Contextual Scrolling
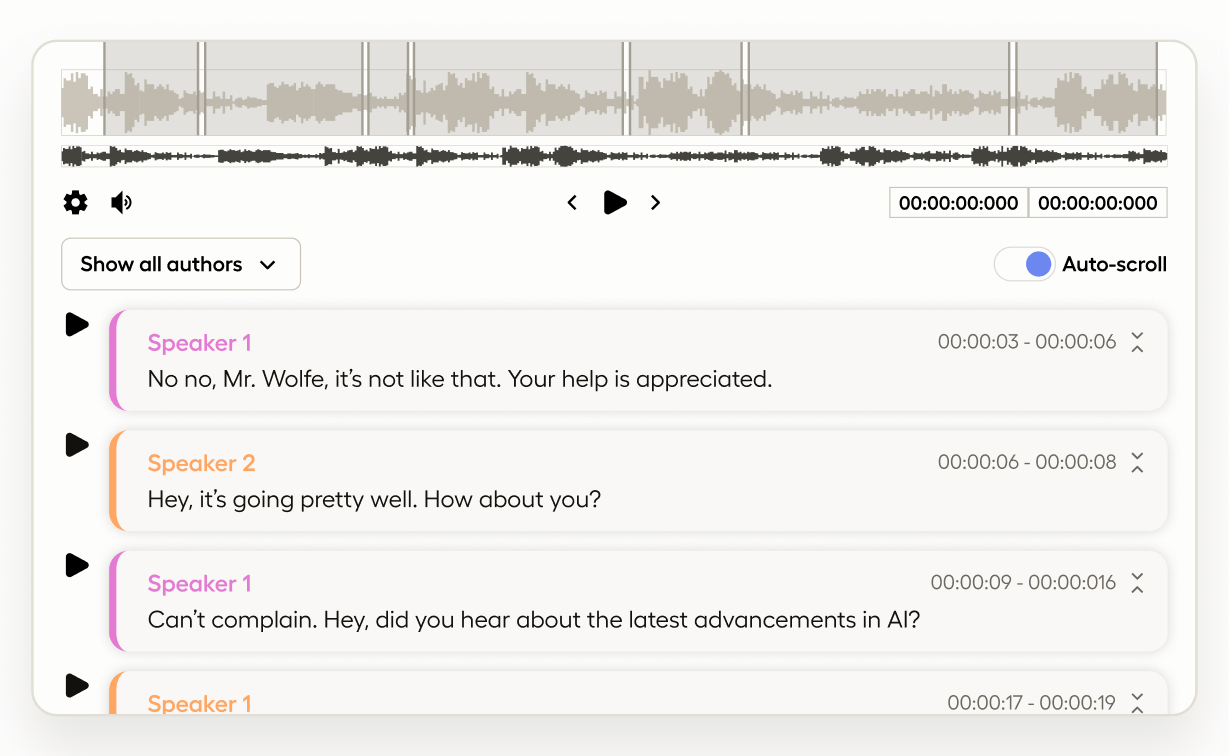
Playback synchronization between audio and corresponding paragraph segments provides you with enhanced context and control resulting in high-quality annotated datasets and increased productivity when performing conversational analysis.
Enterprise
If you're managing more complex or high-volume audio labeling projects, Label Studio Enterprise includes an advanced audio transcription interface built to support faster, more precise annotation at scale.
See our new Multi-Channel Audio Transcription template and learn more in A New Audio Transcription UI for Speed and Quality at Scale (blog post).
Labeling Configuration
<View>
<Audio name="audio" value="$url" sync="text"></Audio>
<View>
<Header value="Transcript"/>
<Paragraphs audioUrl="$audio" contextScroll="true" sync="audio" name="text" value="$text" layout="dialogue" textKey="text" nameKey="author" granularity="paragraph"/>
</View>
<View>
<Header value="Sentiment Labels"/>
<ParagraphLabels name="label" toName="text">
<Label value="Positive" background="#00ff00"/>
<Label value="Negative" background="#ff0000"/>
</ParagraphLabels>
</View>
</View>About the labeling configuration
All labeling configurations must be wrapped in View tags.
You can add a header to provide instructions to the annotator:
<Header value="Listen to the audio:"></Header>Use the Audio object tag to specify the type and the location of the audio clip. In this case, the audio clip is stored with a url key. Audio paired with the Paragraphs with ‘contextScroll’ set to true and sync set to audio. Additionally name of the paragraph tag should have the textKey value from the audio tag:
<Audio name="audio" value="$url" sync="text"></Audio>
<Paragraphs audioUrl="$audio" contextScroll="true" sync="audio" name="text" value="$text" layout="dialogue" textKey="text" nameKey="author" granularity="paragraph"/>Use the Paragraph Labels control tag with the Label tag to annotate sections of the paragraph transcriptions.
<ParagraphLabels name="label" toName="text">
<Label value="Positive" background="#00ff00"/>
<Label value="Negative" background="#ff0000"/>
</ParagraphLabels>Transcription Data
The transcription data should have a start and either an end or a duration
{
"text": [
{
"end": 1.5,
"text": "Dont you hate that?",
"start": 0,
"author": "Mia Wallace"
},
{
"text": "Hate what?",
"start": 1.5,
"author": "Vincent Vega:",
"duration": 3
},
{
"end": 7,
"text": "Uncomfortable silences. Why do we feel its necessary to yak to feel comfortable?",
"start": 4.5,
"author": "Mia Wallace:"
},
{
"end": 10,
"text": "I dont know. That's a good question.",
"start": 8,
"author": "Vincent Vega:"
},
],
},Enhance this template
This template can be enhanced in many ways.
Add additional data points
A number of tags can be added to this template to add more data points to the annotation. Here we added Choices and TextArea tags to give speaker context and a text responsce to the transcription:
<View>
<Choices name="speakers" toName="audio" choice="multiple" showInline="true">
<Choice value="speaker_1"/>
<Choice value="speaker_2"/>
</Choices>
</View>
<View>
<Header value="Provide your response:"/>
<TextArea name="response" toName="text"/>
</View>