What are the differences between synthetic and real-world AI benchmarks?

When people talk about “benchmarks,” they are often mixing two different families of tests:
- Synthetic benchmarks, built from generated or highly controlled data
- Real-world benchmarks, built from organic, messy data that comes from actual users or environments
Understanding the gap between them helps you avoid over-trusting pretty charts.
Synthetic benchmarks
Synthetic benchmarks use data that is created by rules, templates, simulation, or another model. Examples include:
- Template-generated prompts that test a specific reasoning skill
- Synthetic question–answer pairs built from structured data
- Simulated environments where agents interact with scripted worlds
Teams reach for synthetic benchmarks because they are easier to scale and control. You can generate thousands of examples, keep the distribution stable over time, and target specific abilities or failure modes.
System-level suites such as MLPerf sit somewhat closer to this side: they define reference models and datasets to represent common workloads, then measure training or inference speed in standardized conditions.
The tradeoff is that synthetic tests often miss the nuance of real user behavior. A model might do well on clean, generated math questions but struggle with noisy, half-specified prompts in production.
Real-world benchmarks
Real-world benchmarks use data that originates in actual usage:
- Logs of real conversations
- Images from real devices and environments
- Naturally occurring documents such as forms, tickets, or reports
Datasets like ImageNet, COCO, and LibriSpeech started as large collections of natural images, scenes, and speech, then went through standardization and annotation to become widely used benchmarks.
Real-world benchmarks help you see:
- How a model handles noise, edge cases, and ambiguous inputs
- Whether performance holds up across different subpopulations or contexts
- Failure patterns that only appear when people use the system in unexpected ways
They are usually harder and more expensive to build and maintain, but they tell you much more about real reliability.
How modern evaluation frameworks bridge the two
Modern evaluation frameworks try to combine both worlds. HELM, for example, organizes evaluations into “scenarios” and metrics and covers a mix of synthetic-style tasks and more realistic language-use settings.
For product teams, a practical approach is:
- Use synthetic-style tests during development for fast iteration and regression checks.
- Before rollout, run evaluations on curated real-world data from your own domain (for example, production logs or representative user queries).
- Refresh those real-world samples periodically as usage patterns change.
Frequently Asked Questions
Frequently Asked Questions
Are synthetic benchmarks “bad”?
No. They are very useful, especially for stress tests and fine-grained analysis. The problem is only when synthetic scores are treated as the whole story instead of one slice of it.
Do synthetic benchmarks ever match real-world performance?
They can correlate, especially when they are carefully designed, but they almost always miss some failure modes that only appear with real users and data.
How should I combine synthetic and real-world tests?
A simple recipe:
- Use synthetic tasks during development to catch regressions quickly.
- Before major changes or launches, evaluate on a curated set of real production examples.
- Periodically update that real-world set so it reflects current behavior and edge cases.
Where do frameworks like HELM and MLPerf fit in?
They provide standardized, shared scenarios and metrics. HELM focuses on language-model behavior across many scenarios and metrics, while MLPerf focuses on system performance for training and inference. You still need your own domain-specific evaluations on top.
Related Content
-
Do you need a custom benchmark?
Learn why public AI leaderboards constantly fail enterprise deployments and how to scale a continuous evaluation maturity framework from proof-of-concept to production without wasting endless engineering hours.
-
Domain-specific vs. general benchmarks: What's the difference?
Learn the difference between domain-specific and general benchmarks. Understand how to measure artificial intelligence model performance effectively for your specific use case.
-

Where can I find AI benchmark scores for natural language processing models?
You can find NLP benchmark scores quickly on public leaderboards, but the comparisons only hold up when you verify versions, evaluation settings, and the exact model variant being scored.
-
Getting started with benchmark creation
A guide to creating effective benchmarks for evaluating machine learning models, covering data selection, annotation, and iteration.
-
How do benchmarks use ground truth data?
Learn how ground truth data serves as the foundation for evaluating machine learning models and tracking AI benchmark performance.
-

What are the most reliable AI benchmarks used in industry?
The core language, vision, speech, and system benchmarks that teams still rely on to compare models.
-

What services offer AI benchmark reports for enterprise decision-making?
A practical guide to the main sources of AI benchmark reports enterprises use to compare vendors, platforms, and model performance.
-

Which AI benchmark datasets are best for speech recognition tasks?
The best ASR benchmarks depend on your target audio conditions, so the most reliable approach is to pair a standard baseline with a dataset that reflects how people actually speak in your product.
-

What Benchmarks are Used to Evaluate AI fairness and Bias?
AI fairness and bias benchmarks help teams measure whether model performance or behavior changes across groups, identities, or contexts
-
Benchmarks are the measuring sticks of machine learning. They provide a way to evaluate models consistently, compare progress, and understand whether performance holds up in real-world conditions.
-
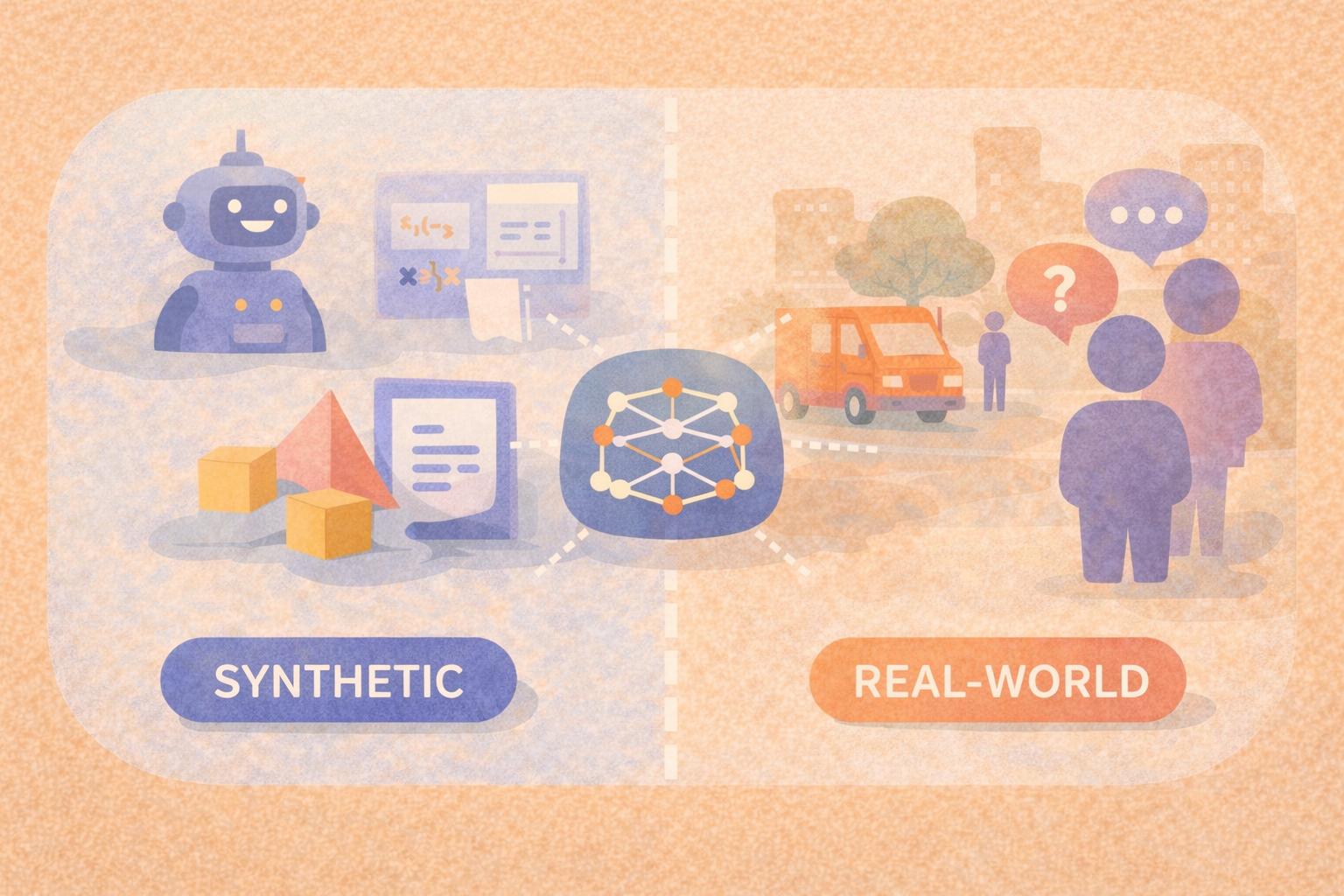
What are the differences between synthetic and real-world AI benchmarks?
Synthetic benchmarks offer control and scalability, while real-world benchmarks expose how AI systems behave under real conditions—and strong evaluation strategies rely on both.
-
Static vs. dynamic benchmarks: What's the difference?
Learn the structural differences between static and dynamic AI evaluations, why purely dynamic tests ruin version control, and how to build a hybrid pipeline.
-

How often are AI benchmarks updated by major testing organizations
Benchmark results are time-bound, so the most reliable comparisons always include the benchmark version, evaluation method, and date.
-

What is the process for submitting AI models to benchmarking challenges?
Submitting an AI model to a benchmarking challenge is less about “upload the model” and more about proving your system can be evaluated fairly.
-

How to interpret AI benchmark results from third-party testing services?
Benchmark scores can be helpful signals, but only if you understand the dataset, scoring method, evaluation setup, and version behind the number.
-
How to choose an LLM benchmark
Public leaderboards are helpful for shortlisting models, but production demands custom evaluation. Learn how to choose an LLM benchmark for your team.
-
Benchmarks provide a common ground for evaluating machine learning models, but their usefulness depends on how well they reflect real-world goals. This guide explains what benchmarks are, when to rely on them, and where they fall short.