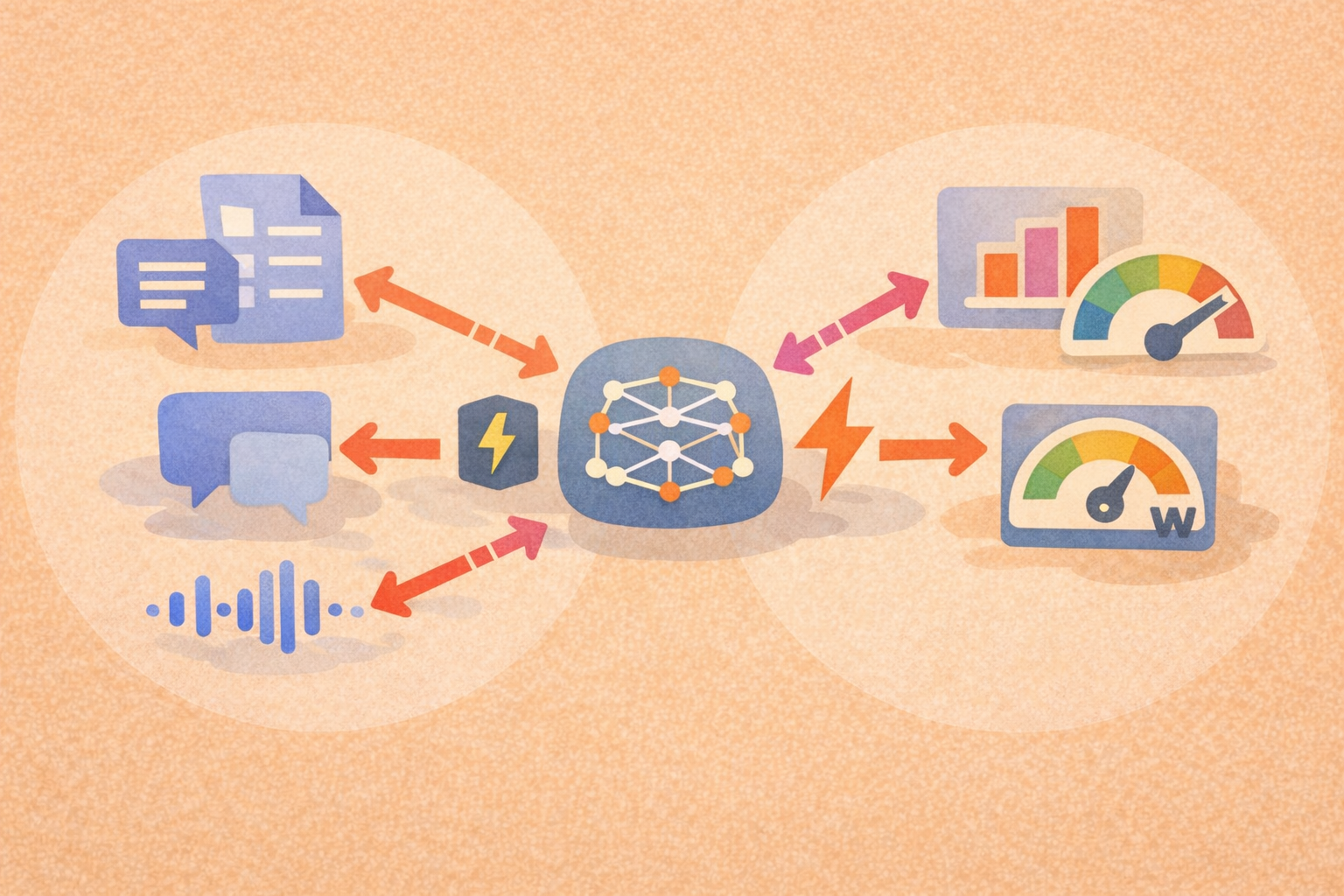
What are the differences between synthetic and real-world AI benchmarks?
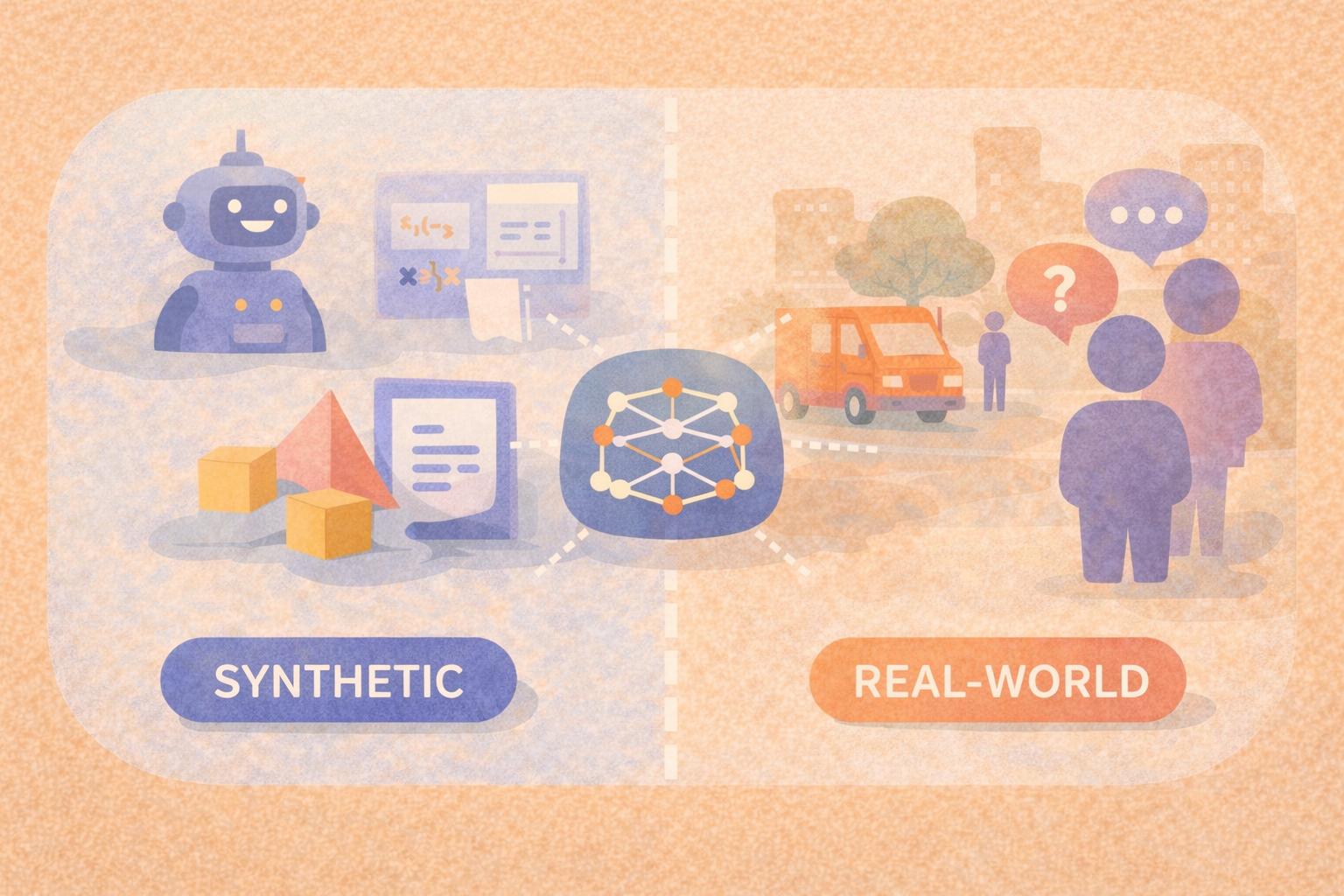
Synthetic and real-world AI benchmarks differ in how their data is created, what they measure well, and where they fall short. Synthetic benchmarks offer control and scalability, while real-world benchmarks capture messiness, bias, and edge cases that models encounter in production. Understanding the difference helps teams choose benchmarks that align with their goals and risks.
More details
How synthetic AI benchmarks are created
Synthetic benchmarks are built using generated or programmatically constructed data. This data may be produced by rules, simulations, or other models. Because the data is controlled, synthetic benchmarks make it easier to isolate specific capabilities, such as reasoning steps, formatting compliance, or robustness to noise.
One advantage of synthetic benchmarks is consistency. Inputs and expected outputs are clearly defined, which simplifies scoring and comparison across model versions. Synthetic data also scales easily, making it possible to create large evaluation sets without the cost and time required for manual data collection or labeling.
At the same time, synthetic benchmarks reflect the assumptions used to generate them. If those assumptions do not match real usage, results may overestimate how well a model performs once deployed. Synthetic benchmarks tend to reward models that learn the structure of the benchmark rather than the variability of the real world.
How real-world AI benchmarks are constructed
Real-world benchmarks are based on data collected from actual environments, users, or historical systems. This data includes inconsistencies, ambiguity, incomplete information, and bias that arise naturally in production settings.
Because real-world data reflects real behavior, these benchmarks are often better indicators of how a model will perform after deployment. They surface failure modes that synthetic benchmarks may miss, such as unexpected phrasing, domain drift, or long-tail edge cases.
Real-world benchmarks come with tradeoffs. Data can be harder to clean, label, and maintain. Updates may be required as usage patterns change, and scoring may involve subjective judgment rather than strict correctness. Comparability across versions can also be more difficult if the dataset evolves.
What each benchmark type measures best
Synthetic benchmarks excel at targeted testing. They are useful when teams want to stress specific skills, verify compliance with constraints, or run repeatable regression tests. These benchmarks are often easier to automate and interpret.
Real-world benchmarks excel at realism. They reveal how models behave under imperfect conditions and how performance varies across users, contexts, or domains. These benchmarks are better suited for assessing risk, reliability, and user experience.
Neither type fully replaces the other. Synthetic benchmarks can miss practical issues, while real-world benchmarks can be noisy and harder to reproduce.
How teams typically use both together
Many evaluation workflows use synthetic and real-world benchmarks in tandem. Synthetic benchmarks provide fast feedback during development and help catch regressions early. Real-world benchmarks are used to validate readiness, identify gaps, and monitor performance over time.
The key is alignment. Benchmarks should match the decisions they are meant to inform, whether that is comparing model versions, assessing safety, or deciding when a system is ready for broader use.
Frequently Asked Questions
Frequently Asked Quesions
Are synthetic benchmarks less trustworthy than real-world benchmarks?
They are trustworthy for the behaviors they are designed to test, but they may not reflect full production complexity.
Why do models sometimes score higher on synthetic benchmarks?
Synthetic data is often cleaner and more structured than real-world data, which reduces ambiguity and noise.
Can synthetic data introduce bias?
Yes. Synthetic benchmarks reflect the assumptions and choices made during data generation.
Should teams choose one type over the other?
Most teams benefit from using both, with each serving a different role in evaluation.
Related Content
-
Do you need a custom benchmark?
Learn why public AI leaderboards constantly fail enterprise deployments and how to scale a continuous evaluation maturity framework from proof-of-concept to production without wasting endless engineering hours.
-
Domain-specific vs. general benchmarks: What's the difference?
Learn the difference between domain-specific and general benchmarks. Understand how to measure artificial intelligence model performance effectively for your specific use case.
-

Where can I find AI benchmark scores for natural language processing models?
You can find NLP benchmark scores quickly on public leaderboards, but the comparisons only hold up when you verify versions, evaluation settings, and the exact model variant being scored.
-
Getting started with benchmark creation
A guide to creating effective benchmarks for evaluating machine learning models, covering data selection, annotation, and iteration.
-
How do benchmarks use ground truth data?
Learn how ground truth data serves as the foundation for evaluating machine learning models and tracking AI benchmark performance.
-

What are the most reliable AI benchmarks used in industry?
The core language, vision, speech, and system benchmarks that teams still rely on to compare models.
-

What services offer AI benchmark reports for enterprise decision-making?
A practical guide to the main sources of AI benchmark reports enterprises use to compare vendors, platforms, and model performance.
-

Which AI benchmark datasets are best for speech recognition tasks?
The best ASR benchmarks depend on your target audio conditions, so the most reliable approach is to pair a standard baseline with a dataset that reflects how people actually speak in your product.
-

What Benchmarks are Used to Evaluate AI fairness and Bias?
AI fairness and bias benchmarks help teams measure whether model performance or behavior changes across groups, identities, or contexts
-
Benchmarks are the measuring sticks of machine learning. They provide a way to evaluate models consistently, compare progress, and understand whether performance holds up in real-world conditions.
-
Static vs. dynamic benchmarks: What's the difference?
Learn the structural differences between static and dynamic AI evaluations, why purely dynamic tests ruin version control, and how to build a hybrid pipeline.
-

How often are AI benchmarks updated by major testing organizations
Benchmark results are time-bound, so the most reliable comparisons always include the benchmark version, evaluation method, and date.
-

What is the process for submitting AI models to benchmarking challenges?
Submitting an AI model to a benchmarking challenge is less about “upload the model” and more about proving your system can be evaluated fairly.
-

How to interpret AI benchmark results from third-party testing services?
Benchmark scores can be helpful signals, but only if you understand the dataset, scoring method, evaluation setup, and version behind the number.
-
How to choose an LLM benchmark
Public leaderboards are helpful for shortlisting models, but production demands custom evaluation. Learn how to choose an LLM benchmark for your team.
-
Benchmarks provide a common ground for evaluating machine learning models, but their usefulness depends on how well they reflect real-world goals. This guide explains what benchmarks are, when to rely on them, and where they fall short.
-

What are the differences between synthetic and real-world AI benchmarks?
This article breaks down how synthetic and real-world AI benchmarks differ and why teams need both to understand true model performance.