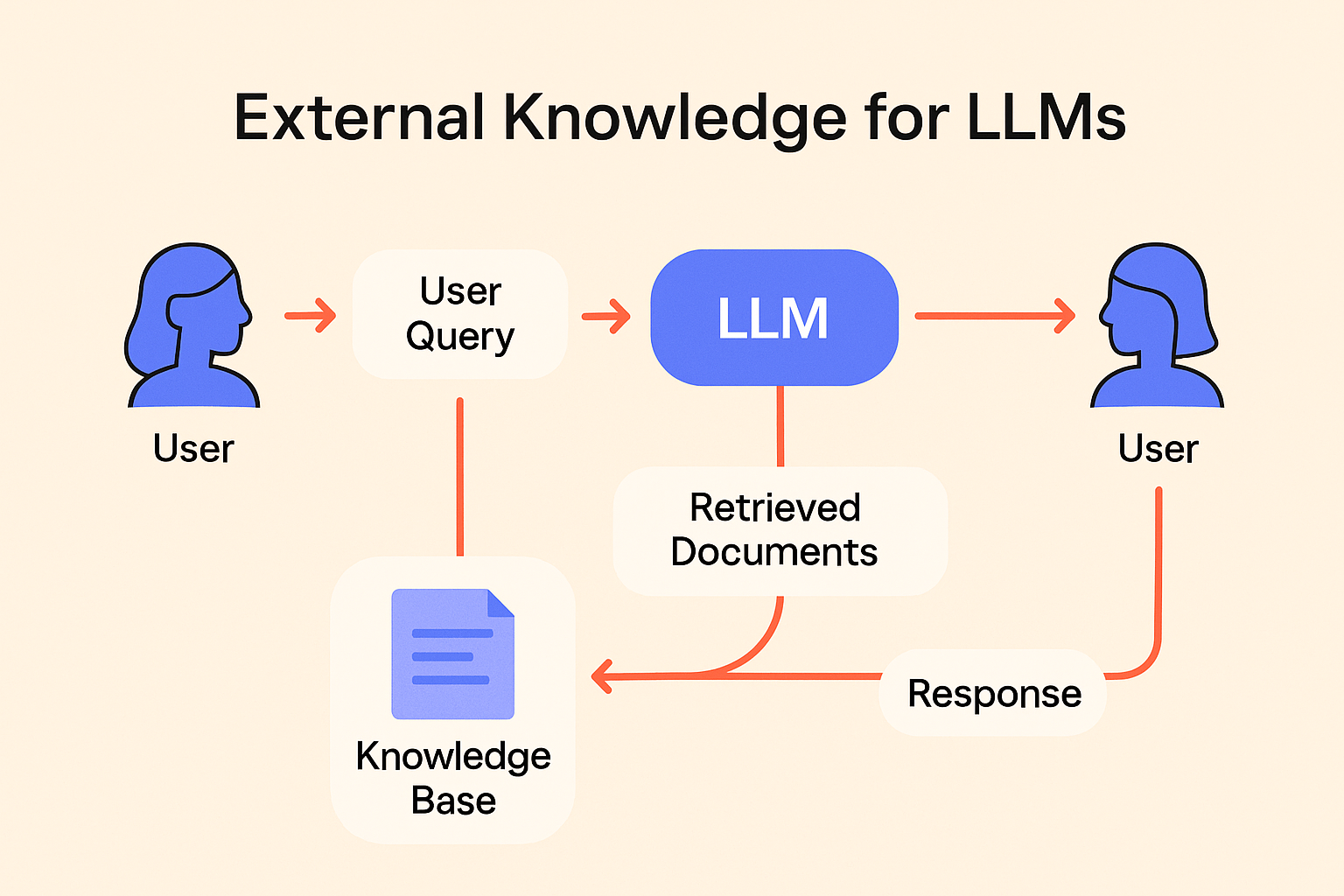
External Knowledge: Why Augmented Language Models Need More Than What They’re Trained On
LLMs don’t know everything, and that’s a feature, not a flaw. By adding external knowledge, you can keep models accurate, relevant, and grounded in real-world data.
-
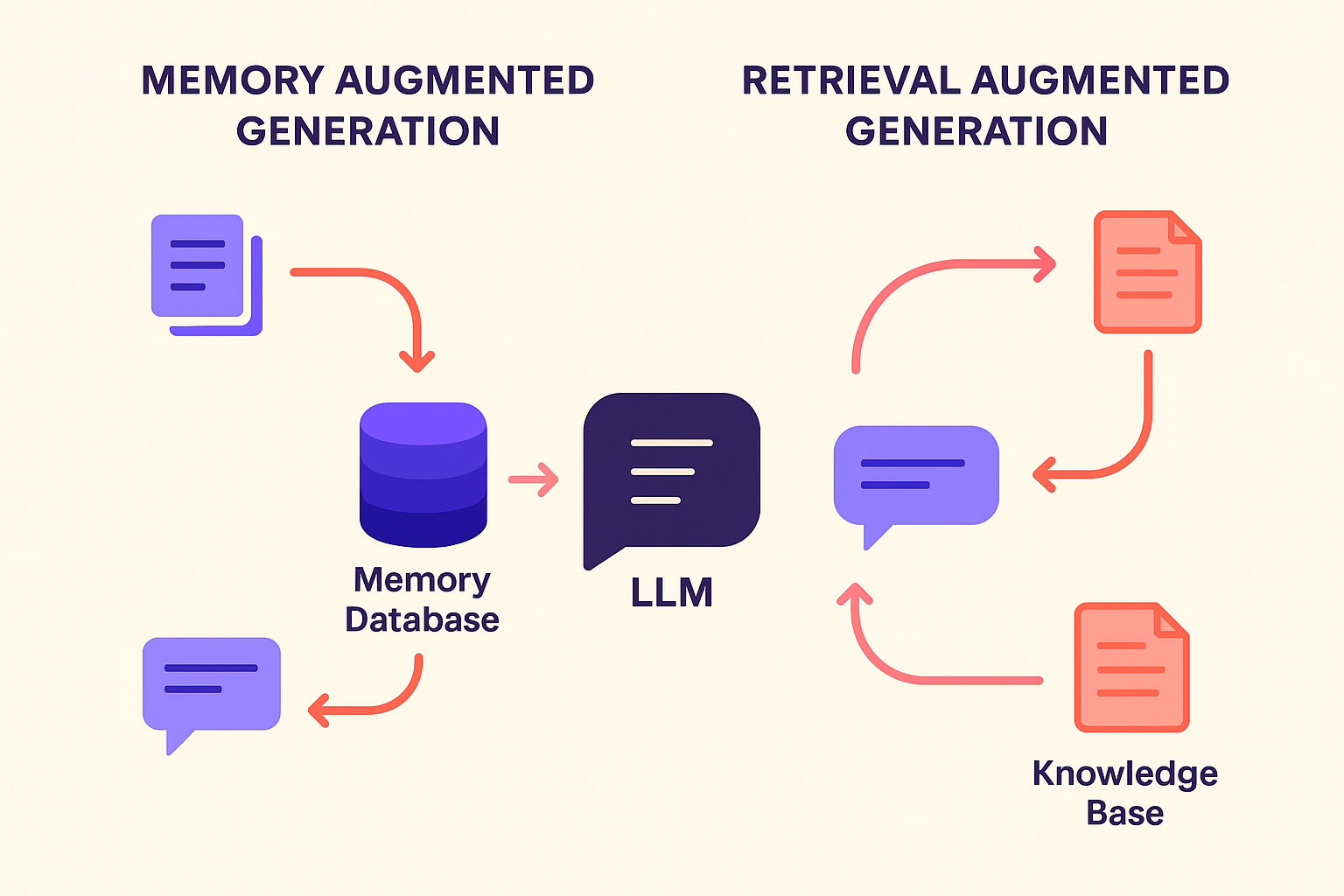
Memory vs Retrieval Augmented Generation: Understanding the Difference
Memory Augmented Generation and Retrieval Augmented Generation both aim to improve LLM outputs, but they solve different problems. In this guide, we unpack how each method works, where they shine, and how teams are using them in real-world systems.
-

A Guide to Augmented Language Models
Pretrained LLMs are powerful, but they can't access real-time facts, remember past interactions, or use external tools on their own. Augmented language models solve these limitations and in this guide, we’ll explore how.