Speaker Diarization
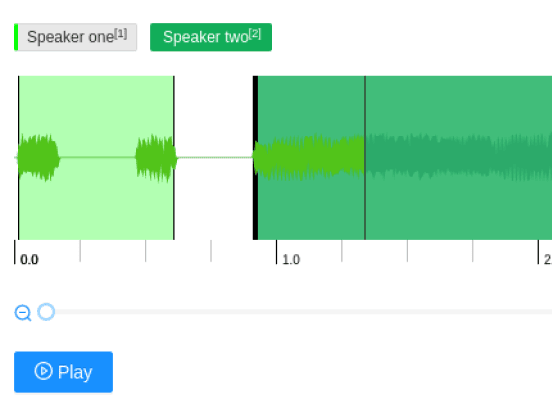
When preparing audio transcripts or training a machine learning model to differentiate between different speakers, use this template to perform speaker segmentation and label different regions of an audio clip with different speakers.
Enterprise
If you're managing more complex or high-volume audio labeling projects, Label Studio Enterprise includes an advanced audio transcription interface built to support faster, more precise annotation at scale.
See our new Multi-Channel Audio Transcription template and learn more in A New Audio Transcription UI for Speed and Quality at Scale (blog post).
Interactive Template Preview
Labeling Configuration
<View>
<Labels name="label" toName="audio" zoom="true" hotkey="ctrl+enter">
<Label value="Speaker one" background="#00FF00"/>
<Label value="Speaker two" background="#12ad59"/>
</Labels>
<Audio name="audio" value="$audio" />
</View>About the labeling configuration
All labeling configurations must be wrapped in View tags.
Use the Labels control tag to allow annotators to highlight specific regions of the audio clip and apply a label:
<Labels name="label" toName="audio" zoom="true" hotkey="ctrl+enter">
<Label value="Speaker one" background="#00FF00"/>
<Label value="Speaker two" background="#12ad59"/>
</Labels>Use the Audio object tag to display a waveform of audio and allow annotators to change the speed of the audio playback:
<Audio name="audio" value="$audio" />